






语言理解和生成是 LLM 的强项,问答类产品随之成为首批涌现的 AI Native 应用:和视频/音频/文档/网页等各类富格式文件聊天,快速提取信息。
其中,「文档」是信息浓度更高的知识载体,因此 AI 问答也最刚需。
利用各种 API,搭建一个「文档问答」类产品,听起来并不难,市面上也有很多同类产品。但体验后就会发现:不同产品之间的答案质量差异巨大,且大多数都不尽人意。
明明都是基于 ChatGPT 等大模型开发的,为什么存在如此大的效果差异?如何让 LLM 在某一知识细分领域给出可靠的回答呢?
技术的关键在于,减少每个步骤的信息损耗:
-
减轻模型「幻觉」
-
减少文档信息提取的误差
-
减少 Embedding 检索的错配
检索增强,减轻模型幻觉
第一步,是要减轻大模型的「幻觉」。毕竟,回答专业领域问题不是儿戏,胡编乱造是不能容忍的。
因此,我们需要给大模型增加特定领域的知识储备。目前,有两种技术方案:
-
模型微调(Fine-Tuned LLM):类似于「封闭培训+闭卷考试」,基于行业数据进行模型微调,在训练数据集中加入专业知识。大模型每次问答时无需再次检索。
-
检索增强(Retrieval-Augmented LLM):让模型参加「开卷考试」,结合向量数据库检索,将相关知识和问题一起构造成 Prompt,再给到大模型,让其边查边答。
检索增强性价比更高,且适用场景更加广泛。它无需经过高成本的训练,还可以实现原文档溯源的功能。虽然需要在提示语中加入相关知识片段,消耗的 token 更多,导致单次预测成本较高,但与模型微调高昂的训练成本比起来显得微不足道。
在第二种方法中,检索的质量决定了回答的质量。而检索的实现,需要以下几个步骤:
-
将各类文档(包括.doc, .pdf, Markdown, 扫描件等等)转成长文本
-
将长文本分割成文本块
-
将文本块进行向量化,并将「向量-文本块」的键值对存入向量数据库
-
每次提问时,将问题向量化,匹配相关的文本块
其中,每一步骤都会产生信息损耗。这些损耗相乘,就会造成 AI 回答效果的巨大差异。
前两个步骤,需要用到 PDF Parser;后两个步骤,需要用到 Embedding 模型。
因此,PDF Parser、Embedding 模型的质量决定了文档知识问答的质量。
PDF Parser,让机器读懂文档
PDF Parser 是计算机阅读 PDF 文档的感知系统。
对人类来说,所有的 PDF 看起来都一样,双击就能打开查看。当我们的目光扫过页面时,一个个文字落入我们的视网膜中,被分解成无数个信息片段,而后存进我们的大脑里。
而计算机没有眼睛,我们需要直接给它「信息片段」。对于计算机来说,文档可以分为两类:
-
Tagged Document:保留了文档的语义结构信息,机器可读取,如.docx, HTML 文档。
-
Untagged Document:存储的只是图像(或字符位置),计算机无法获得段落等结构化信息,如 PDF 文档。
专业领域的文档以 Untagged PDF文档为主,因此需要利用 PDF Parser 首先从 Untagged PDF 中提取文字、段落内容,让它变得机器可读。可以说,没有 PDF Parser,就无法解锁文档中的信息,计算机也无从检索和参考。
那什么是好的 PDF Parser?
