






关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
文章地址:
https://arxiv.org/pdf/2402.14309
计算机视觉研究院专栏
Column of Computer Vision Institute
目标检测作为计算机视觉的一个关键领域,在准确性和鲁棒性方面已取得了显著进展。尽管有这些进步,但实际应用中仍然面临着一些显著挑战,主要是对小目标的检测不准确或漏检。此外,检测模型的大量参数和较高的计算需求,阻碍了它们在资源有限的设备上的部署。

PART/1
概述
目标检测作为计算机视觉的一个关键领域,在准确性和鲁棒性方面已取得了显著进展。尽管有这些进步,但实际应用中仍然面临着一些显著挑战,主要是对小目标的检测不准确或漏检。此外,检测模型的大量参数和较高的计算需求,阻碍了它们在资源有限的设备上的部署。在本文中,我们提出了 YOLO-TLA,这是一种基于 YOLOv5 的先进目标检测模型。我们首先在颈部网络金字塔架构中为小目标引入了一个额外的检测层,从而生成更大尺度的特征图,以识别小目标更精细的特征。此外,我们将 C3CrossCovn 模块集成到主干网络中。该模块采用滑动窗口特征提取方法,有效地减少了计算需求和参数数量,使模型更加紧凑。另外,我们在主干网络中融入了全局注意力机制。这种机制将通道信息与全局信息相结合,生成一个加权特征图。该特征图经过优化,能够突出感兴趣目标的属性,同时有效地忽略无关细节。与基线模型 YOLOv5s 相比,我们新开发的 YOLO-TLA 模型在 MS COCO 验证数据集上表现出了显著的改进,平均精度均值(mAP)在 IoU 阈值为 0.5 时提高了 4.6%,在 IoU 阈值范围为 0.5 到 0.95 时提高了 4%,同时模型规模保持紧凑,仅含 949 万个参数。将这些改进进一步应用到 YOLOv5m 模型上,增强后的版本在 mAP@0.5 和 mAP@0.5:0.95 方面分别提高了 1.7% 和 1.9%,参数总数为 2753 万个。这些结果验证了 YOLO-TLA 模型在小目标检测方面的高效性和有效性,能够在较少的参数和计算需求下实现较高的准确性。

PART/2
背景
近年来,深度学习的迅速发展在计算机视觉的各个方面都取得了重大突破,尤其是在目标检测领域。目标检测作为计算机视觉的一个关键方面,旨在识别和分类图像中的目标(例如行人、动物、车辆),是目标跟踪和目标分割等任务的基础要素。其在工业上的应用十分广泛,涵盖从缺陷检测到自动驾驶等领域 。此外,电子控制系统和飞机设计的发展凸显了基于无人机(UAV)的目标检测的重要性,无人机目标检测在农业、灾害管理和航空摄影等领域越来越普遍。无人机既可以通过无线电控制,也可以按照预编程的路线飞行。无人机配备了高分辨率摄像头,能够拍摄全面的数字图像,并借助轻量级模型在飞行过程中实现实时目标检测。