







OpenAI 的发布会可谓AI 届春晚,ChatGPT 迎来王炸级更新。
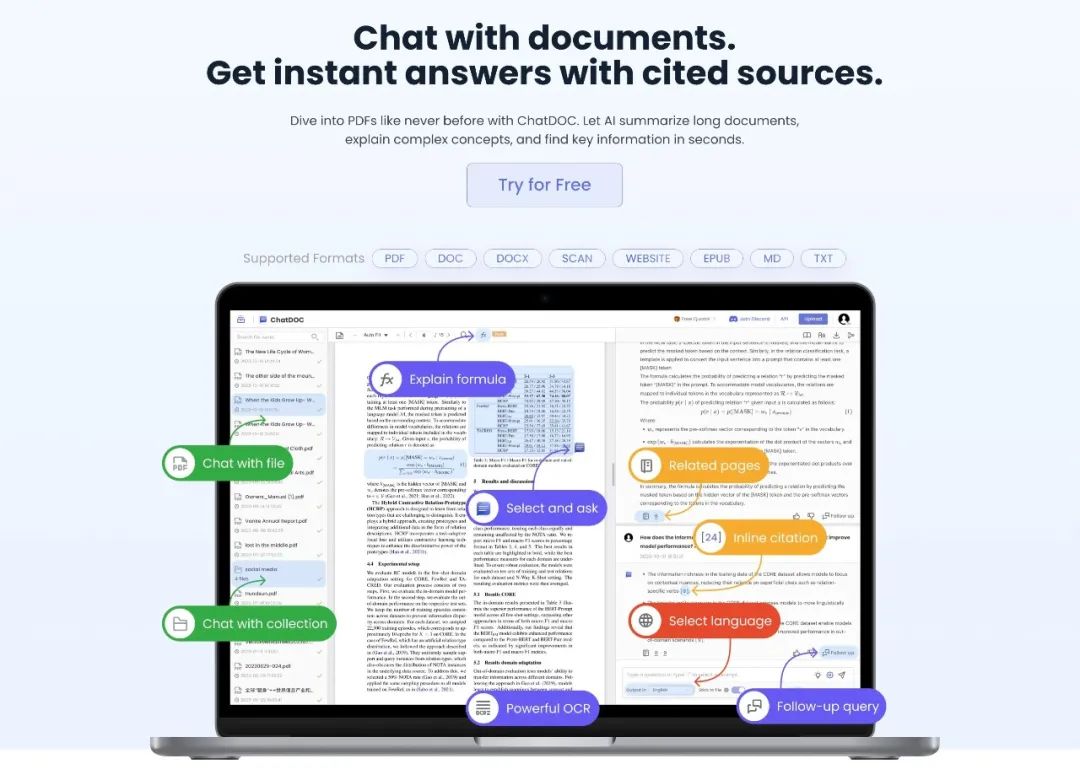
对于普通用户来说,最重要的更新莫过于 GPTs —— 普通用户也可以自定义专属 GPT 助手了。这一功能已经在 11 月 10 日向 GPT4 用户全量开放。

你可以通过上传文档来补充它的专属知识,给它配置浏览网页、DALLE 图片生成、代码解释的能力,以及让其通过插件或网站获取特定信息。
在 API 层面,GPT-4 Turbo 发布了 6 项能力增强:上下文窗口提升、更好的模型控制、更新的知识、多模态能力、开放 GPT-4 微调、调用速率限制提升。
其中,上下文窗口提高到 128k,相当于一次能输入 300 页的书籍。
每当 GPT 发布新功能时,都会出现一种声音:类似功能的 AI 产品是不是没有市场了?