-
有逻辑:能读懂文档的结构,并分为段落、表格、图片等不同类型的内容要素,分割后的文本块是完整独立的信息单元。
-
准确:能准确提取页面中的文字、表格等不同内容的信息;
-
皮实:各类模糊的/歪斜的/无框线的/印章水印遮挡,都不影响识别结果;
市面上的 PDF Parser,分割文本的方法有两种:基于特定规则的,以及基于深度学习模型。
基于特定规则
我们先来看基于特定规则的方法,最近很火的开发框架 LangChain 中推荐的 PDF Parser 就属于此类。
PyPDF 是 LangChain 里推荐的第一个 PDF 解析器。它仅能够解析出所有文字,无段落信息,也无表格信息。
举个例子,当我们给到它如下页面作为输入:
它的输出是这样的:

由于没有段落等信息,你需要通过控制字符的数量、字符块之间的重叠、每个块的起始位置,来控制文本块切分的大小和质量。这样的方式简单粗暴,但其问题在于,模型没有真地读懂文档,而只是武断地按长度来切分,会把相同知识单元的信息打乱拆散,给后续检索和利用造成困难。
基于深度学习模型
深度学习模型,可以更好地完成页面分析、表格识别等文档理解任务。
百度飞桨研发的 PPStructure、庖丁科技研发的 PDFlux,都是基于深度学习模型的 PDF 解析器。
它们都能够划分文字、标题、表格、图片等不同区域,并支持对表格区域进行结构化识别,抽取关键信息。但两者的效果也有差异,相较之下,庖丁科技的 PDFlux 识别精度更好。
同样的页面,PDFlux 对段落、表格的划分识别毫厘不差:
PPStructure 则在第二个页面漏掉了段首的几个字符,在第三个页面漏掉了图表标题的前几个字符,以及整段注释:
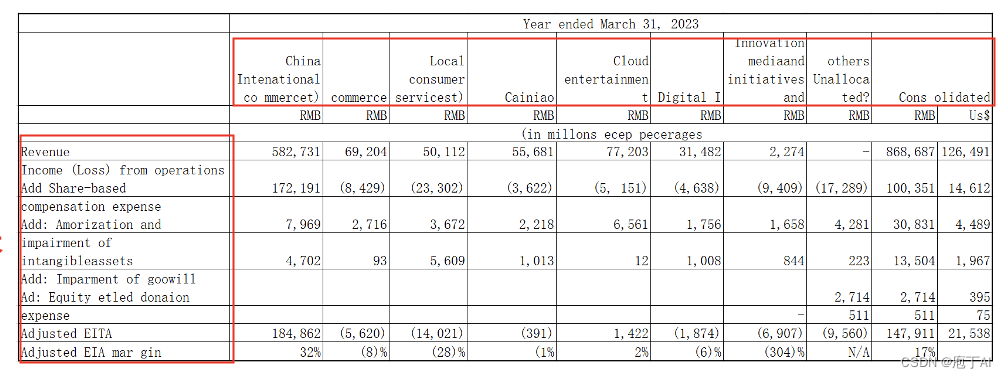
