









解读高赞ControlNet文章,主要内容是ControlNet的实现原理和种类。

🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
扩散模型相关知识点参考:小白也能读懂的AIGC扩散(Diffusion)模型系列讲解
目录
T2l-Adapter使用详解——另一种ControlNet模型
使用多个ControlNet(Multi ControlNet)
基于Stable Diffusion训练自己的ControlNet模型
ControlNet核心基础原理
ControlNet是一种“辅助式”的神经网络模型结构,通过在Stable Diffusion模型中添加辅助模块,从而引入“额外条件”来控制AI绘画的生成过程。
下图是ControlNet模型的最小单元:

从上图可以看到,在使用ControlNet模型之后,Stable Diffusion模型的权重被复制出两个相同的部分,分别是“锁定”副本(locked)和“可训练”副本。
ControlNet主要在“可训练”副本上施加控制条件,然后将施加控制条件之后的结果 和 原来SD模型的结果相加(addd)获得最终的输出结果。
其中“锁定”副本中的权重保持不变,保留了Stable Diffusion模型原本的能力;与此同时,使用额外数据对“可训练”副本进行微调,学习我们想要添加的条件。因为有Stable Diffusion模型作为预训练权重,所以我们使用小批量数据集就能对控制条件进行学习训练,同时不会破坏Stable Diffusion模型原本的能力。
另外,ControlNet模型的最小单元结构中有两个zero convolution模块,它们是1×1卷积,并且权重和偏置都初始化为零。这样一来,在我们开始训练ControlNet之前,所有zero convolution模块的输出都为零,使得ControlNet完完全全就在原有Stable Diffusion底模型的能力上进行微调训练,不会产生大的能力偏差。
这时很多人可能就会有一个疑问,如果zero convolution模块的初始权重为零,那么梯度也为零,ControlNet模型将不会学到任何东西。那么为什么“zero convolution模块”有效呢?(AIGC算法面试必考点)
我们看一下下面的推导,一切都会非常清晰明了:
【总结:这种推导的目的在于说明,通过梯度下降,即便权重最初为零,只要输入 X 不为零,模型中的权重会逐渐被学习为非零值,从而使网络能够有效学习。】
所以,如果我们不使用ControlNet模型时,可以将图像生成过程表达为:

我们假设将训练的所有参数锁定在 中,然后将其克隆为可训练的副本
。复制的
使用外部条件向量 c 进行训练。制作副本而不是直接训练原始权重主要是为了避免数据集较小时的过拟合,并保持从数十亿张图像中学习到的大型模型的能力。
所以在使用ControlNet之后,整体的图像生成表达式转化成为:

其中 Z=F(c;Θ) 代表了zero convolution模块, 和
代表zero convolution的参数权重,
代表ControlNet的参数权重。
由于训练开始前zero convolution模块的输出都为零,所以ControlNet未经训练的时候输出为0:

这种情况下对SD模型是没有任何影响的,就能确保SD模型原本的性能完整保存,之后ControlNet训练也只是在原SD模型基础上进行优化。ControlNet模型思想使得训练的模型鲁棒性好,能够避免模型过度拟合,并在针对特定问题时具有良好的泛化性,在小规模甚至个人设备上进行训练成为可能。
ControlNet核心网络结构解析
上面学习了ControlNet核心基础原理与ControlNet最小单元,接下来详细讲解ControlNet的完整核心网络结构。

其主要在Stable Diffusion的U-Net中起作用,主要优化两部分
- 在U-Net的Encoder部分(12 个残差结构)和Middle部分(1个中间块中)进行复制训练
- 在U-Net的Decoder模块中通过skip connection加入了zero convolution模块处理后的特征
由于ControlNet训练与使用方法是与原始的Stable Diffusion U-Net模型进行连接,并且Stable Diffusion U-Net模型权重是固定的不需要进行梯度计算。这种设计思想减少了ControlNet在训练中一半的计算量,在计算上非常高效,能够加速训练过程并减少GPU显存的使用。
具体地,ControlNet包含了12个编码块和1个Stable Diffusion U-Net中间块的“可训练”副本。这12个编码块有4种分辨率,分别是64×64、32×32、16×16和8×8,每种分辨率对应3个编码块 。ControlNet的输出被添加到Stable Diffusion U-Net的12 个残差结构和1个中间块中。同时由于Stable Diffusion U-Net是经典的U-Net结构,因此 ControlNet架构有很强的兼容性与迁移能力,可以用于其他扩散模型中。
ControlNet的输入包括Latent特征、Time Embedding、Text Embedding以及额外的condition。其中前三个和SD的输入是一致的,而额外的condition是ControlNet独有的输入,额外的condition是和输入图片一样大小的图像,比如边缘检测图、深度信息图、轮廓图等。
ControlNet一开始的输入Condition怎么与SD模型的隐空间特征结合呢?在这里ControlNet主要是训练过程中添加了四层卷积层,将图像空间Condition转化为隐空间Condition。这些卷积层的卷积核为4×4,步长为2,通道分别为16,32,64,128,初始化为高斯权重,并与整个ControlNet模型进行联合训练。

