







原文链接:https://www.techbeat.net/article-info?id=4293&isPreview=1
作者:章如锋
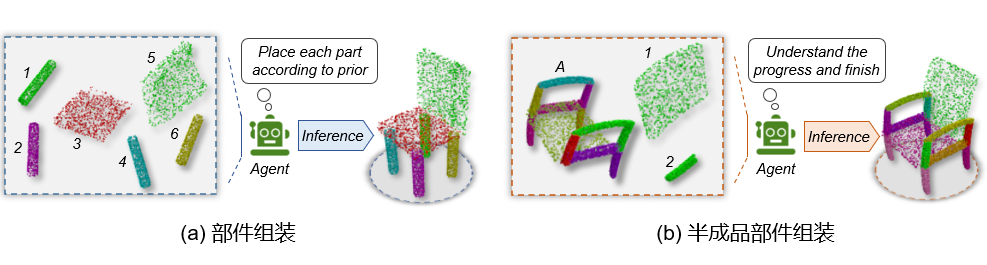
自动化零件装配是机器人三维视觉中的一项重要技术,也是现代化智能机器人的一个关键功能,可应用于机器人家具组装、复杂工业产品批量生产等多个领域。在最近的IROS 2022 (IEEE/RSJ International Conference on Intelligent Robots and Systems) 机器人顶级会议上,字节跳动人工智能实验室联合同济大学的研究者提出了一种基于实例编码的零件装配方法,能够在从0到1或从0.5到1的不同初始化状态下从刚体部件点云中学习零件外形、接触点的对应关系,输出部件级别的位姿信息,最终交由机器人执行。

论文链接:
https://arxiv.org/abs/2207.01779
一、研究背景
给定任意数量的形状、结构各异的刚体部件,让智能机器人从头开始组装,并得到连接良好、结构稳定的家具是一个繁琐且耗时的过程。现有的零件装配方法大致可以被分为两类。第一类方法主要利用机器人学中的运动规划和执行器控制等。这类方法首先为指定目标配置一套专属的执行指令,通过不断尝试反复调整指令,往往可以在相关目标上取得较高的准确率,但几乎没有泛化性,无法将其算法轻易地拓展至新目标。
第二类方法强调零件装配的联合姿态估计。其中一部分工作通过从一个大型的零件库中搜索目标零件来实现零件装配;另一些工作利用概率图首先预测各个零件的语义类别,进而作出位姿判断。这类工作要么依赖于大型的第三方数据库,或者假设零件语义类别已知,抑或是零件形状可变(非刚体),因此其泛化性也很难得到保障。
最近,一些工作尝试在更实际的背景下解决这个问题。在没有任何先验知识的前提下将任意数量的部件作为输入,进而估计出结构稳定的刚体形状变换。然而,在语义类别未知的前提下,部分几何形状相似的零件输入会产生“歧义”,致使算法做出不准确甚至相反的预测,其性能往往不尽如人意。因此,现有的几种范式均存在不同程度上的缺点,进而影响自动化零件装配的准确性和泛化性。