这一次,大家普遍认为,受到冲击的是 AI 问答产品,尤其是基于文档的。此前 GPT 无法与 PDF 直接交互,ChatDOC 等产品解决了一大痛点需求。
如今 GPT 也可以处理 PDF 了,它们还有业务空间吗?答案是肯定的。
接下来,本文会讲一讲,在 OpenAI 的穷追猛打下,文档问答 AI 的机会在哪里:
理解复杂页面、复杂表格
更好的Embedding&知识召回
深入业务场景,解决专业问题
1
ChatGPT:文字优等生,文档差生
新版的 ChatGPT 现在也能处理文件了,但显然不如处理文本内容那样得心应手。Twitter 网友表示:虽然现在 GPT4 能处理文件了,但是用户体验还是比不上 ChatDOC。
和文档交互,最常见的场景,一是基于产品手册回答用户问题,二是基于财报研报等专业文档给出辅助分析。
我们选取了《特斯拉使用手册》以及《西磁科技Q3财报》两份公开文档,来对 ChatGPT、GPTs、ChatDOC 进行粗略的可用性测试。
1.1
特斯拉使用手册
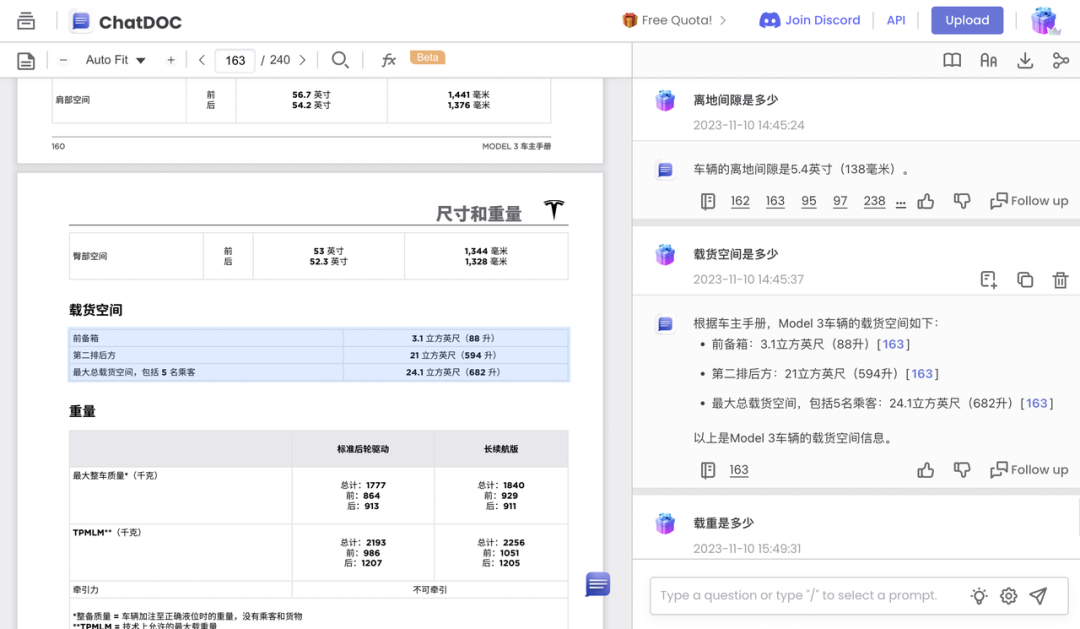
首先,我们试图提出一个细节问题:离地间隙是多少?
ChatGPT 告诉我:抱歉,我分析不出来这份文件,它的格式可能不兼容。

使用新功能 GPTs,我们定制一个 Tesla Expert Bot,在知识中上传了中文、英文两份手册。
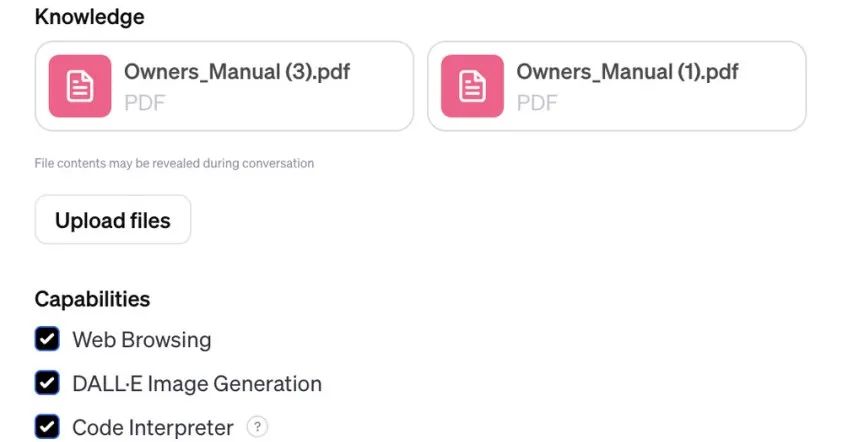
然而我们自定义的 Telsa Expert,也没能从手册中找到具体的信息,而是建议我联系 Tesla 代理商获取信息。

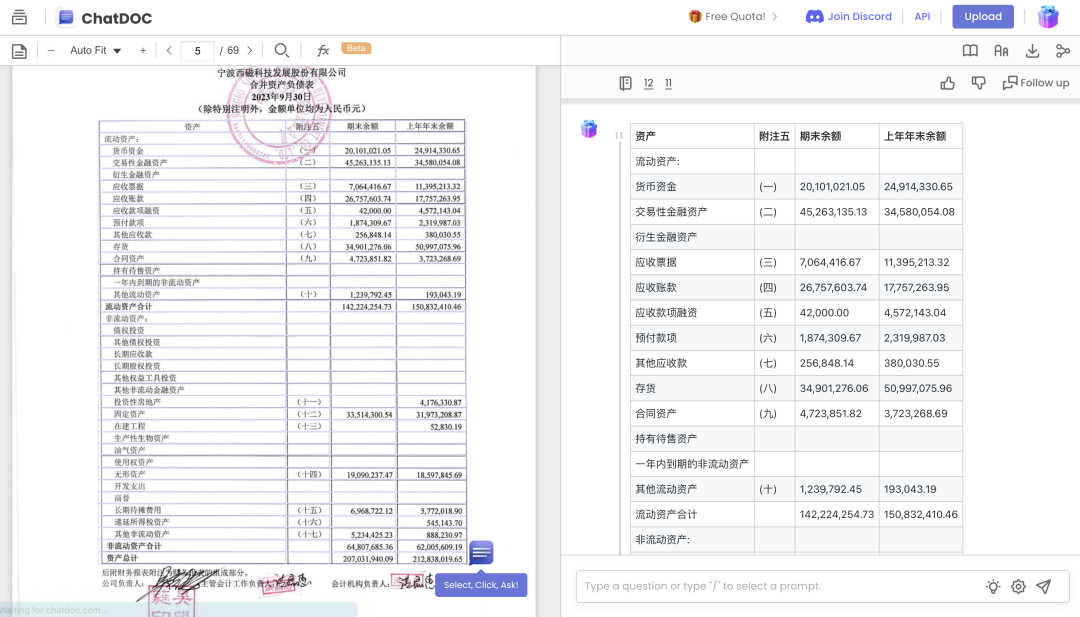
难道手册里真的没有提及吗?将同样的文件上传到 ChatDOC,它不仅给出了正确的回答:5.4 英寸,还给出了原文出处的表格。
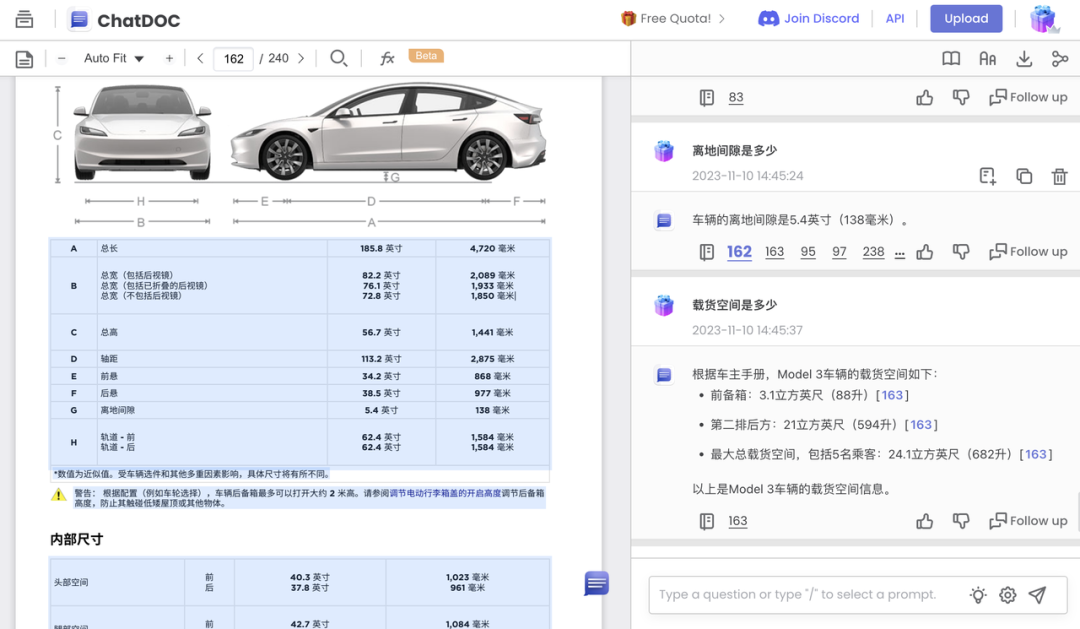
我们再来尝试一个问题:载货空间是多少?