目前,实现目标检测模型主要有两种方法:两阶段法和单阶段法。两阶段检测过程首先使用卷积神经网络(CNN)提取图像特征,然后在特征图上生成多个候选边界框(或区域)。接着,每个边界框会由额外的卷积层进行处理,以实现目标分类和边界框的优化。这包括识别目标类别、验证目标是否存在于边界框中,以及通过回归阶段来提高检测精度。最后通过非极大值抑制(NMS),过滤掉多余的边界框,从而确定最可靠、最准确的最终检测结果。相比之下,单阶段检测方法直接预测图像中目标的类别和位置,无需生成候选边界框。这种方法通常比两阶段法速度更快,计算量更小,非常适合对实时性要求较高的场景。
PART/3
新方法解读
动机与基线
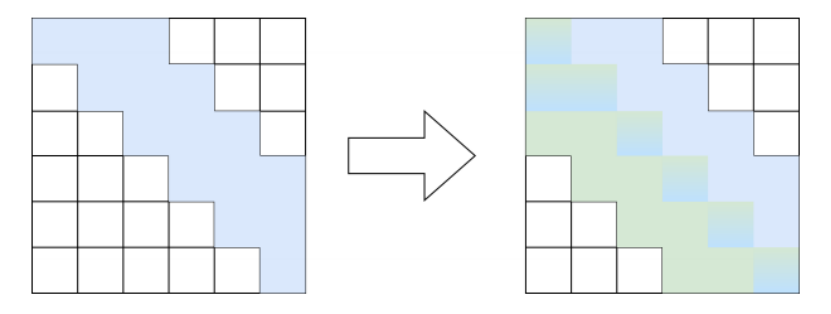
在本研究中,我们提出了 YOLO-TLA,这是一种基于 YOLOv5 的改进目标检测模型,重点关注小目标检测并降低模型复杂性,如下图所示。
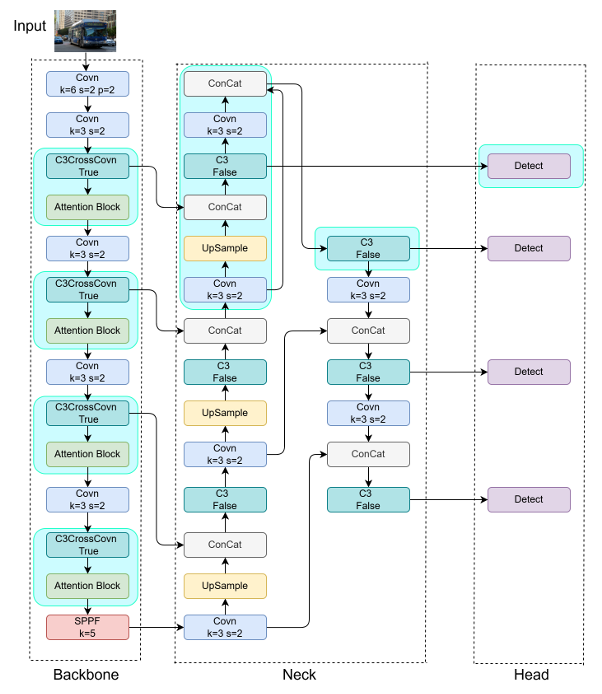
YOLOv5 有五个版本,分别为 YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l 和 YOLOv5x,按模型规模从小到大排列。每个版本都采用特定的配置设计,以满足不同规模的需求。该模型主要由三个部分组成:主干网络、颈部网络和头部网络。主干网络基于 CSPDarknet53 构建,由标准卷积层和额外的特征增强模块组成,负责提取物体的形状和颜色等几何纹理特征。为了丰富这些基础信息,颈部网络借鉴了特征金字塔网络(FPNet)和路径聚合网络(PANet)的思路,进一步将主干网络的特征图与更深入的语义信息相结合。这种结合产生了富含语义和几何信息的特征图。然后,这些增强后的特征图被输入到头部网络,由头部网络进行最终的检测和分类。
微小目标检测层
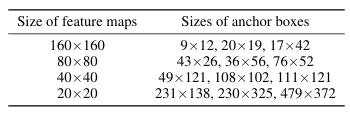
在 MS COCO 数据集中,目标是根据大小进行分类的:小目标小于 32×32 像素,中等目标在 32×32 到 96×96 像素之间,大目标则超过 96×96 像素。为了增强我们模型对小目标的检测能力,我们调整了特征图和锚框的大小。利用 k 均值聚类算法,我们重新校准了预设锚框的尺寸范围,并引入了一个微小目标检测层,从而创建了 YOLOv5s-Tiny 模型。具体来说,我们在 YOLOv5s 的颈部网络中进行上采样,生成一个尺寸为 160×160、通道数为 128 的特征图,然后将其与主干网络的第三层输出相结合,使两者在通道数和尺寸上匹配。这个组合后的特征图与其他检测层的输出一起,在头部网络中进行分类和检测处理。我们的颈部网络生成了几个不同尺度的特征图,每个特征图对应不同的锚框尺寸。这使得在较大的特征图上可以检测较小的目标,在较小的特征图上可以检测较大的目标,从而增强了图像中目标的表示能力。特征图尺寸与锚框尺寸之间的关系详见下表。
