







1.回顾
1.1 RCNN
算法流程:
- 使用Selective Search方法在输入的每一张图片上生成2000个左右的候选区域;
- 对每个候选区域,使用深度卷积网络提取特征;
- 特征送入每一类的SVM分类器,判别是否属于该类;
- 使用回归器进一步修正候选框位置。

1.2 Fast RCNN
1.2.1 改进之处:
- 卷积不再是对每个候选区域做,而是对整张图片,减少了重复计算。
- 使用ROI pooling进行特征的尺寸变换,将候选区域变换为一样大小,这样才可以输入全连接层。
- 将分类器放进网络里面一起进行训练,用softmax代替SVM。
1.2.2.算法流程
- 深度卷积网络提取图像特征;
- 使用Selective Search方法在输入的每一张图片上生成2000个左右的候选区域;
- 将以上两部分送入ROI Pooling层,使候选区域大小一样,然后传入全卷积层;
- 分为两个输出层,其中一个使用softmax进行分类,另一个输出四个值(边框回归)。

2. Faster R-CNN
2.1 改进之处
(1)使用RPN网络生成候选区域
(2)将候选区域生成,特征提取,分类器分类,回归器回归这四步全都交给深度神经网络来做,大大提高了操作的效率。
2.2 总体结构

- 首先,输入图片统一缩放到固定大小;
- 接着深度卷积网络提取图像特征;
- 接着图像特征传入RPN网络;
- 接着是ROI Pooling层,传入的是图片特征和proposal,输出的是proposal feature maps;
- 最后是全连接层进行分类和再一次回归。
2.3 anchors
对于卷积特征图,每个点生成k(9)个不同大小的anchor作为初始的检测框,宽高比分别为1:1、1:2、2:1三种,其实就是多尺度操作。
2.4 RPN 网络
1)首先经过3×3卷积(输入的M×N大小经过一系列卷积(不考虑池化层)操作后变为(M+2)×(N+2)(卷积的填充P=1),再经过3×3卷积就可以变为M×N大小。总体来说(池化层考虑进来)最终的特征图大小为(M/16)×(N/16)(4个池化层,每个池化缩小两倍));
2)两条线路,上面的通过softmax生成正例和负例的分类;下面的计算对应的边界框回归偏移量;
3)最后的proposal层综合正例以及偏移量获取精确的proposal,同时剔除太小和超出边界的proposals。
2.5 损失函数
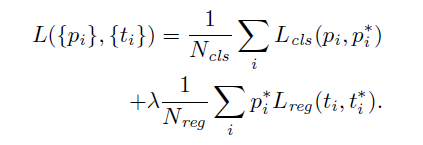
其中,i是mini-batch中的anchor的索引,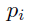 是第i个anchor作为object的预测概率。如果anchor为正,则ground-truth标签
是第i个anchor作为object的预测概率。如果anchor为正,则ground-truth标签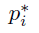 为1,如果anchor为负,则ground-truth标签
为1,如果anchor为负,则ground-truth标签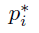 为0。
为0。 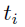 是代表预测边界框的4个参数化坐标的向量,
是代表预测边界框的4个参数化坐标的向量,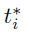 是与正anchor关联的ground-truth的4个参数化坐标。分类损失
是与正anchor关联的ground-truth的4个参数化坐标。分类损失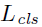 是两个类别(object与非object)之间的对数损失。对于回归损失,使用
是两个类别(object与非object)之间的对数损失。对于回归损失,使用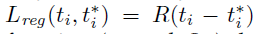 ,其中R是smooth L1损失函数。
,其中R是smooth L1损失函数。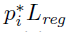 表示仅对正anchor
表示仅对正anchor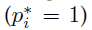 激活回归损失,否则不计算回归损失
激活回归损失,否则不计算回归损失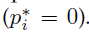 。cls和reg层的输出分别由
。cls和reg层的输出分别由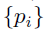 和
和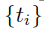 组成。
组成。
这两项通过Ncls和Nreg归一化,并通过平衡参数λ加权。在当前的实现中,等式(1)中的Ncls项数值等于mini-batch大小,而Nreg项的数值等于anchor的数量。默认情况下,设置λ= 10。
2.6 训练

第一步,训练RPN。该网络使用ImageNet预训练的模型初始化,并针对region proposal任务端到端进行了微调。在第二步中,使用步骤1 RPN生成的proposal,通过Fast R-CNN训练一个单独的检测网络。该检测网络也由ImageNet预训练模型初始化。此时,两个网络不共享卷积层。在第三步中,使用检测网络初始化RPN训练,但是调整了共享卷积层,并且仅微调了RPN唯一的层。现在,这两个网络共享卷积层。最后,保持共享卷积层固定不变,对Fast R-CNN的唯一层进行微调。这样,两个网络共享相同的卷积层并形成统一的网络。可以进行类似的交替训练进行更多迭代,但是观察到这样做的提升很小。














 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









