







Simple Contrastive Graph Clustering
文章目录
摘要:
对比学习由于其良好的性能最近在深度图聚类中引起了广泛的关注。然而,复杂的数据扩充和耗时的图卷积操作破坏了这些方法的效率。为了解决这个问题,我们提出了一个简单的对比图聚类(SCGC)算法,从网络架构,数据增强,目标函数的角度改善现有的方法。在体系结构上,我们的网络包括两个主要部分,即预处理和网络骨干。一个简单的低通去噪操作进行邻居信息聚合作为一个独立的预处理,只有两个多层感知器(MLP)被包括作为骨干。对于数据增强,我们构建了两个增强视图的同一个顶点,而不是引入复杂的操作图,通过设计参数非共享的连体编码器和扰动的节点嵌入直接。最后,在目标函数方面,为了进一步提高聚类性能,设计了一种新的跨视图结构一致性目标函数,以提高学习网络的判别能力。在七个基准数据集上的实验结果验证了该算法的有效性和优越性。值得注意的是,我们的算法优于最近的对比深度聚类竞争对手,平均加速至少7倍。SCGC的代码在SCGC发布。此外,我们在ADGC上分享了一系列深度图聚类,包括论文,代码和数据集。
主要贡献:
1)我们提出了一种简单而有效的对比深度图聚类方法,称为SCGC。SCGC的简单性使其无需预训练,节省了网络训练的时间和空间。
2)提出了一种新的数据增广方法,该方法只在增强的属性空间中进行数据扰动。经验证,该方法与现有的对比方法是一致的。
3)我们设计了一种新的面向邻居的对比损失,即使在视图之间也能保持结构的一致性,从而提高了网络的区分能力。
4)在七个基准数据集上的大量实验结果表明,该方法相对于现有的最先进的深度图聚类竞争对手的优越性和效率。
深度图聚类:
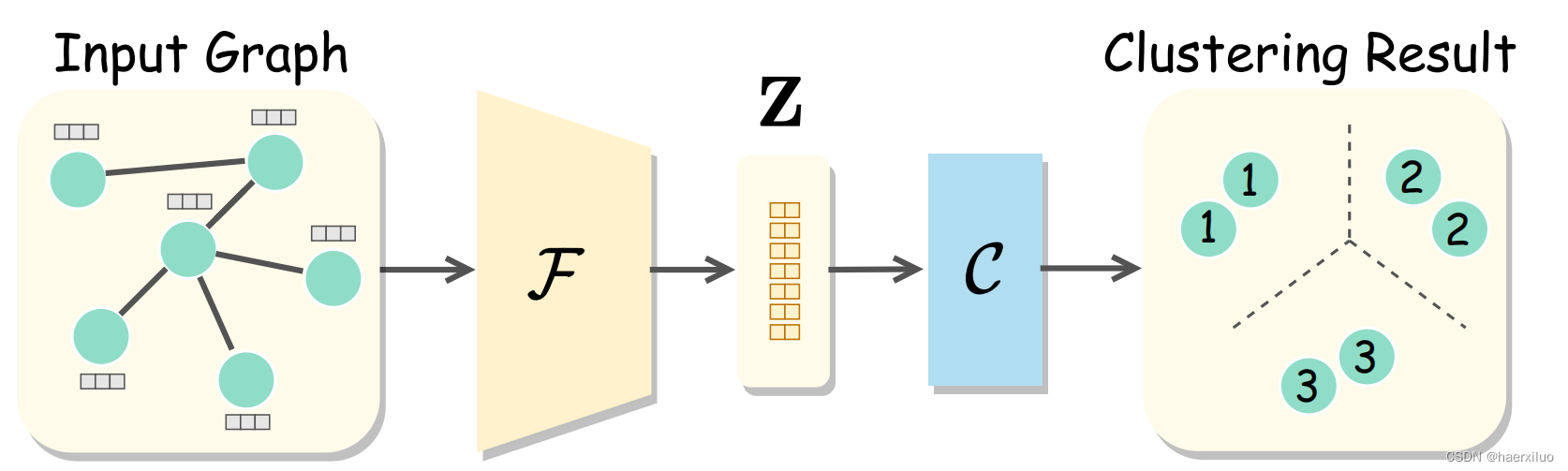
1. Methodology
1.1 算法流程图
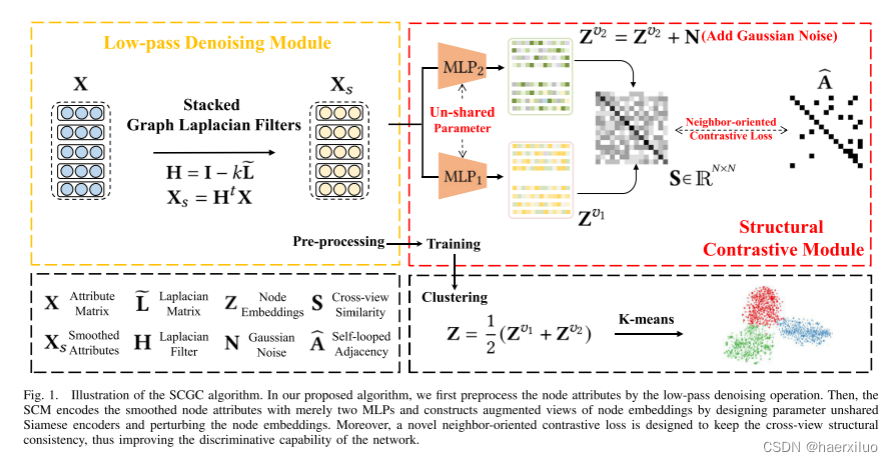
在我们提出的算法中,我们首先通过低通去噪操作预处理节点属性。然后,SCM结构对比模块仅用两个mlp对平滑的节点属性进行编码; 并通过设计参数非共享的编码器和扰动节点嵌入来构建节点嵌入的增强视图。此外,一个新的邻居导向的对比损失的设计,以保持跨视图结构的一致性,从而提高了网络的判别能力。

