







发现之前了解的faster rcnn有些误区,所以在此重新整理。faster rcnn之前的SPP等请浏览 https://blog.csdn.net/hancoder/article/details/87917174
Faster R-CNN = Fast R-CNN + RPN
- 推荐链接,https://zhuanlan.zhihu.com/p/31426458 ,http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/ ,https://github.com/ruotianluo/pytorch-faster-rcnn
- 之前的Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。
解决方法:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了,即Region Proposal Network(RPN)。 - Faster R-CNN解决的是,“为什么还要用selective search呢?”----将选择性搜索候选框的方法换成Region Proposal Network(RPN)。
1:R-CNN的框架

框架的主体即把图像归一化到固定尺寸后,首先经过一个如VGG等简单的卷积网络,即图上Head:feature extraction。然后用RoI (Region of Interest )网络选出可能存在物体的一些候选框(前背景2分类),即RPN网络。最后对这些候选框进一步分类(细分类别),即Classification Network。
这里多层网络的想法由来是:靠前的一些层检测一些边和颜色斑点,大概地提取一些特征,这可以应用在在很多问题上。然后高层的卷积才是具体的问题。
下面这张图的目的是为了显示训练分阶段的,即像Fast R-CNN等之前的方法一样,先产生建议框,然后拿建议框去分类,只不过这里建议框的生成方式换成了RPN网络。

2:图像的预处理

减的这个均值不是当前图像像素的平均值,而是与所有训练和测试图像有关。默认的参数值是600和1000。
输入图像会压缩到M×N,但M和N不是定值,缩放过程中原图的长款比例是不变的。变化规则是把最短边缩放到固定尺寸600,原图的比例是保持不变的(如果缩放后的较长边超过了限度1000,就要以长边为基准缩放)。而这个缩放信息保持在im_info=[M,N,scale_factor]中。
3:RPN
-
RPN的最终结果是用CNN来生成候选窗口,通过得分排序等方式挑出量少质优的框(~300)
-
让生成候选窗口的CNN和分类的CNN共享卷积层
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud。所以,仅仅是个二分类而已!
-
具体做法:
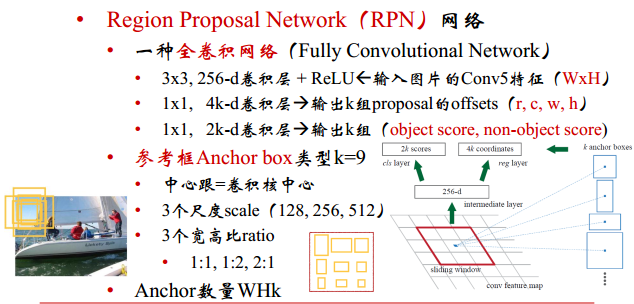
3.1名词介绍:anchors: The k proposals are parameterized relative to k reference boxes,which we call anchors
比如原始输入图像的大小是256x256,特征提取网络中含有4个pool层,然后最终获得的特征图的大小为 256/16 x 256/16,即获得一个16x16的特征图,该图中的最小单位即是锚点,由于特征图和原始图像之间存在比例关系,在特征图上面密集的点对应到原始图像上面是有16个像素的间隔。