轻量级卷积模块
为了通过减少参数数量和计算需求来简化 YOLOv5 模型,本研究探索集成两个模块:C3Chost 和 C3CrossCovn。我们旨在评估将这些模块插入主干网络的不同位置时所产生的影响。这种比较重点关注每个模块的放置位置如何影响模型的性能和复杂性,目标是在不影响模型性能的前提下简化网络架构。
重新审视 C3 模块
C3 模块是 YOLOv5 的关键组成部分,如下图所示。
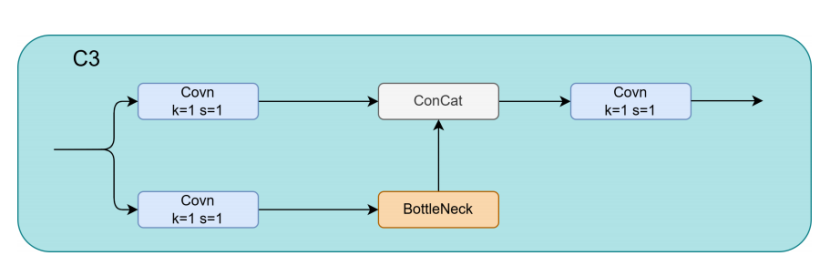
它由三个标准卷积层组成,每个卷积层的内核大小为 1×1,步长为 1,并且包含几个堆叠的瓶颈(BottleNeck )模块。该模块的架构在宽度和深度上会根据模型大小而有所不同,这由预定义的参数控制。C3 模块采用了类似于瓶颈 CSP(BottleNeckCSP)的残差结构。它以两种方式处理输入特征图:一种是通过双分支方法,其中一个分支使用两个标准卷积层,另一个分支输出原始特征图,随后将两个分支的输出进行拼接;另一种是跳过残差路径,在标准卷积之后直接输出特征图。C3 中的瓶颈模块以其强大的特征提取能力以及在应对梯度消失和梯度爆炸问题方面的作用而闻名。
C3Ghost 模块
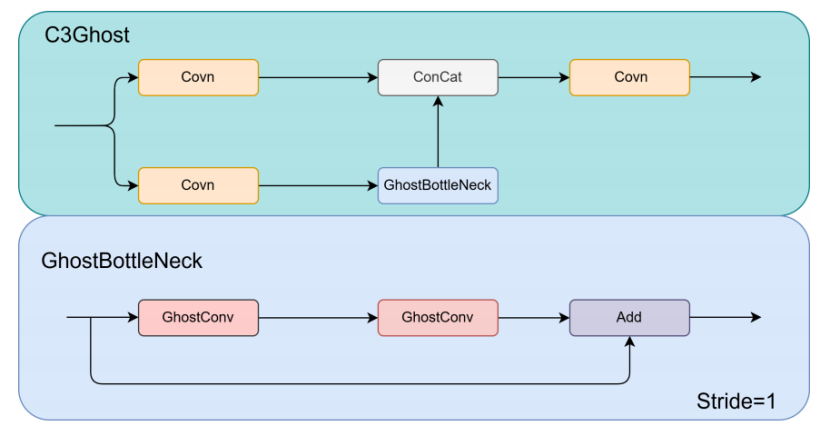
标准卷积模块通常由一个常规卷积层以及批量归一化和激活函数组成,这种模块往往会生成大量相似的特征图,从而导致较高的计算需求和资源消耗。为了解决这个问题,幽灵卷积(GhostCovn)采用了两步法。首先,它使用一个内核尺寸较小的标准卷积来生成通道数较少的特征图。随后,使用深度卷积(DepConv)来生成第一步中未生成的额外特征图。然后将这两个阶段得到的特征图进行组合,从而得到一个与标准卷积层生成的特征图类似的最终特征图,但计算量和参数数量都大大减少。
在我们提出的 C3Ghost 模块中,幽灵卷积(GhostCovn)与幽灵瓶颈(GhostBottleNeck)模块结合使用,幽灵瓶颈模块包含幽灵卷积和深度卷积(DepConv)模块,并且具有残差结构。幽灵瓶颈模块有两个分支:第一个分支是通过使用卷积核为 1×1、步长为 1 的幽灵卷积来处理输入特征图,然后将得到的特征图与原始特征图相加。第二个分支在两个幽灵卷积模块之间引入了一个卷积核为 3×3、步长为 2 的中间深度卷积模块。残差路径先经过一个类似的深度卷积模块,然后是一个步长为 1 的标准 1×1 卷积。C3Ghost 模块的整体结构与 C3 模块类似,不过它用幽灵瓶颈模块取代了瓶颈 CSP(BottleNeckCSP)模块。其总体架构如下图所示。
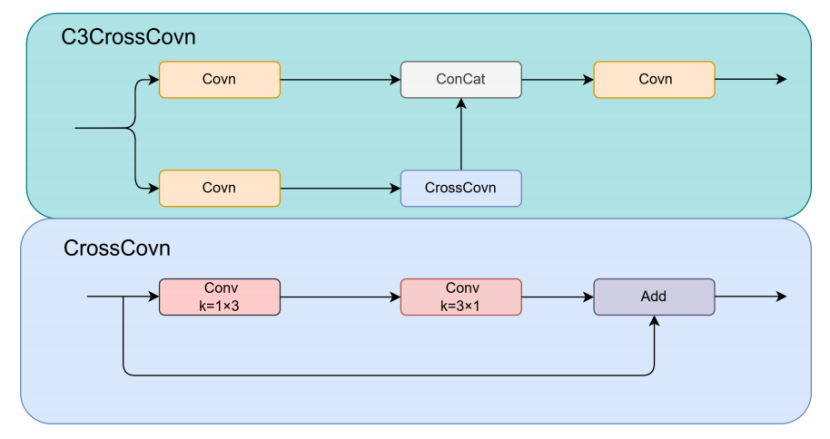
C3CrossCovn 模块