ChatGPT 依然表示无法读取文件。

GPTs,我们定制的Telsa Expert 成功回答了这个问题。但还是 GPT 的老毛病:它自信满满地给出了回答,但作为来提问的用户,我要如何知道回答是否正确呢?

ChatDOC 给出了满分回答:答案正确、包含出处、分点作答。
1.2
西磁科技 Q3 财报
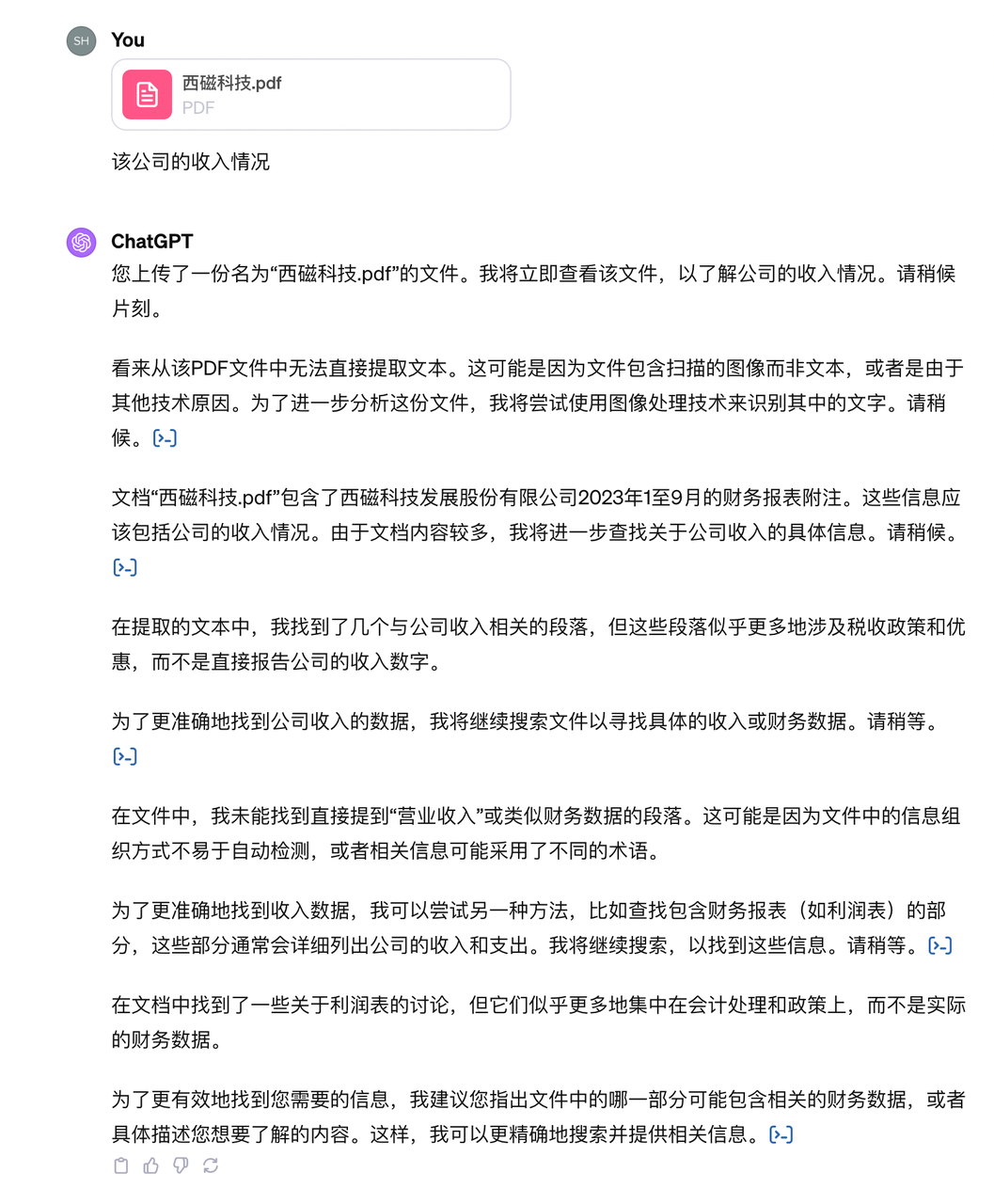
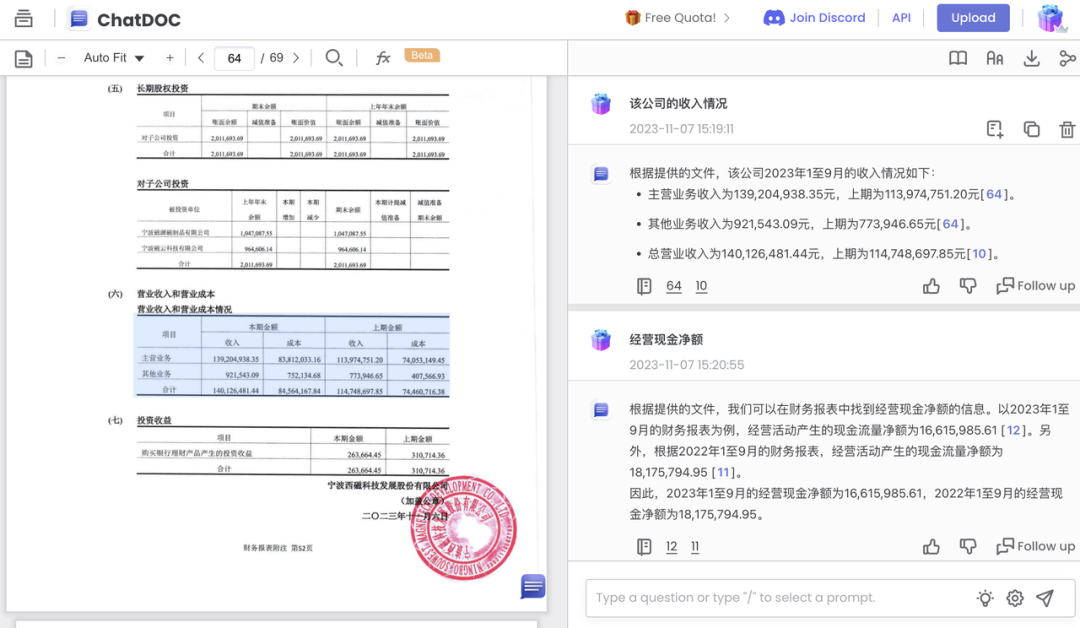
我们再来试试财报的效果,这是一份扫描件。上传财报后,我们提出问题:该公司的收入情况?
ChatGPT 虽然步步有回音,说了一大堆来缓解等待的焦虑,但没能给出答案。
用 GPTs 搭建的 Financial Expert Bot 给出了回答——只是依然没有出处。检查后我们发现,所有数据全部错误。
我们猜测,ChatGPT 暂时不支持读取扫描件,而自定义 GPTs 很可能是根据文档之外的信源,或是训练阶段见过的数据回答了这一问题。

而 ChatDOC 依然稳定发挥,给出了正确答案、原文出处。
2
明明信息就在文档中,为什么 GPT 答不出来?