3.2锚点与原图的对应
可能你还是不太清楚anchor是什么。假设我们此时看的是特征图上正中心的一个点,那么以这个点为中心进行3×3卷积,对应的感受野仍是以原始输入图像为中心的,而大小变为: 3 × 2 4 = 48 3×2^4=48 3×24=48的区域。特征图上3×3卷积可以看做是3×3大小的框,而因为感受野的存在,对应到原图上是在这48个像素内画的一组框,这个数量可能有些庞大,但原始图像上这个区域最多有2,3个物体,所有我们只要设置3种大小,3种长宽比的框就可以了,至于跟真实框的匹配程度,我们只需要通过这9个框慢慢回归到真实框就可以了。总之,conv5_3特征图上的3×3卷积是对应9个anchors预设框的。
具体这9个anchor的宽高是多少呢?在程序中直接运行作者demo中的generate_anchors.py可以得到9个输出,这9个输出对于每个3×3是通用的,但这个anchors其实是超参,或者是根据gt框聚类得到的。
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
# anchor得出每个anchor的 4个数对应的是左上角和右下角的坐标,第1+第3=第2+第4=15,我们可知这个是左上角坐标为(7,7)那个点的anchors,anchors中长宽1:2中最大为352x704,长宽2:1中最大736x384,基本是cover了800x600的各个尺度和形状。
这里卷积的细节是在conv5_3特征图上用3×3的窗口滑动(stride=1,padding 0填充,即输入输出大小不变,改变的是通道数),每个3×3窗口可能对应原图多种(k=9种)形状(3种大小,三种形状)。相当于conv5_3上的每一个3×3图对应原图的某一位置的框。我们让3×3卷积后得到的下一层特征图rpn/output通道数与上一个特征图conv5_3通道数相等,这样下一层特征图rpn/output的每一个点对应上conv5_3上的一个3×3的anchor,而conv5_3上的3×3anchor对应于原图的一块区域。
此时我们得到的rpn/output特征图相当于每个点都对应于原图某个位置的框。那我们针对rpn/output特征图上每个点进行处理或者算loss就相当于对原图上的框做处理或者调整。所以我们的思路是用1×1的卷积核在rpn/output特征图上做滑动,这样滑动得到的特征图还是每个点对应于原图上某个位置的框。这步实际操作的时候是用两组1×1的卷积两路并行(1×1卷积特征图宽高不变),一路用于计算边框位置,一路用于计算框出物体的分类,只不过RPN这里我们不进行分类,仅仅区分是前/背景就可以了。这两路的具体形式后面再讲。
3.3坐标的变换:编码解码

坐标分别算的是中心坐标与宽高。如果你大概看一眼下面的loss,看就把t看作是预测的xywh,而 t ∗ t * t∗是真实的xywh。但不知你有没有想过如果只是这样直接回归,那默认框怎么在loss里体现?前面这种简单的回归方法在loss中只体现了预测值与真实值,但我们还有个默认框的先验值,我们是要在默认框上回归的。答案在于:如果你跑代码的话,你就会发现t和 t ∗ t * t∗分别是预测值和真实值这个说法虽然是正确的,但是t和 t ∗ t * t∗实际上分别是【预测框与默认框的距离G-A】和【真实框和默认框的距离G’-A】,这样设置的话我们就把默认框的信息包含到loss里了。这种通过默认框间接得出预测框位置的方法的术语其实就是框信息的“编码解码”。这种编码方式文中叫做offset.
xy代表的是框的中心,而x,y移动的距离是与w,h有关的,w,h越大,我们就让xy移动得多一些,反之则移动得小一些。其中 t ∗ t* t∗代表预测框A与真实框G的距离(平移量),t代表预测框A与调整后的预测框G’的距离。算Loss时算的是算出的平移量与实际平移量之间的误差 L r e g ( t i , t i ∗ ) = R ( t i − t i ∗ ) L_{reg}(t_i,t_i^*)=R(t_i-t_i^*) Lreg(ti,ti∗)=R(ti−ti∗)。
3.4RPN的两个并行支路
首先看之前给过的图的RPN部分

这两个支路中的上面支路用来分类前背景,下面支路用来回归框的位置(xyw宽h高定义了一个框)。
假设每个点对应k个anchors(9个),则边界支路reg层输出通道数是4×k,分类支路cls层输出通道数是2×k(评估是/否物体的概率)。然后把这两个支路整合一下 L o s s = L o s s l o c / r e g + L o s s c l s Loss=Loss_{loc/reg}+Loss_{cls} Loss=Lossloc/reg+Losscls,这样我们就利用RPN得到了一些含object的框。
3.5 RPN的Loss Function
RPN的Loss由边框位置loss和分类loss组成
因为此时我们分类仅仅区分前景背景,需要定义一个正标签是什么
一:两种anchors被标记为正类label=1, p ∗ = 1 p*=1 p∗=1:**(1)与真实box有最高的IoU重合度(也许不到0.7),(2)与任意any真实box的IoU重叠度大于0.7。*
这样一个真实box可能被赋给多个anchor正标签。通常第二种情况用来分辨正类已经足够了,但是仍然采用第一种的原因是如果全部框的IoU重合度都不大于0.7,那么我们就没框了,序号(1)是为了至少有个框。
二:与所有真实box的IoU重叠度小于0.3的anchor被标记为负类label=0,。此外观察一下框回归函数我们会发现只有正标签前景才会计算回归loss,因为loss里乘了 p ∗ = 0 p*=0 p∗=0。
三:剩下不是正类也不是负类的anchor对训练没有影响label=-1。此外覆盖到feature map边界线上的anchor也不参与训练。
通过IoU会把anchor分为正、负、不参与训练的标签,此外,全部anchors拿去训练还是太多了,训练的每个mini batch会在合格的的anchors中随机选取128个postive anchors+128个negative anchors进行训练RPN的cls+reg结构
到了reference阶段,则直接输出最高score的300个proposal。inference时由于没有了监督信息,所有RPN并不知道这些proposal是否为前景,整个过程只是惯性地推送一波无tag的proposal给后面的Fast R-CNN。