再来看具体的表格识别情况。PDFlux 识别准确,而 PPStructure 则在首行首列出现了多处识别错误:
文档全景结构识别,进阶版深度学习模型
PDFlux 之所以能够做得更好,秘密在于庖丁科技的「文档全景结构识别」技术。
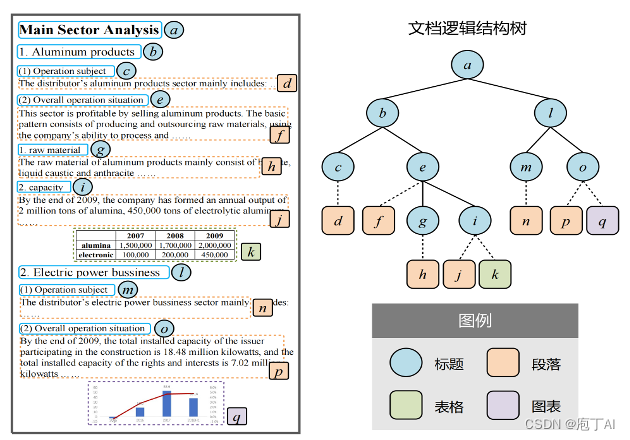
文档全景结构识别,是指深度学习模型在光学字符识别(OCR)的支持下,识别文档的物理和逻辑结构,将文档完全结构化为独立的标题、段落、表格、图表等内容块,明确阅读顺序,并输出为结构化的 JSON 数据。这个过程可以分为OCR、物理结构识别、跨页跨栏对象修整、阅读顺序识别、表格内部结构识别等模块。
-
首先,OCR 输出文档中的文本块及每个字符的位置和内容。
-
其次,物理结构识别输出文档中的物理组件(如表格、段落、图片)的外框位置和组件类型。对于跨栏、跨页的内容块,计算机需要判断哪些物理结构进行合并,以保证对象的结构和内容的完整性。
-
第三,根据阅读习惯,如从上到下、从左到右,或者更复杂的规则,输出物理组件的排列顺序。
-
第四,表格内部结构识别针对表格内部结构进行专门的识别,从而提取表格内部的信息和数据。
-
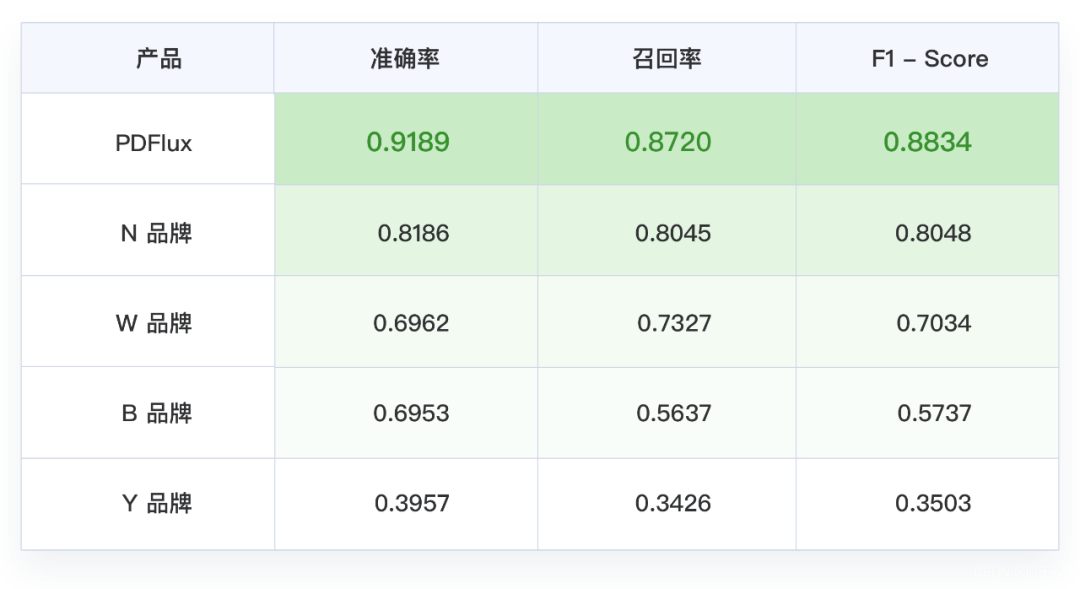
我们曾对市面上常见的 PDF 识别产品做过端到端的评测,PDFlux 对各类「疑难杂症」表格都有良好的识别效果,平均准确率、召回率也都业界领先。
 |  |
Embedding 模型,让 AI 所答即所问
现在,大模型的「知识硬盘」已经准备就绪了。
下一步是,收到问题后,怎么让大模型检索到「知识硬盘」中的有用信息,并基于此给出正确的回答?