我们点开 Error analyzing,看看到底是哪里出了问题。在 GPT 给出的代码中,我们发现,它使用的 PDF 解析器正是 PyPDF2。这也是 Langchain 推荐的首个 PDF 解析器。
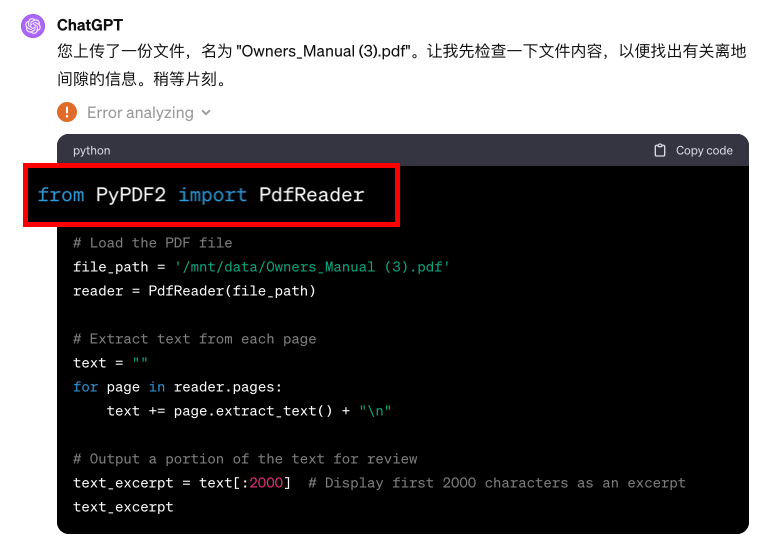
然而,我们此前对 PyPDF2 进行过测试,发现它仅能够解析出所有文字,无段落信息,也无表格信息。
举个例子,当我们给到 PyPDF2 如下页面作为输入:

PyPDF2 的输出是这样的:

它仅仅是将里面的文字提取出来,而丢失了文档页面原来的分栏结构、表格的行列关系,信息是错乱的。
如果我们询问的信息隐藏在表格中,或者较长文档片段中的一小部分里,ChatGPT 就无法拿到这一信息。
而特斯拉车主手册恰恰是一个多栏排版、包含诸多表格的文件。

显然,ChatDOC 所使用的庖丁科技自研 PDF 解析器效果更好,不仅能够理解复杂排版,对表格的理解也相当准确:它可以将表格信息一字不差地提取出来。
此外,ChatGPT 暂不支持扫描件,而金融行业的财报、研报文件,约 15% 为扫描件。ChatDOC 所采用的高精度 OCR,可以极大程度减少印章、模糊扫描带来的干扰,保证信息提取的准确。

由此可见,跟 ChatDOC 这个「文档问答」的专业选手相比,ChatGPT 胜在功能丰富,败在不精专:
不能处理扫描件
不能处理排版复杂的文档
不能理解表格
无法展示原文出处,不便于信息的核实
数据就是新时代的石油,而 ChatDOC 能从文档中开采出更多高价值数据。
3
更长的上下文窗口 ≠ 更高的准确率
我们在之前的文章中介绍过,为了给大模型增加特定领域的知识储备,一种务实的方法是检索增强(Retrieval-Augmented LLM):先将长篇文档进行切块、计算向量并存储,再根据用户的提问,召回最相关的文档片段,并加入提示词(Prompt)中,再给到大模型进行回答。