虽然幽灵卷积显著简化了 C3 模块,但它却在不经意间导致了沿通道方向的代表性信息丢失,进而影响了模型的准确性。为了缓解这一问题,我们采用了交叉卷积(CrossCovn)。交叉卷积由两个标准卷积层组成,它们以交叉模式作用于特征图上。它不同于传统的 k×k 滑动窗口卷积,第一层使用 1×k 的卷积核,水平步长为 1,垂直步长为 s,第二层使用 k×1 的卷积核,两个维度上的步长均为 s。交叉卷积的示意图如下图所示。
为了评估标准卷积和交叉卷积在参数数量和计算负载方面的差异,我们建立了一个比较框架。在进行这一分析时,假设存在一个尺寸为 H×H×C 的方形输入图像。卷积操作使用 k×k 的卷积核大小,卷积核的数量等于通道数 C,并且在图像边缘添加了填充 p。公式 1 确定了通过标准卷积层进行处理所需的浮点计算量和参数数量,
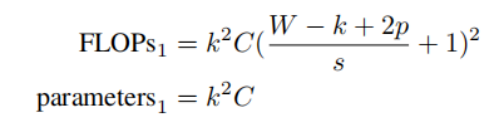
为了确定交叉卷积(CrossCovn)对一张图像进行单次操作所需的计算量,我们做如下假设:交叉卷积包含C个双卷积核,第一个卷积核的尺寸为1×k,第二个卷积核的尺寸为k×1,步长为s。公式 2 详细说明了在交叉卷积的这些设置下,其计算负载和参数数量的具体计算方法。
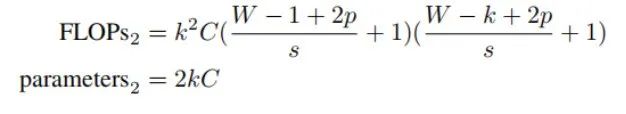
在 MS COCO 数据集中,所有图像均为 RGB 格式,因此我们使用三个图像通道(C=3)。为了确保有足够大的感受野,我们将k设置为3,将s设置为1。在这些条件下,很明显,标准卷积需要更多的计算量,并且其参数数量大约是交叉卷积(CrossCovn)的1.5倍。
尽管交叉卷积需要对单个特征图进行两次条纹核卷积操作,但它比标准卷积能够实现更精细的特征提取,并获得更丰富的特征信息。这种改进不仅提高了检测精度,
但也显著降低了计算需求和参数数量,使其成为实现模型轻量化的最佳方案。C3CrossCovn 模块的概述如下图所示。
全局注意力机制
为了解决计算机视觉中目标检测所面临的难题,即目标常常处于复杂的背景和干扰物之中,我们在主干网络的多个位置采用了全局注意力机制(GAM)。全局注意力机制有助于模型更加关注感兴趣的目标,并减少干扰,从而提高模型的准确性和鲁棒性。像 SENet 和 CA 这样的经典注意力机制存在一定的局限性。SENet 通过挤压和激励步骤获取通道相关性权重,但忽略了空间信息。而采用位置编码的 CA 可能会过度强调位置细节,由于缺乏全局相关性分析,有可能导致过拟合。
全局注意力机制主要分为两个部分:通道注意力和空间注意力。这种机制既关注通道特征,又关注图像的全局方面,利用全局信息对输入特征图进行加权,以提高准确性和鲁棒性。在结构上与 CBAM 类似,全局注意力机制先处理通道注意力,再处理空间注意力,同时还引入了残差结构,以保留原始图像的特征信息。在通道注意力中,特征图通过置换操作在通道数C和宽度W之间进行维度交换,然后经过一个包含两个全连接层和一个 ReLU 激活函数的多层感知器(MLP),最后通过一个 Sigmoid 激活函数。对于空间注意力,全局注意力机制没有采用池化方法,而是使用了两个带有 ReLU 激活函数的7×7标准卷积。全局注意力机制的详细流程如下图所示。