目前的主流方案,检索任务通常是基于 「Embedding 模型+相似度计算」完成的。因此,Embedding 模型的质量对文档知识问答至关重要。
我们可以通过特定任务,来评测 Embedding 模型的质量。比如,金融行业一个常见的场景是,年报中关键信息的检索。我们可能会想知道,苹果公司 2022 年的归母净利润是多少,iPhone 的出货量是多少,中国地区的销售情况等等。
OpenAI 提供了 text-embedding-ada2 模型,我们也自研了庖丁的 Embedding 模型。为了对两者的关键信息召回效果进行评测,我们人工标注了几十篇文档,每个文档包含几百个关键信息的所在段落。
评价 Embedding 模型的好坏,一个关键指标是 Recall@10:模型找出的与问题相似度最高的 10 个段落中,包含正确答案信息的比例。
庖丁的 Embedding 模型因为我们采用了更高维的 Embedding 向量,可以存储更丰富的细节信息。因此庖丁的 Embedding 模型比 text-embedding-ada2 模型的 Recall @10 高出了 10 个百分点。特别是当正确答案信息散落在表格中时,庖丁的召回结果更好。
如何跑赢 90% 的同类产品
只有产品质量达到现有同类型产品的 90% 以上,才可能会有商用价值。
经过评测,庖丁科技的 PDF Parser、Embedding 模型,与百度、OpenAI 等大厂相比,在复杂文档的处理和关键信息的召回上,效果都更加出色。
我们集成了以上能力,打造了 ChatDOC 文档问答助手,它能够给出更精准、可溯源的回答,真正帮助大家解放生产力。
问答交互,更高效