二、本文方法
针对部件语义类别未知及几何形状相似而导致的“歧义”问题,本文提出了一种实例编码的解决方法。该编码由两部分组成:类间编码和类内编码。在类间编码中,本文将每个零件视为一个单独的类别,并用长度为零件个数的01向量对其编码;此时每个部件都具备其独特的属性并非常易于区分。在类内编码中,本文为几何形状完全相同的零件编码了相同的属性(这表明它们具备相同的作用,如四条椅子腿),强化了这些高度相关部件间的联系。
基于此编码,本文进一步提出利用多层的Transformer网络建模零件间的几何/位姿关系,从粗到细地优化六自由度刚体变换。在训练和测试阶段,模型的目标都是将一系列语义未知、个数可变的3D零件输入到网络中,通过端到端的学习和预测,输出各个部件的刚体旋转和平移向量,最终实现整体的部件组装。
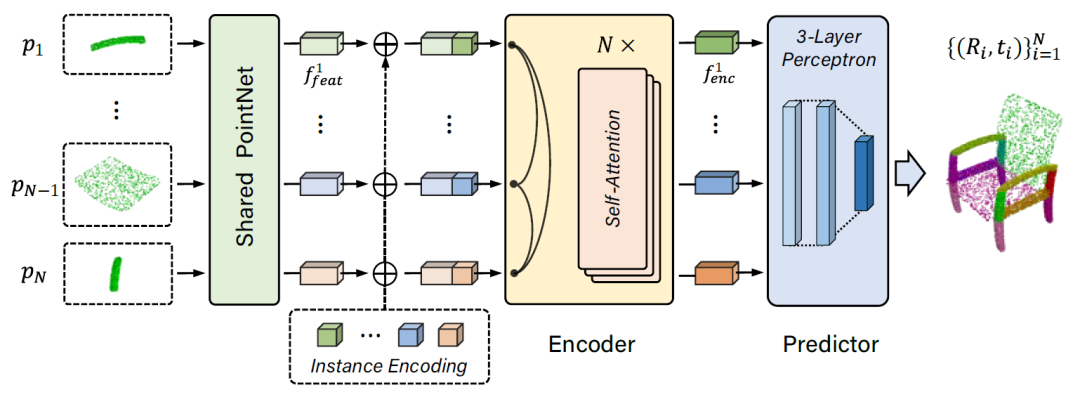
方法首先采用PointNet来提取每个部件点云的特征,之后采用提出的实例编码技术来对每一个点云部件进行编码,编码后的点云会输入到Transformer来学习不同部件之间的特征和关系。值得一提的是,因为本文提出的实例编码已经包含了部件之间的相对关系,作者去掉了Transformer中原来的位置编码。当部件的特征经过多层Transformer之后,会进一步接入到一个权重共享的MLP模块来预测每个部件最终的位姿Rt。为了对模型进行训练,作者采用Euclidean loss和Chamfer distance分别监督训练平移变换t和旋转变换R,整个模型采用端到端的方式进行联合训练。
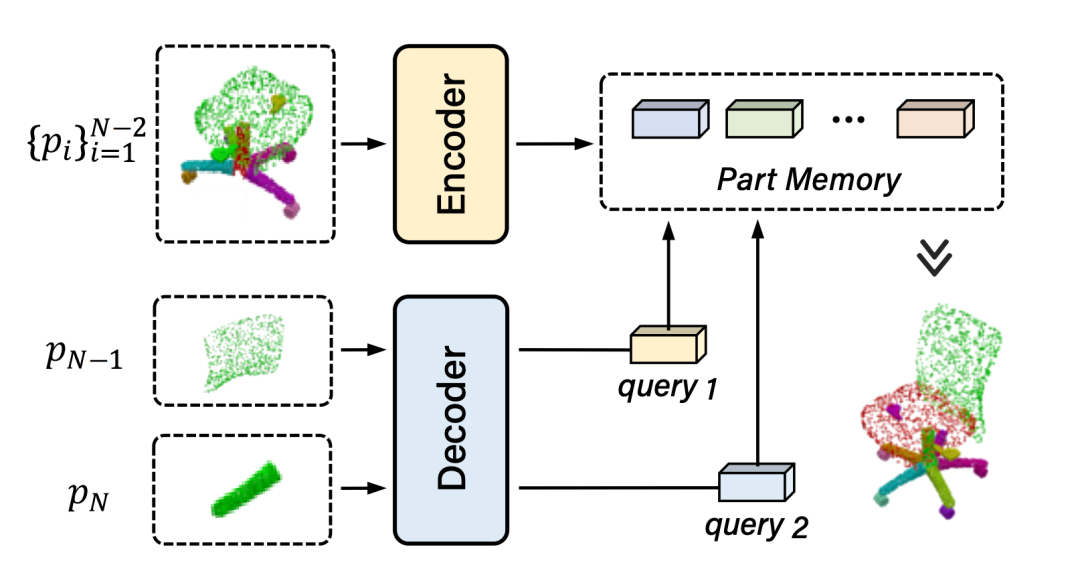
除此以外,相比于现有的方法只能从头开始组装部件,本文所提出的方法可以在半成品的基础上继续组装部件,具体来讲会对准备组装的新部件会进行信息解码,通过计算与已有部件模型的关系,来输出新部件的位姿,从而大大增加了算法的泛化性。
三、实验和结果
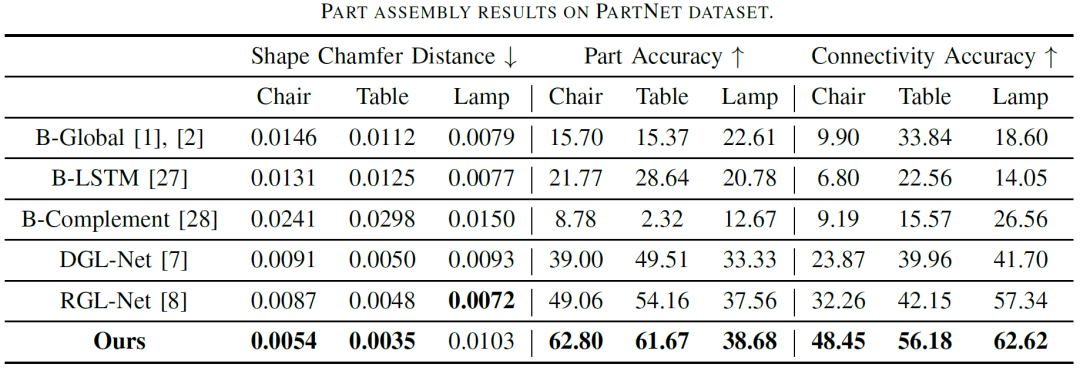
算法在公开数据集 PartNet 中进行测评,达到业界领先水平,相比于之前的最好方法,综合性能提升了10%以上!相比于以往方法,本文提出的方法可以更好地适应结构稳定的物品,比如椅子、桌子和台灯的装配。