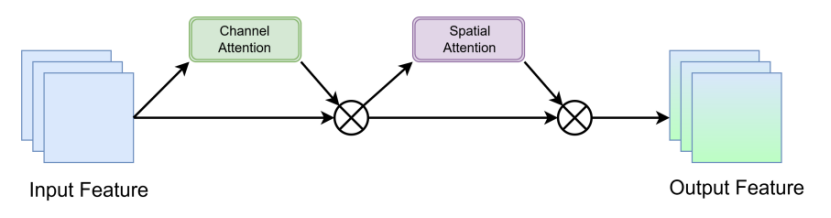
检测流程
在 YOLO-TLA 中,为了处理不同大小的输入图像,在数据增强过程中,所有用于检测的图像都被标准化为640×640×3像素,通常为 RGB 图像。主干网络提取不同尺度的特征图:320×320×64、160×160×128、80×80×256、40×40×512和20×20×1024。该网络的输出是一个通道数为1024的20×20特征图。
颈部网络结合了特征金字塔网络(FPN),通过融合相同尺度的特征图并逐步将它们上采样到160×160且通道数为128,从而加深特征提取。颈部网络中的路径聚合网络(PAN)进一步将特征图下采样到20×20且通道数为1024,继续进行特征融合过程。颈部网络生成四个尺度的特征图(160×160×128、80×80×256、40×40×512和20×20×1024)用于检测。
头部网络根据这些特征图的大小选择锚框,使用从训练数据集中真实标注的聚类得到的锚框尺寸,然后对目标进行分类,并对锚框进行回归以确定目标的位置和大小。
PART/4
实验及可视化

Detection results of YOLOv5s and YOLOv5s-Tiny

Output heatmaps of YOLOv5s neck network
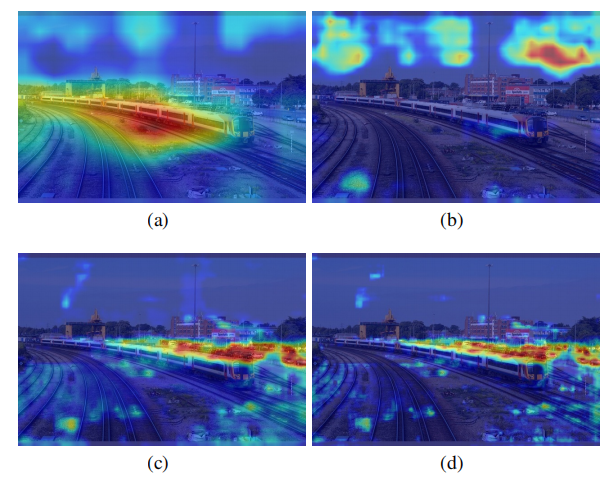
Output heatmaps of YOLOv5s-Tiny neck network
PART/5
总结
本研究针对目标检测领域中普遍存在的挑战,提出了一种全新的方法 ——YOLO-TLA。与基线方法 YOLOv5 相比,该方法展现出了更出色的检测性能,尤其是在精确识别小目标方面表现突出。
YOLO-TLA 对 YOLOv5 进行了改进,在其颈部网络中集成了一个小目标检测层,并引入了全局注意力机制以提高检测精度。为了在增强检测能力的同时兼顾模型效率,采用了一种轻量化策略,在主干网络中引入了 C3CrossCovn 模块,以降低模型的复杂度。实验结果证实,这一策略不仅降低了模型复杂度,还提高了检测精度。
此外,我们还成功地将这些改进应用于更大规模的 YOLOv5m 模型,创建了 YOLO-TLAm 模型,该模型在准确性和稳定性方面均优于 YOLOv5m。这些结果验证了所提出的改进方法对于更大规模的模型同样有效。
有相关需求的你可以联系我们!


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











