







论文标题
Simple Contrastive Graph Clustering
论文作者、链接
作者:
Liu, Yue and Yang, Xihong and Zhou, Sihang and Liu, Xinwang
链接:https://arxiv.org/abs/2205.07865
Introduction逻辑(论文动机&现有工作存在的问题)
图学习——深度图聚类,主要分为:生成式,对抗式和对比式——这些方法通过聚类导向的损失函数来使得生成的样本拟合预先生成的聚类分布,于是初始化的簇中心对模型的影响很大——最近,由于对比学习的兴起,设计了更一致和有区别的对比损失函数来取代聚类引导的损失函数用于网络训练——对比学习的损失函数消除了初始化簇中心所带来的人工误差——然而,复杂的数据增广以及图卷积的耗时比较大,使得这些方法的效率比较低下
为了解决上述问题,本文提出了(Simple Contrastive Graph Clustering ,SCGC)方法,从网络架构、数据增广、目标函数的方面来改进聚类能力。网络架构方面,使用孪生网络,由MLP构成。网络训练前独立进行邻域信息聚合过程。这个过程中过滤了高频的噪音,提高了模型的效果以及训练效率。对于数据增广,抛弃了构建相同节点的不同视图,改为使用两个参数不共享的孪生编码器,并且用高斯噪音对节点嵌入进行扰动。本文还是设计了一个面向邻居的对比目标函数,迫使跨视图相似性矩阵去逼近自环邻接矩阵,如此一来使得模型可以保持跨视图一致性。
论文核心创新点
提出了一个简单有效的对比深度图聚类模型
新的数据增广方法
新的面向邻居的对比目标函数
相关工作
深度图聚类
对比深度图聚类
论文方法
标识与问题定义

让代表
个节点共分为
个类别的集合,
代表边的集合。
以及
分别代表特征矩阵和初始的邻接矩阵。
代表一个无向图。度矩阵表示为
以及
。图拉普拉斯矩阵定义为
。在GCN中,使用一个重新归一化的技巧,即
,对称归一化图拉普拉斯矩阵定义为
。
深度图聚类的目标是将图中的结点一无监督的方式分配到一系列不相邻的组。具体来说,就是以一种无监督的方式去训练一个神经网络,通过探索结点的特征以及结构信息来对结点进行编码,即
。其中,
分布代表特征矩阵和原始的邻接矩阵。此外,
是学到的结点嵌入,其中
是样本的个数,
是特征维度。然后,一个聚类算法
,比如K-means,谱聚类,聚类神经网络,用来将学到的结点嵌入
分到
个不相邻的组,即
,其中
表示对于所有的
个结点的簇隶属度矩阵
全局框架

低通降噪操作Low-pass Denoising Operation
近期工作证明了,拉普拉斯滤波器约图卷积的效果相同。于是,本文引入了一个低通的降噪操作来指导邻居信息的聚合,作为一个独立的预处理方法,可以非常高效的将高频噪音进行滤除。
引入一个图拉普拉斯滤波器,即,其中
代表对称的归一化图拉普拉斯矩阵。将
层的图拉普拉斯滤波器堆叠起来,公式如下
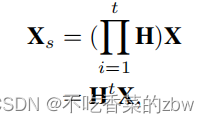
其中表示平滑的特征矩阵,
代表堆叠了
层的图拉普拉斯滤波器,可以滤除结点特征中的高频噪音。
结构对比模块
本文设计了结构对比模块(Structure Contrastive Module ,SCM)来保持跨视图间的结构一致性,由此来增加网络的辨别能力。
首先对平滑的特征矩阵进行编码,通过参数不共享的MLP编码器,并且用
归一化对得到的结点嵌入进行归一化,公式如下:

其中表示学习到的结点嵌入的两个增广的视图。因为两个MLP编码器是不参数共享的,所以
可以得到不同的语义信息。
进一步保持两个视图之间的不同性,简单地对其添加高斯噪音,即

其中是从高斯分布
中采样的。总的来说,就是通过设计两个参数不共享的编码器构建两个增广视图
,并且之间对视图添加噪音而不是使用一些更复杂的操作,如此可以提高训练效率。此外,最近的研究表明,复杂的数据在图上的增强,如边的增加、边的丢弃和图的扩散可能会导致语义漂移。
随后设计了一个源于邻居的对比损失来保持跨视图的结构一致性。计算跨视图的相似性矩阵公式如下:

其中代表第
个结点的第一个视图嵌入和第
个结点嵌入的第二个视图,的余弦相似性。这迫使跨视图样本的相似性矩阵
与自环邻接矩阵
相等,公式如下:

其中![]() 代表
代表,
![]() 代表
代表。将同一个结点的邻居结点的跨视图对视为正样本对,同时将不相邻的结点视为负样本对。将正样本对聚集起来,将负样本对推远。在公式8中,第一项迫使结点在跨两个不同视图的情况下,与邻居结点相似,同时第二项使得结点与其非邻居结点相似性减小。这种面向邻居的对比目标函数通过保持跨视图结构的一致性,增强了网络的判别能力,从而提高了聚类性能
融合以及聚类
将一个结点的两个增广视图嵌入进行一个线性的融合,公式如下:
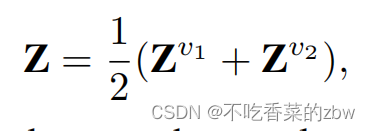
其中,表示面向聚类的节点嵌入的融合结果。然后对
直接进行K-means得到聚类结果。
算法流程

消融实验设计
低通降噪操作&结构对比模块
本文提出的数据增广
超参敏感度
一句话总结
感觉最大的创新点在于(1)只使用高斯噪音来构建增广(2)参数不共享的编码器















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