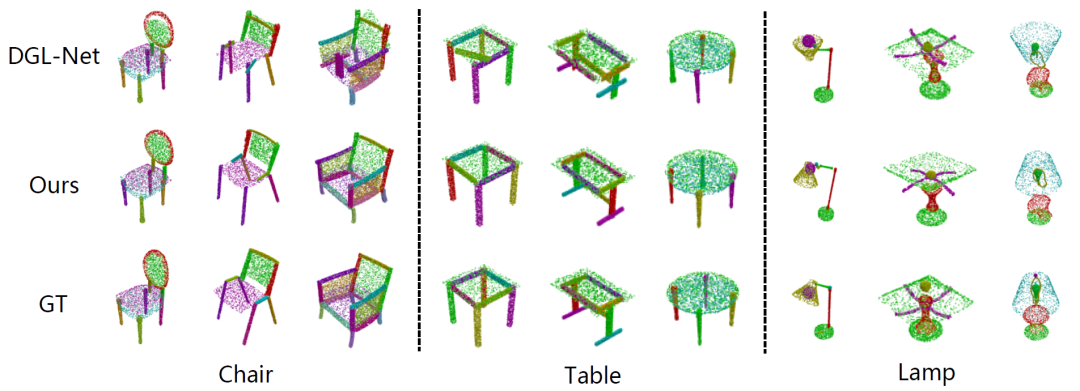
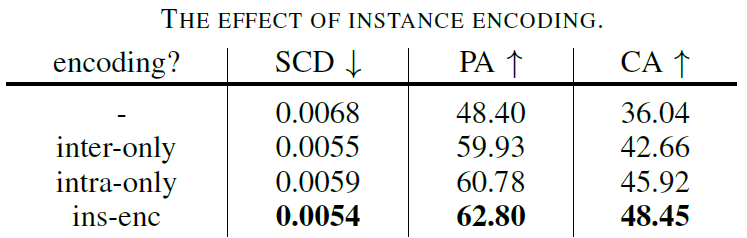
同时,本文通过消融实验证明实例编码对部件装配的重要性。作者还在Transformer和GNN两种主流结构上进行了对比,证明了该方法在Transformer上更具备优势。
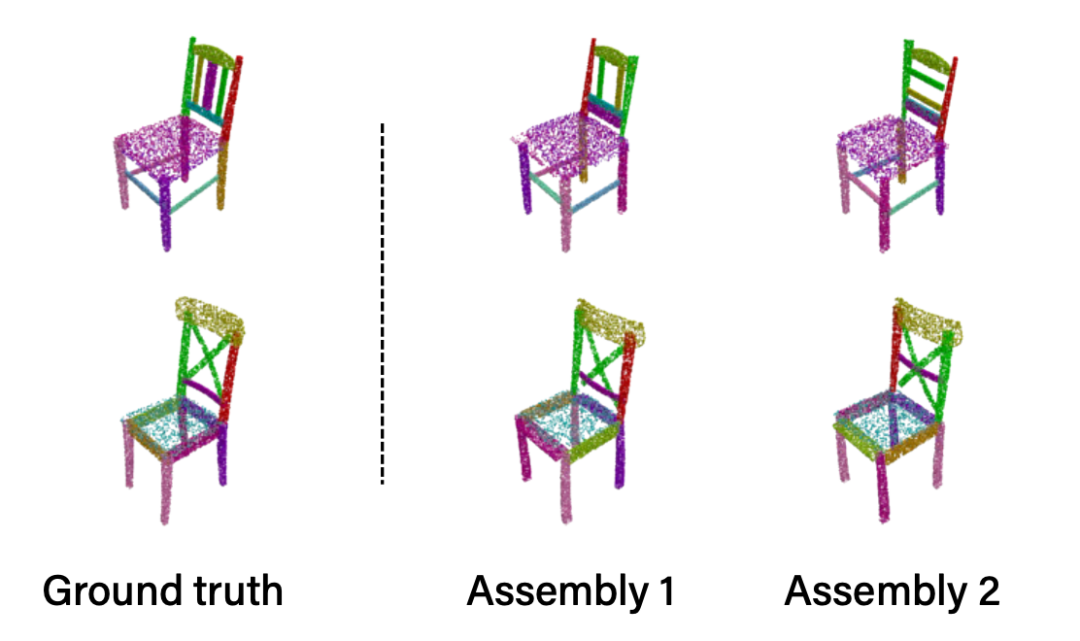
该方法针对同一把椅子,甚至可以有多种组装方式,组装出来的结果也是合理有效的。
四、 总结和展望
赋予机器人自动根据物料进行组装的能力是自动化装配中重要的研究目标。本文提出了一种用于零件装配的实例感知关系推理框架,并在常规的从头开始的装配任务中达到业界领先水平,相比于过去的方法,在组装效果上提升了10%。作者进一步结合最新的Transformer提出了半成品装配的任务和方法,拓展了自动装配的可能性。在未来的工作中,作者会结合仿真数据和真实环境来进一步提升算法的性能和可拓展性,也希望能够在真实环境中完成更加复杂的任务。
参考文献
[1] J. Li, C. Niu, and K. Xu, “Learning part generation and assembly for structure-aware shape synthesis,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 362–11 369.
[2] N. Schor, O. Katzir, H. Zhang, and D. Cohen-Or, “Componet: Learning to generate the unseen by part synthesis and composition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8759–8768.
[3] J. Huang, G. Zhan, Q. Fan, K. Mo, L. Shao, B. Chen, L. Guibas, and H. Dong, “Generative 3d part assembly via dynamic graph learning,” The IEEE Conference on Neural Information Processing Systems (NeurIPS), 2020.
[4] A. Narayan, R. Nagar, and S. Raman, “Rgl-net: A recurrent graph learning framework for progressive part assembly,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 78–87.
[5] R. Wu, Y. Zhuang, K. Xu, H. Zhang, and B. Chen, “Pq-net: A generative part seq2seq network for 3d shapes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 829– 838.
[6] M. Sung, H. Su, V. G. Kim, S. Chaudhuri, and L. Guibas, “Complementme: Weakly-supervised component suggestions for 3d modeling,” ACM Transactions on Graphics (TOG), vol. 36, no. 6, pp. 1–12, 2017.
[7] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
Illustration by Vijay Verma from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com















 3968
3968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