之所以需要「检索增强」,是因为大模型每一轮的问答都有长度限制。比如 GPT-3.5,此前输入和输出加起来不能超过 4096 token,大概相当于 3000 多字。
此次 GPT-4 API 更新后,上下文窗口提高到 128k,相当于一次能输入 300 页的书籍。
这是否意味着,现在大模型是否可以直接理解长篇文档,无需检索增强,直接给出高质量回答呢?
恐怕还不行。有用户表示,当 PDF 达到千页以上,GPT 给出的回答有 80% 的概率出错。
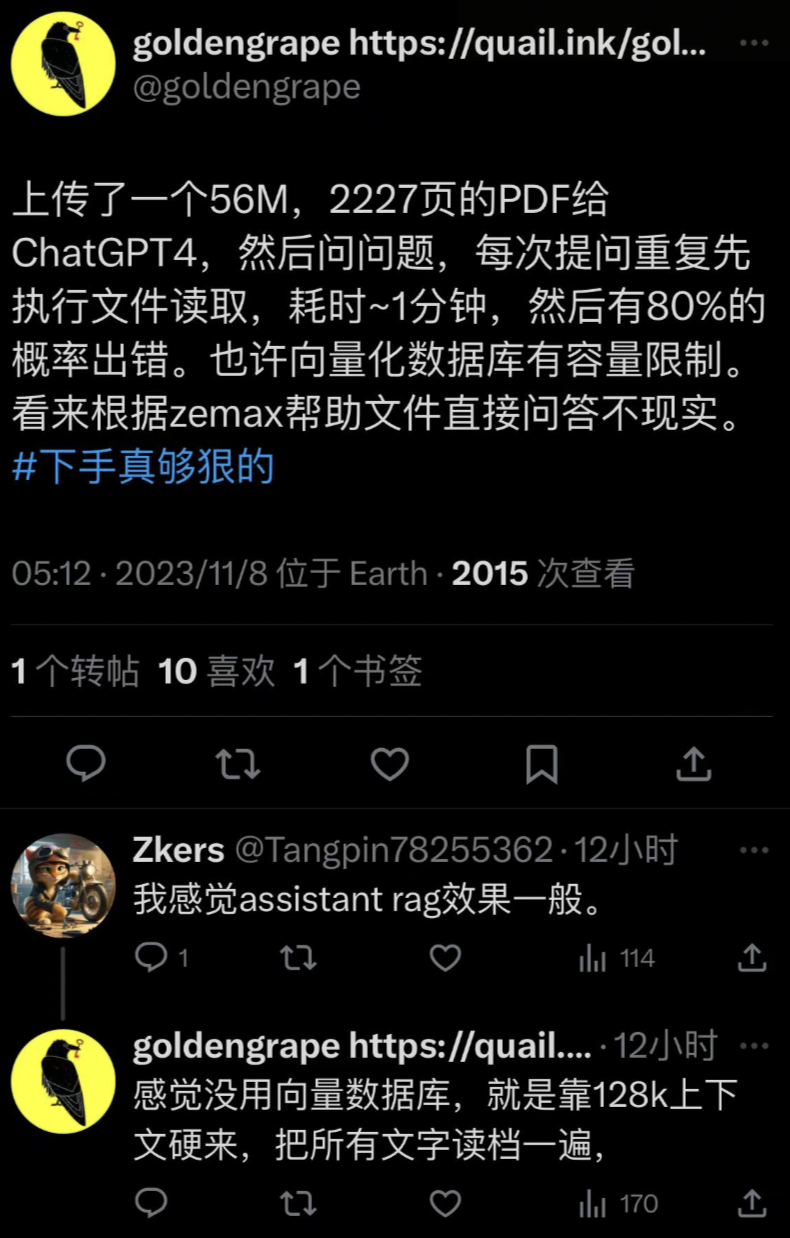
网友 @Greg Kamradt 进行了更深入的测试,他称之为「大海捞针」测试(needle in a haystack)。
他使用 Paul Graham 的散文制作了不同长度的测试文本,在其中随机插入「在旧金山最好的事情,是在阳光明媚的日子,坐在多洛雷斯公园吃一个三明治。」这句话,并让 GPT 回答「在旧金山最好的事情是什么?」
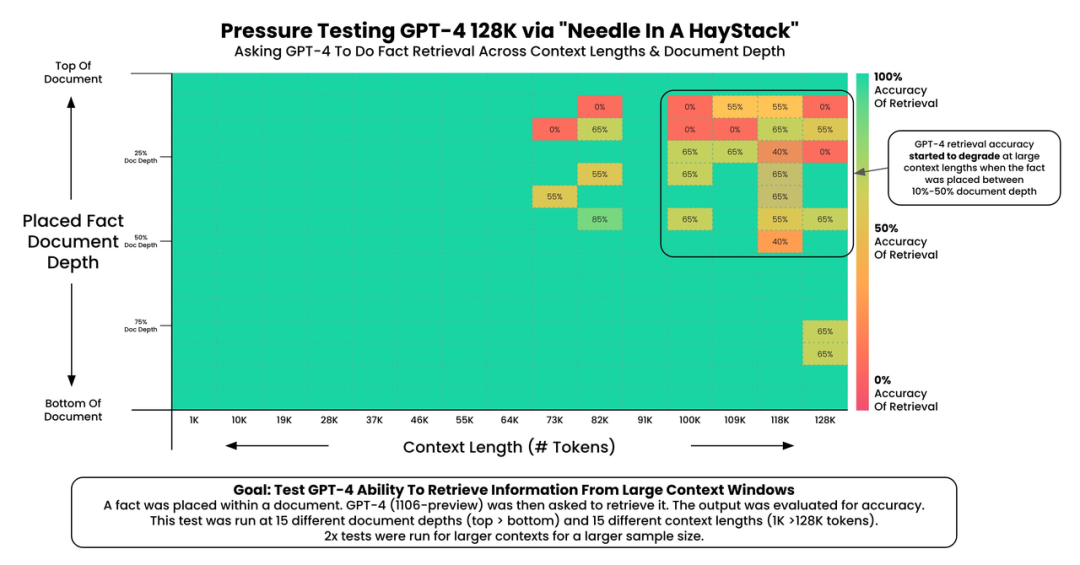
测试后,他发现:
GPT-4 的召回性能,在文本大于 73K token 时开始下降
当要召回的事实内容位于文档 7%-50% 的位置时,召回性能较差
如果事实内容位于文档开头,则无论上下文长度如何,都会调用该事实
如图所示,文本长度越长,GPT 找到信息的性能就越差。因此,检索增强仍然是必要的。
ChatDOC 使用的正是检索增强的方法,并在召回上持续优化,最多支持 3000 页文件的问答。
此外,ChatDOC 所使用的 Embedding 模型采用了更高维的 Embedding 向量,可以存储更丰富的细节信息。特别是当正确答案信息散落在表格中时,ChatDOC 的召回结果更好。
对 Embedding 进行优化,是 ChatDOC 的另一个竞争力所在。