由于在实际过程中, N c l s = 256 , N r e g = 2400 N_{cls}=256,N_{reg}=2400 Ncls=256,Nreg=2400差距过大,用参数λ平衡(如 λ = N r e g = 2400 N c l s = 256 = 10 λ=\frac{N_{reg}=2400}{N_{cls}=256}=10 λ=Ncls=256Nreg=2400=10 ),使总的网络Loss计算过程中能够均匀考虑2种Loss。
R代表的是smooth L1函数。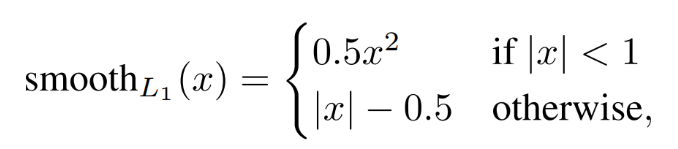
3.6 Loss训练的结果
这样重新生成60×40×9(~21k)个anchor box,然后取前景得分最高的N个:RPN_PRE_NMS_TOP_N = 12000(测试阶段为6000个),再经过NMS,经过NMS后再去前景最高的M个:RPN_POST_NMS_TOP_N = 2000(测试阶段为300个),这M个作为RoI。
下面把我对RPN这个阶段前后的理解说下
首先2W个anchors,只有IoU>0.7和<0.3的才有机会参与训练,赋label,其余的赋个无用lable,此外跨越边界的也赋无用label(否则在训练过程中会产生较大难以处理的修正误差项);对应anchor target layer
每个minibatch从这些中挑选RPN_BATCHSIZE=128+128个去真正训练RPN,
训练结束,进行前向传播得到了80×60×9≈2W个anchors,拿IoU排序后PRE_nms_top_n=1W2个【 6000/12000(test/train)】有机会参与NMS,NMS(0.7阈值)后又进行了排序取前POST_nms_top_m=2K个。【300/2000(test/train)】。对应proposal layer
得到了2000个proposals或者roi后,再从中正负样本比1:3地选择也是BATCH_SIZE=128个进行后面细分网络的训练,在此处正样本的IoU阈值是0.5。不过这256的正负样本挑选比例变成了1:3,正样本最多占0.25。对应proposal target layer
我的问题是:每次排序且不是将最有可能是背景的roi都过滤掉了?那这样不是把判断为背景的信息搞没了?所以排序取TOP后这里不应该都是前景?哪来的背景roi?而且背景也没有框信息。怎么训?
4:RPN后的识别
因为RPN之后的网络有全连接层,所以需要进行RoI操作。
- proposal是对应M×N尺度的,所以首先使用spatial_scale参数将其映射回(M/16)×(N/16)大小的feature map尺度
- 再将每个proposal对应的feature map区域水平分为 pooled_w×pooled_h的网格;
- 对网格的每一份都进行max pooling处理。
这样处理后,即使大小不同的proposal输出结果都是 pooled_w×pooled_h 固定大小,实现了固定长度输出。接下来进行分类
跟RPN部分同理,此时利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。