如同抖音「打开即刷」一样,ChatDOC 可以「上传即问」。一问一答间,可以将冗长的文档化为可用的洞察,让工作更高效。
上传文档或者文件夹后,你可以向 ChatDOC 提出「由点及面」的各种问题:
-
全文提问,智能摘要:ChatDOC 根据文档内容,会智能生成 5 个问题。你也可以提出自己想要了解的问题。
-
划选原文,智能解读:选择表格/文段内容片段,让 AI 对原文进行翻译、解读、改写等等。
-
多轮追问:进入 Thread,就某一话题继续深入提问,保留上下文语义
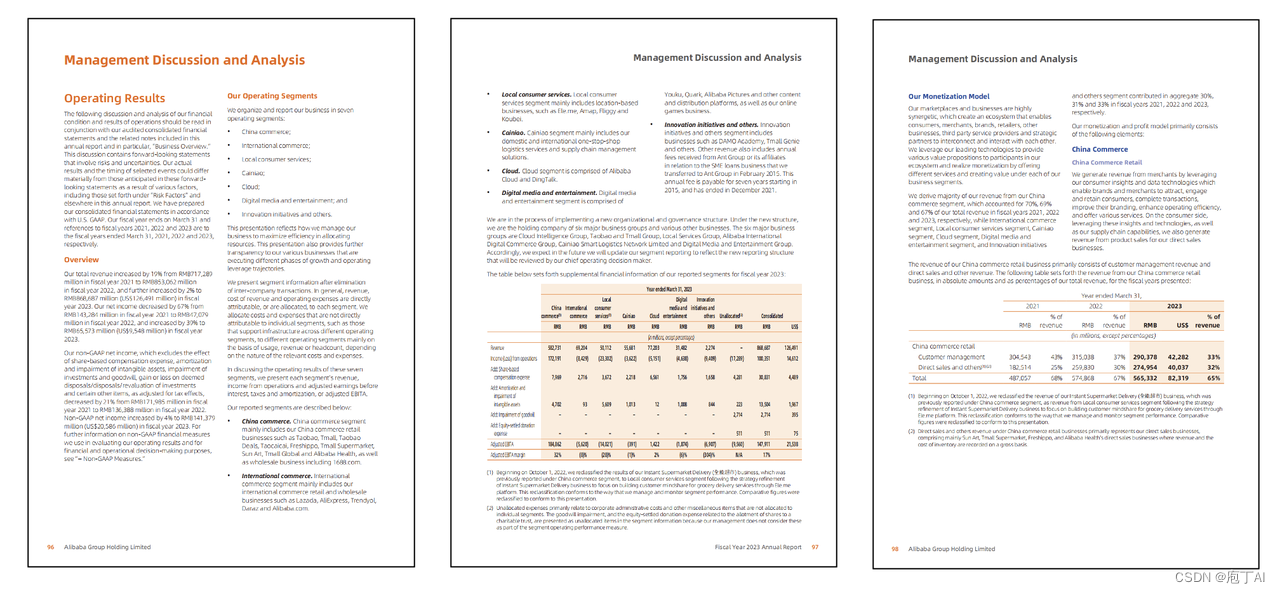
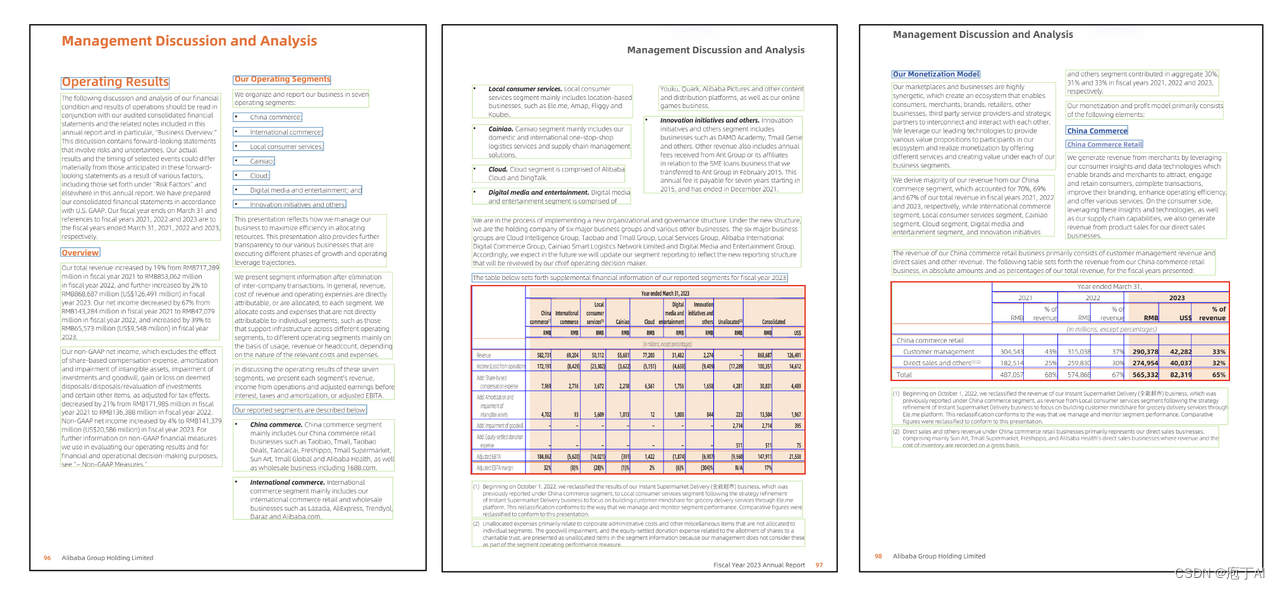
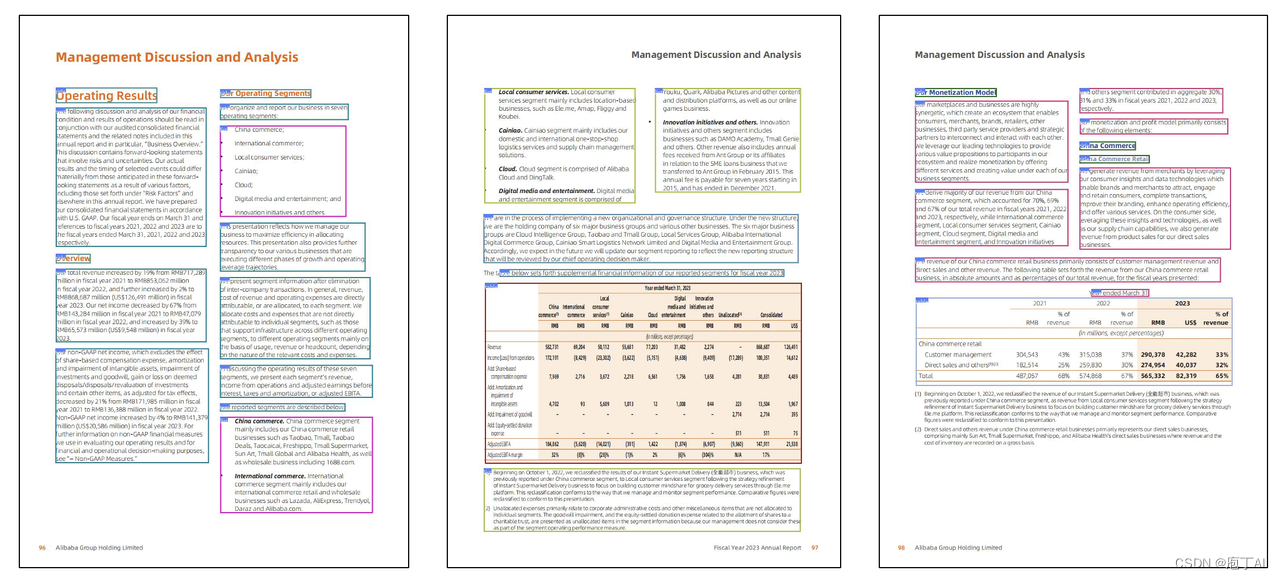
-
多文档提问:同时和多文档对话交互,效率百倍
有据可依,更可靠
AI 只是 Copilot,我们不能脱离原文档来进行问答。可用的知识问答产品,一定是可信、可控、可溯源的。
首先,ChatDOC 的所有回答均给出了原文的页码,并将引用列表按照相关度排序。
点击页码,就可以一键溯源到原文,方便人工二次核实。同时,在 Thread 里,你还可以设置 AI 回答的自由度。严肃场合,让 AI 严格依据原文回答;娱乐场景,允许引用其他公开信息。
此外,你还可以在原文档中进行关键词搜索,无论是PDF、Word、Markdown还是扫描件,都能极速定位关键信息。
最后,值得一提的是 ChatDOC 的 PDF 展示功能。几百页的文档,在 ChatDOC 中也能丝滑无感地打开。无论是浏览,还是溯源跳转,都无需等待加载,进一步减小你的阅读阻力。
搭建属于你的文档阅读应用