1.2 基本定义及问题描述
深度图聚类旨在以无监督的方式将图中的节点划分为若干不相交的组。具体地,首先以无监督方式训练神经网络F,并通过利用节点属性和结构信息对节点进行编码,如下所示:

其中X和A分别表示属性矩阵和原始邻接矩阵。此外,E ∈ RN×d是学习的节点嵌入,其中N是样本的数量,d是特征维数。之后,采用聚类算法C,例如K-means ,谱聚类或聚类神经网络,将学习的节点嵌入E划分为k个不相交的组,如下所示:

1.3 低通道去噪操作
最近的工作[13],[59],[60]已经证明拉普拉斯滤波器[55]可以实现与图卷积运算[53]相同的效果。受他们成功的启发,我们引入了一个低通去噪操作,在训练前作为一个独立的预处理来进行邻居信息聚合。以这种方式,将有效地滤除属性中的高频噪声。具体地,我们引入一个图拉普拉斯滤波器,其公式为:

其中eL表示对称归一化图拉普拉斯矩阵。随后,我们将t层图拉普拉斯滤波器堆叠如下:

通过这种低通去噪操作,过滤掉属性中的高频噪声,从而提高聚类性能和训练效率。
1.4 结构对比模块(SCM)
在本节中,我们设计SCM,即使在两个不同的视图之间也保持结构一致性,从而增强网络的区分能力。具体来说,我们首先用设计的参数非共享MLP编码器对平滑属性Xs进行编码,然后用2范数对学习的节点嵌入进行归一化,如下所示:

此外,我们通过简单地将随机高斯噪声添加到Zv2来进一步保持两个视图之间的差异,公式为:

其中N ∈ RN×d是从高斯分布N(0,σ)中采样的。总之,我们通过设计参数非共享编码器并直接扰动节点嵌入来构建两个增强视图Zv 1和Zv 2,而不是引入针对图的复杂操作,从而提高了训练效率。
此外,最近的工作[61],[62],[63]已经表明,图上的复杂数据扩充,如边添加,边删除和图扩散可能导致语义漂移。通过第IV-E2节中的实验验证了类似的结论。随后,我们设计了一种新的面向邻居的对比损失,以保持跨视图结构的一致性。具体地,我们计算Zv 1和Zv 2之间的交叉视图样本相似性矩阵S ∈ RN×N,公式为:

其中,Si,j表示第一视图中的第i个节点嵌入与第二视图中的第j个节点嵌入之间的余弦相似度。然后,我们强制交叉视图样本相似性矩阵S等于自循环邻接矩阵bA ∈ RN×N,设计了一种新的跨视图结构一致性目标函数,公式为:

在这里,我们认为跨视图的邻居相同的节点作为正样本,而其他非邻居节点作为负样本。然后,我们将阳性样本拉在一起,同时推开阴性样本(本质)。更确切地说,在损失函数中,第一项迫使节点即使在两个不同的视图上也与它们的邻居一致,而第二项使节点与其非邻居之间的一致性最小化。这种面向邻居的对比目标函数通过保持交叉视图结构的一致性,增强了我们的网络的区分能力,从而提高了聚类性能。
不同的方法对于Loss函数的设计:

1.5 融合与聚类
首先融合节点嵌入的两个增强视图,线性地表示为

其中Z ∈ RN×d表示结果的面向聚类的节点嵌入。然后,我们直接在Z上执行K-means算法并获得聚类结果。
2. Experiment
数据集:

实验结果:
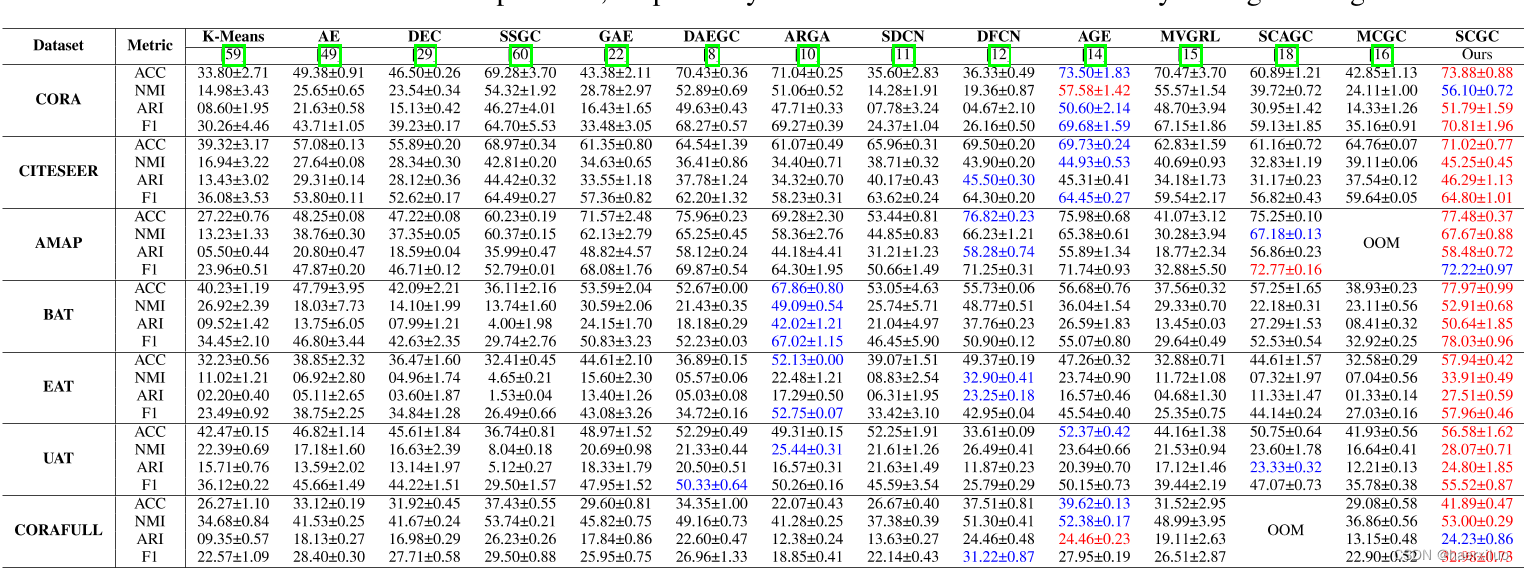
论文没给代码
2.1. 参考链接
https://github.com/yueliu1999/Awesome-Deep-Graph-Clustering
’














 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









