







简单地说,大多数机器学习算法可以分成训练(training)和测试(testing)两个步
骤,这两个步骤可以重叠进行。训练,一般需要训练数据,就是告诉机器前人的
经验,比如什么是猫、什么是狗、看到什么该停车。训练学习的结果,可以认为
是机器写的程序或者存储的数据,叫模型(model)。总体上来说,训练包括有监督
(supervised learning)和无监督(unsupervised learning)两类。有监督好比有老师告
诉你正确答案;无监督仅靠观察自学,机器自己在数据里找模式和特征。深度学
习(deep learning)是机器学习的一种方法,它基于神经元网络,适用于音频、视
频、语言理解等多个方面。
解决机器学习问题的一般流程如下:
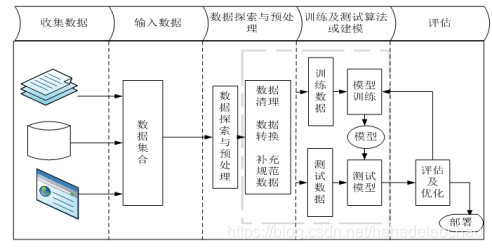
1.数据收集
业界有一句非常著名的话:“数据决定了机器学习的上界,而模型和算法只是逼近这个上界。”由此可见,数据对于整个机器学习项目至关重要。通常,我们拿到一个具体的领域问题后,可以使用网上一些具有代表性的、大众经常会用到的公开数据集。相较于自己整理的数据集,显然大众的数据集更具有代表性,数据处理的结果也更容易得到大家的认可。此外,大众的数据集在数据过拟合、数据偏差、数值缺失等问题上也会处理的更好。但如果在网上找不到现成的数据,那我们只好收集原始数据,再去一步步进行加工、整理,这将是一个漫长的过程,需要我们足够细心。
2.数据预处理与特征工程
即使我们能够拿到大众认可度比较高的代表性数据集,该数据集也会或多或少存在数据缺失、分布不均衡、存在异常数据、混有无关紧要的数据等诸多数据不规范的问题。这就需要我们对收集到的数据进行进一步的处理、包括数据的清洗、数据的转换、数据标准化、缺失值的处理、特征的提取、数据的降维等方面。我们把对数据的这一系列的工程化活动,叫做“特征工程”。我们通常使用sklearn库来处理数据、提取特征,sklearn是机器学习中最常见的一个第三方模块,里边封装了大量特征处理的方法,详细方法请参阅sklearn官方手册: http://scikit-learn.org/stable/modules/preprocessing.html#preprocessing。
3.模型的选择与训练
可供选择的机器学习模型有很多,每个模型都有自己的适用场景,那么如何选择合适的模型呢?首先我们要对处理好的数据进行分析,判断训练数据有没有类标,若是有类标则应该考虑监督学习的模型,否则可以划分为非监督学习问题。其次分析问题的类型是属于分类问题还是回归问题,当我们确定好问题的类型之后再去选择具体的模型。在模型的实际选择时,通常会考虑尝试不同的模型对数据进行训练,然后比较输出的结果,选择最佳的那个。此外,我们还会考虑到数据集的大小。若是数据集样本较少,训练的时间较短,通常考虑朴素贝叶斯等一些轻量级的算法,否则的话就要考虑SVM等一些重量级算法。
4.模型的评估与优化
一些常见的模型评估的指标和方法。例如:我们可以选择查准率、查全率、AUC指标表现更好的模型;还可以通过交叉验证法用验证集来评估模型性能的好坏;当然,也可以针对一种模型采用多种不同的方法,每种方法给予不同的权重值,来对该模型进行综合“评分”。
在模型评估的过程中,我们可以判断模型的“过拟合”和“欠拟合”。若是存在数据过度拟合的现象,说明我们可能在训练过程中把噪声也当作了数据的一般特征,可以通过增大训练集的比例或是正则化的方法来解决过拟合的问题;若是存在数据拟合不到位的情况,说明我们数据训练的不到位,未能提取出数据的一般特征,要通过增加多项式维度、减少正则化参数等方法来解决欠拟合问题。最后,为了使模型的训练效果更优,我们还要对所选的模型进行调参,这就需要我们对模型的实现原理有更深的理解。
此外,在实际项目中,我们还会对机器学习的模型进行模型的融合,根据模型的重要程度对每个模型设置不同的权重等,以调高模型的准确率。














 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