目前,ChatDOC 的问答、PDF 解析功能均提供了 API 接口,为大家提供稳定可靠的文档 AI 能力。
它是现成的智能化零件,你可以像搭建乐高积木一样,用它来拼装你想要的应用。
通过 ChatDOC API,你可以:
-
创建个性化的文件问答助手
-
从 PDF/Word/MarkDown/扫描件中准确提取信息
-
丝滑展示原始文件
-
AI回答的原文片段溯源
通过 ChatDOC PDF Parser,你可以:
-
从 PDF/Word/MarkDown/扫描件中准确提取信息
-
将文本、表格存储为结构化的数据
结语
我们处在一个信息过载,而并非信息匮乏的时代。
只有提高 AI 生产信息的质量,才能真正减少人类阅读、筛选信息的成本,解放生产力。这背后需要许多技术侧的努力:
-
做足够好的 PDF Parser ,准确提取文档中的文本、表格等数据,按照知识单元进行存储,是问答的基础。基于规则的文档切分效果有限,深度学习模型具有更强的文档理解能力。
-
做足够好的 Embedding 模型,进行向量化表示,计算文本语义相似度,实现问题与答案的准确匹配。采用更高维的向量,可以编码更丰富的语义信息,提高关键信息的召回率。
PDF Parser 和 Embedding 模型的质量直接决定了文档问答产品的效果。经过系统性评估,ChatDOC在这两个方面都优于业内其他解决方案,可以提供更高效、更可靠的文档问答服务。
我们的 API 服务也能够力开发者快速打造定制化文档应用,解放大量重复劳动,使我们离信息自由更进一步。

















 4686
4686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