4
找到应用场景,落地行业
最后,如果不结合具体场景,AI 的能力再强,也始终是个玩具,而算不上工具。
「AI 的下一个机会在应用层」,在基础模型能力之外,能否真正帮用户解决问题,是每一款 AI 应用都要思考的问题。
同样是文档问答,结合场景,就能打造更深厚的壁垒。
ChatDOC 背后的公司庖丁科技长期服务于金融行业的信息化建设。基于多年的行业知识积累,ChatDOC 已经针对投行法律法规、公司信息披露监管、股权激励等特定场景的知识库问答,进行了专门的优化。除了面向 C 端用户的版本,B 端专业版本也已经在合作落地中。
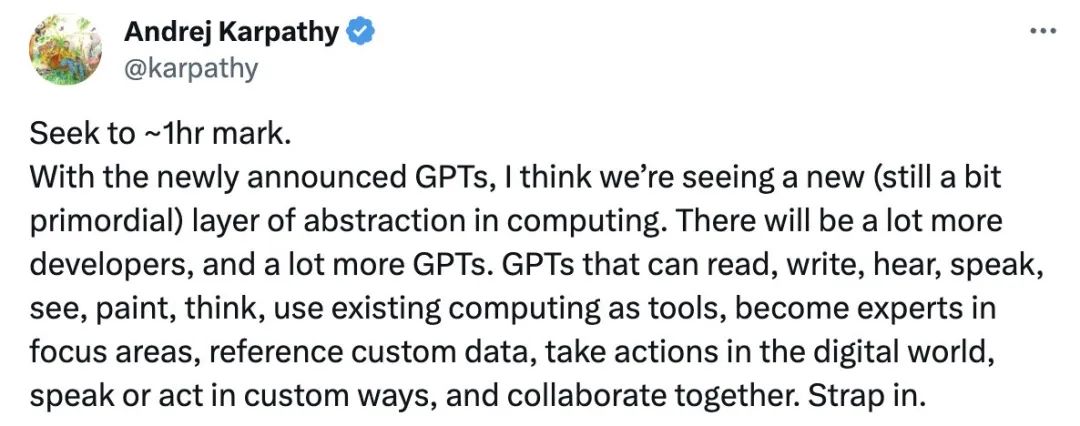
OpenAI 联合创始人 Andrej Karpathy 曾表示,在构建 AI Agents 时,普通人、创业者、极客,和 OpenAI 处于平等竞争的状态,甚至更有优势。
他说,每当OpenAI团队读到新的 AI Agents 论文时,团队成员都非常感兴趣,觉得非常酷:「因为我们并没有花5年时间在上面,我们并不比你们更多掌握什么。」
因此,找准场景、挖掘需求,在数据层、工程层发力,是 ChatDOC 的第三个竞争力。
此次更新,我们不难发现,除了技术之外,OpenAI 也越来越重视产品体验和生态构建。
Andrej Karpathy 表示,未来将会有更多的开发者、更多的 GPT。GPT 可以读、写、听、说、看、画、思考,成为重点领域的专家,参考自定义数据,以自定义方式说话或行动。
ChatDOC 也会是众多 AI 智能应用中的一股力量,帮助大模型更好地理解文档、开采数据、召回知识、落地行业。
















 2456
2456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