如果你直接翻到这里,可能不懂RoI Pooling,RoIpooling是为了连接后面的FC层,细节可看fast R-CNN的部分(可能需要从SPP部分才能深刻理解),这部分也可以百度,还算简单。pooling这里在maskR-CNN中被改进为AlignPooling
然后我们利用后面的网络进行真正的分类,此时我们不是仅仅区分前背景了,还要区分阿猫阿狗。
但我们此时可能有疑问,那此不是有两个地方有Loss?RPN的Loss和最后识别的Loss。怎么反向回归?文章利用的是交替训练的方法。
5:模型学习:交替式4步法训练
- 5.1 用ImageNet模型初始化,独立训练一个RPN网络
- 5.2 仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个fast rcnn网络,至此,两个网络的每一层的参数完全不共享。
- 5.3 使用第二部的fast rcnn网络参数初始化一个新的RPN网络,但是RPN和fast rcnn共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络共享了所有公共的卷积层。
- 5.4 仍然固定共享的那些网络层,把fast rcnn特有的网络层也加入进来,形参一个unified network,继续训练,fine-tune fast rcnn特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposals并实现检测的功能。
Detail:
RPN与检测网络共享卷积部分,节省计算。但没能实现实时检测
分类网络的梯度不向RPN回传
只有在train时,cls+reg才能得到强监督信息(来源于ground truth)。即ground truth会告诉cls+reg结构,哪些才是真的前景,从而引导cls+reg结构学得正确区分前后景的能力;在reference阶段,就要靠cls+reg自力更生了。
RPN的运用使得region proposal的额外开销就只有一个两层网络。
在train阶段,会输出约2000个proposal。到了reference阶段,则直接输出最高score的300个proposal。inference时由于没有了监督信息,所有RPN并不知道这些proposal是否为前景,整个过程只是惯性地推送一波无tag的proposal给后面的Fast R-CNN。

6:Faster R-CNN总结:
- Fater R-CNN效果

- RoI pooling存在的问题:(mask RCNN解决)
由于预选ROI的位置通常是有模型回归得到的,一般来说是浮点数,而赤化后的特征图要求尺度固定,因此ROI Pooling这个操作存在两次数据量化的过程。1)将候选框边界量化为整数点坐标值;2)将量化后的边界区域平均分割成kxk个单元,对每个单元的边界进行量化。事实上,经过上面的两次量化操作,此时的ROI已经和最开始的ROI之间存在一定的偏差,这个偏差会影响检测的精确度。

