






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
一、PPO算法的介绍
PO 算法是一种基于策略(on - policy)的强化学习算法。它通过不断地与环境交互,根据当前策略选择动作,并根据环境反馈的奖励来更新策略,以最大化长期累积奖励。
二、PPO算法的主要内容
1.Actor - Critic 架构
PPO 算法采用 Actor - Critic 架构。其中,Actor(策略神经网络)负责根据环境状态选择动作,输出动作的概率分布或均值和方差(在连续动作空间的情况下);Critic(价值神经网络)负责评估环境状态的价值,输出对该状态的价值估计。
2.重要性采样与更新
算法利用重要性采样来更新目标策略。它从行为策略(旧策略)获得的数据中更新目标策略(新策略),通过计算新旧策略下动作概率的比值,并结合优势函数来构建损失函数,从而有效地利用收集到的经验数据进行学习,提高学习效率。
通过计算目标函数关于策略网络参数的梯度,并沿着梯度方向更新策略网络的参数,逐渐优化策略。这个过程类似于在一个复杂的地形(策略空间)中,朝着奖励更高的方向(梯度上升方向)移动,以找到最优策略。
三、求解倒立摆问题中 PPO 算法的神经网络相关情况
1.策略神经网络(Actor)
输入:通常是倒立摆系统的状态信息,例如摆杆的角度、角速度等。这些状态信息能够描述倒立摆当前的物理状态。
输出:动作的概率分布(在离散动作空间中,可能是向左推或向右推的概率;在连续动作空间中,可能是施加力的大小的均值和方差)。
损失函数:一般通过最小化策略网络输出的动作概率分布与基于优势函数调整后的目标分布之间的差异来构建。例如,常见的形式是
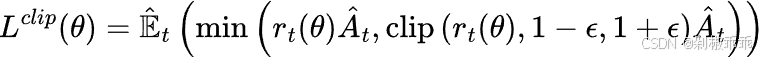
其中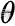 是策略参数,E^(t)表示对时间步长的经验期望,r(t)是在新策略和旧策略下的概率比,A(t)是在时刻估计的优势,
是策略参数,E^(t)表示对时间步长的经验期望,r(t)是在新策略和旧策略下的概率比,A(t)是在时刻估计的优势,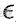 是一个超参数(通常是 0.1 或者 0.2)。
是一个超参数(通常是 0.1 或者 0.2)。
2.价值神经网络(Critic)
输入:同样是倒立摆系统的状态信息,如摆杆的角度、角速度等。
输出:对该状态的价值估计,用于评估在该状态下采取动作的预期回报。
损失函数:通常是均方误差损失,即计算预测的价值与实际回报或优势值之间的差距。例如,如果预测的价值为V(s),实际回报或优势值为R,则损失函数可以表示为:
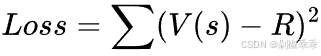
四、PPO算法与DDPG算法的区别
PPO算法:使用了重要性采样(Importance Sampling)和裁剪(Clipping)技术来更新策略。它通过计算新旧策略下动作概率的比值,并结合优势函数来构建损失函数。为了防止策略更新幅度过大,采用了裁剪技术,限制新旧策略概率比值的范围。
DDPG算法:通过确定性策略梯度定理(Deterministic Policy Gradient Theorem)来更新策略。它直接计算策略的梯度,然后使用梯度下降算法更新策略参数。
五、代码实现
由于此类算法的应用在前面的已有讲解,详细内容不再赘述DDPG算法求解倒立摆问题,在这里仅仅展示PPO算法求解倒立摆问题的代码:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import gym
from collections import namedtuple
# 定义经验回放的结构
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward', 'done'))
class PPOAgent:
def __init__(self, state_dim, action_dim, hidden_dim=64, gamma=0.99, lr=3e-4, eps_clip=0.2):
self.gamma = gamma
self.eps_clip = eps_clip
# 策略网络
self.policy_net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim),
)
self.policy_std = nn.Parameter(torch.ones(action_dim) * 0.1) # 初始化标准差为较小的值
# 值函数网络
self.value_net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1),
)
self.optimizer = optim.Adam(
list(self.policy_net.parameters()) + list(self.value_net.parameters()) + [self.policy_std], lr=lr)
def select_action(self, state):
if isinstance(state, tuple):
state = state[0]
state = torch.from_numpy(state).float().unsqueeze(0)
mean = self.policy_net(state)
std = self.policy_std.expand_as(mean)
dist = torch.distributions.Normal(mean, std)
action = dist.sample()
return action.detach().numpy()[0]
def update(self, transitions):
# 提取转换中的信息
re = []
for i in range(len(transitions)):
if i == 0:
re.append(transitions[i].state[0])
else:
re.append(transitions[i].state)
states = torch.tensor(re, dtype=torch.float)
actions = torch.tensor([t.action for t in transitions], dtype=torch.float)
rewards = torch.tensor([t.reward for t in transitions], dtype=torch.float)
next_states = torch.tensor([t.next_state for t in transitions], dtype=torch.float)
dones = torch.tensor([t.done for t in transitions], dtype=torch.float)
# 计算优势函数
values = self.value_net(states)
next_values = self.value_net(next_states)
returns = rewards + self.gamma * next_values * (1 - dones)
advantages = returns - values
# 计算策略损失和价值损失
mean = self.policy_net(states)
std = self.policy_std.expand_as(mean)
dist = torch.distributions.Normal(mean, std)
log_probs = dist.log_prob(actions).sum(-1)
ratios = torch.exp(log_probs - log_probs.detach())
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
value_loss = nn.MSELoss()(values.squeeze(), returns)
loss = policy_loss + 0.5 * value_loss
# 反向传播和优化
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 使用 PPO 算法训练智能体
env = gym.make('Pendulum-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.high.shape[0] # 对于连续动作空间,使用 high 的维度
agent = PPOAgent(state_dim, action_dim)
num_episodes = 1000
for i_episode in range(num_episodes):
state = env.reset()
transitions = []
for t in range(200): # Pendulum-v1 的最大时间步为 200
action = agent.select_action(state)
next_state, reward, done, _, _ = env.step(action)
transitions.append(Transition(state, action, next_state, reward, done))
state = next_state
if done:
break
agent.update(transitions)
if i_episode % 10 == 0:
print(f'Episode {i_episode}/{num_episodes}, Reward: {sum([t.reward for t in transitions])}')
总结
PPO算法与DDPG算法在水下自适应编码中均广泛的有应用,但两者之间略有区别,后续博主会继续更新基于强化学习的水声OFDM信道自适应调制方案论文的详细内容。

















 2291
2291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