config文件解读
首先在config中文件中区分了TRAIN阶段和TEST阶段所用的参数,下面注意前缀是训练还是测试阶段的。
输入图像缩放的尺寸:TRAIN.SCALES = (600,) 为 短边放缩到的尺寸。TRAIN.MAX_SIZE = 1000为大边的阈值,不能超过这个值。测试时不变
9个anchor设置的scale和ratio。ANCHOR_SCALES = [8,16,32]。ANCHOR_RATIOS = [0.5,1,2]
正负类label的赋值:RPN中正类的界限为TRAIN.RPN_POSITIVE_OVERLAP = 0.7,负类TRAIN.RPN_NEGATIVE_OVERLAP = 0.3。fast中大于TRAIN.FG_THRESH = 0.5 # 大于0.5的认为是正类。在这个区域认为是负类TRAIN.BG_THRESH_HI = 0.5,TRAIN.BG_THRESH_LO = 0.1。
两个batchsize:在config文件中,有两个batchsize,一个是RPN的TRAIN.RPN_BATCHSIZE = 256。另一个是后面fast分类网络的TRAIN.BATCH_SIZE = 128,应用在proposal_target_layer中的rois_per_image 上。
batchsize中正负样本的比例:在RPN的batchsize中正类的比例:TRAIN.RPN_FG_FRACTION = 0.5。在fast 的batchsize中正类的比例TRAIN.FG_FRACTION = 0.25
非极大值抑制:在RPN后的NMS阈值为TRAIN.RPN_NMS_THRESH = 0.7。测试阶段不变。
NMS前后得分排序后取的数目为:TRAIN.RPN_PRE_NMS_TOP_N = 12000。TRAIN.RPN_POST_NMS_TOP_N = 2000。测试阶段分别变为TEST.RPN_PRE_NMS_TOP_N = 6000,TEST.RPN_POST_NMS_TOP_N = 300
RoIpooling后的尺寸POOLING_SIZE = 7。
anchor,proposal,rois ,boxes 代表的含义其实都是一样的,都是推荐的区域或者框,不过有所区别的地方在于这几个名词有一个递进的关系,最开始的是锚定的框 anchor,数量最多有约20000个(根据resize后的图片大小不同而有数量有所变化),然后是RPN网络推荐的框 proposal,数量较多,train时候有2000个,最后是实际分类时候用到的 rois 框,每张图片有256个;最后得到的结果就是 boxes。
参考:
B站视频:python tensorflow图像处理
https://zhuanlan.zhihu.com/p/31427164 #解读非常好,点进去看专栏
www.zhuanzhi.ai #专知-深度学习:算法到实践
https://cloud.tencent.com/developer/article/1015122
https://blog.csdn.net/wakojosin/article/details/79363224 #RPN
https://blog.csdn.net/mllearnertj/article/details/53709766 #RPN
https://blog.csdn.net/WZZ18191171661/article/details/79439212
http://www.cnblogs.com/zf-blog/p/7286405.html #rpn代码理解
https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/
https://blog.csdn.net/v1_vivian/article/details/73275259
https://blog.csdn.net/xiamentingtao/article/details/78598027
https://github.com/deepsense-ai/roi-pooling
http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b
代码的一些内容:
_ratio_enum
给定一正方形x1y1x2y2,然后根据这个正方形变成同面积scale的、三种长宽比ratio的框。相当于输入1个正方形,输出1个正方形+2个长方形。但在这个函数中实现的主要功能是得出3种wshsxcyc(ws为一行,hs为第二行…)。然后以此调用_mkanchors函数,让anchor各成一行(anchor1为第一行,anchor2位第二行…)
_mkanchors
给定ws,hs,xc,yc,每个部分的shape此时还是(3,),如ws=[23 16 11] ,但我们像把ws的第一个元素赋予第一个anchor,以便每行表示1个anchor,而不是每列。具体步骤是输入ws=[23 16 11] ,变成ws[[23],[16],[11]],以便在每个数字后面增加hxcyc,如[[第一个anchor:ws=16,hs,xc,yc],[第2个anchor],[第3个anchor]],这样每个anchor是一行元素,返回的是x1y1x2y2形式
from __future__ import print_function
import numpy as np
try:
xrange # Python 2
except NameError:
xrange = range # Python 3
# 注:anchors在这个.py中,表示形式都是x1y1x2y2。wh只是过渡
# 第1个调用函数
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2**np.arange(3, 6)):
# base_size=16 代表feature map上一个点对应原图16×16的区域,经历了4次pool
# ratios=[0.5,1,2] 代表的是anchors框的长宽比1:2,1:1,2:1
# base_size/根号ratios 即可得出base_size有3种框23:12,16:16,11:22
# scales 代表在base_size的anchor框基础上需要放大的倍数[8,16,32]
# base_size×scales 即(16*8)*(16*8)=128*128,(16*16)*(16*16)=256*256,(16*32)*(16*32)=512*512,这是原图上框的尺寸。这么定义的原因是考虑到在base_size基础上扩大以覆盖全图
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window.
"""
base_anchor = np.array([1, 1, base_size, base_size]) - 1
# [0,0,15,15],代表这个区域左上角和右下角坐标
ratio_anchors = _ratio_enum(base_anchor, ratios) #参数16,[0.5, 1, 2]
# 返回一个scale下三种ratio的anchor
# ratio_anchors=
#[[ -3.5 2. 18.5 13. ]
# [ 0. 0. 15. 15. ]
# [ 2.5 -3. 12.5 18. ]]
# ratio_anchors.shape[0]=3
anchors = np.vstack(
[ _scale_enum(ratio_anchors[i, :], scales) for i in xrange(ratio_anchors.shape[0])]
) # 竖直方向上叠加
# [[ -84. -40. 99. 55.]
# [-176. -88. 191. 103.]
# [-360. -184. 375. 199.]
# [ -56. -56. 71. 71.]
# [-120. -120. 135. 135.]
# [-248. -248. 263. 263.]
# [ -36. -80. 51. 95.]
# [ -80. -168. 95. 183.]
# [-168. -344. 183. 359.]]
return anchors
# 第2个调用函数
def _whctrs(anchor): # 把anchor的x1y1x2y2换算成了wh和中心坐标
"""
Return width, height, x center, and y center for an anchor (window).
"""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
# 第3个调用函数
def _ratio_enum(anchor, ratios): # [0,0,15,15],[0.5, 1, 2]
"""
Enumerate a set of anchors for each aspect ratio wrt an anchor.
"""
w, h, x_ctr, y_ctr = _whctrs(anchor)
# _whctrs函数把anchor的x1y1x2y2换算成了wh和中心坐标
size = w * h #size:16*16=256
size_ratios = size / ratios #256/ratios[0.5,1,2]=[512,256,128]
# 相当于w/根号ratios
ws = np.round(np.sqrt(size_ratios)) #np.round()四舍五入,np.sqrt()开方ws:[23 16 11]
hs = np.round(ws * ratios) #hs:[12 16 22],ws和hs一一对应。23&12
#给定一组宽高向量,输出各个预测窗口,也就是将(宽,高,中心点横坐标,中心点纵坐标)的形式,转成
#四个坐标值的形式
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
# 将whx_cy_c变量坐标变成一组x1y1x2y2,这一组的w×h是相同的
return anchors #返回到generate_anchors函数
# 第4个调用函数
def _mkanchors(ws, hs, x_ctr, y_ctr):
# ws=[23 16 11] hs=[12 16 22]
"""
Given a vector of widths (ws) and heights (hs) around a center
(x_ctr, y_ctr), output a set of anchors (windows).
"""
ws = ws[:, np.newaxis] # np.newaxis相当于None,相当于增加了一维
# ws=[23 16 11] ws=[[23], [16], [11]]
hs = hs[:, np.newaxis]
anchors = np.hstack((x_ctr - 0.5 * (ws - 1), # 水平方向平铺,注意括号层数,括起来相当于一个参数
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1) ))
# anchors= [[-3.5,2,18.5,13]
# [0,0,15,15]
# [2.5,-3,12.5,18]]
return anchors #x1y1x2y2
# 第5个调用函数,调用重复3次,3次后generate也完成了工作
def _scale_enum(anchor, scales):
"""
Enumerate a set of anchors for each scale wrt an anchor.
"""
# anchor=[ -3.5 2. 18.5 13. ] scales=[8,16,32]
# 每次_scale_enum函数完成的是:给定框宽高比ratio,返回这种比例所有scale的框
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales # [ 184. 368. 736.]
hs = h * scales # [ 96. 192. 384.]
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
# [[ -84. -40. 99. 55.]
# [-176. -88. 191. 103.]
# [-360. -184. 375. 199.]]
return anchors
if __name__ == '__main__':
import time
t = time.time()
a = generate_anchors() # 入口
print(time.time() - t)
print(a)
from IPython import embed; embed()
附generate_anchors.py运行结果
| base_anchor | ratios | (宽,高,xc,yc) | 坐标 |
|---|---|---|---|
| [184,96,7.5,7.5] scale=8 | [ -84. -40. 99. 55.] | ||
| 23×12(2:1) | [368,192,7.5,7.5] scale=16 | [-176. -88. 191. 103.] | |
| [736,384,7.5,7.5] scale=32 | [-360. -184. 375. 199.] | ||
| [128,128,7.5,7.5] scale=8 | [ -56. -56. 71. 71.] | ||
| 16×16 | 16×16(1:1) | [256,256,7.5,7.5] scale=16 | [-120. -120. 135. 135.] |
| [512,512,7.5,7.5] scale=32 | [-248. -248. 263. 263.] | ||
| [88,176,7.5,7.5] scale=8 | [ -36. -80. 51. 95.] | ||
| 11×22(1:2) | [176,352,7.5,7.5] scale=16 | [ -80. -168. 95. 183.] | |
| [352,704,7.5,7.5] scale=32 | [-168. -344. 183. 359.] |
















 1597
1597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