总的来说,ControlNet的架构与思想,让其可以对图像的背景、结构、动作、表情等特征进行精准的控制。
【使用卷积层而非 VAE 编码器来处理图像空间的条件信息是为了保持条件信息的精确性、高效的特征提取和对齐、以及简化计算。卷积层能够直接提取和下采样条件信息,使之适应与 SD 模型隐空间结合的需求,同时确保条件在生成过程中的有效控制。】
接下来我们再讲解一下ControlNet的训练过程。在训练ControlNet模型的过程中,Stable Diffusion底模型权重不更新,只更新ControlNet模型权重。

ControlNet模型类型介绍
目前ControlNet有18种Control Type,分别是Canny,Depth,NormalMap,OpenPose,MLSD,Lineart,SoftEdge,Scribble/Sketch,Segmentation,Shuffle,Tile/Blur,Inpaint,InstructP2P,Reference,Recolor,Revision,T2I-Adapter,IP-Adapter
Canny使用详解
Canny边缘检测算法能够检测出原始图片中各对象的边缘轮廓特征,提取生成线稿图,作为SD模型生成时的条件。接着再设置不同的提示词,让SD模型生成构图相同但是内容不同的画面,也可以用来给线稿图重新上色。
Canny算法中一共有2种Preprocessor,分别是Canny和invert (from white bg & black line)。
如果输入的图像具有白色背景和黑色线条,我们可以使用invert。
Depth使用详解
Depth算法通过提取原始图片中的深度信息,能够生成和原图一样深度结构的深度图。其中图片颜色越浅(白)的区域,代表距离镜头越近;越是偏深色(黑)的区域,则代表距离镜头越远。
Depth算法一共有四种预处理器,分别是depth_leres,depth_leres++,depth_midas和depth_zoe。
depth_midas预处理器是经典的深度估计器,也是最常用的深度估计器。
NormalMap使用详解
NormalMap算法根据输入图片生成一张记录凹凸纹理信息的法线贴图
,通过提取输入图片中的3D法线向量,并以法线为参考重新生成一张新图,同时给图片内容进行更好的光影处理。法线向量图指定了一个表面的方向。在ControlNet中,它是一张指定每个像素所在表面方向的图像,法线向量图像素代表的不是颜色值,而是表面的朝向。
NormalMap算法的用法与Depth算法类似,都是用于传递参考图像的三维结构特征。NormalMap算法与Depth算法相比在保持几何形状方面有更好的效果,在深度图中很多细微细节并不突出,但在法线图中则比较明显。
法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果,非常适合CG建模师。
NormalMap算法一共有两种预处理器,分别具体是normal_bae预处理器和normal_midas预处理器。
Normal_Bae预处理器用于估计法线贴图,重点是解决了aleatoric不确定性问题,对图像的背景和前景都进行细节的渲染,这样能够较好完善法线贴图中的细节内容,建议默认使用这个预处理器。
OpenPose使用详解
OpenPose算法
包含了实时的人体关键点检测模型,通过姿势识别,能够提取人体姿态,如人脸、手、腿和身体等位置关键点信息,从而达到精准控制人体动作。除了生成单人的姿势,它还可以生成多人的姿势,此外还有手部骨骼模型,解决手部绘图不精准问题。
如下图所示,我们输入图像和Prompt,通过OpenPose算法精准识别后,得到骨骼姿势图,再用SD模型的文生图功能,通过Prompt描述主体内容、场景细节和画风后,就能得到一张同样姿势,但风格完全不同的人物图片:

OpenPose算法一共有六种预处理器,分别是OpenPose,OpenPose_face,OpenPose_faceonly,OpenPose_full,openpose_hand,dw_openpose_full。
每种OpenPose预处理器的具体效果如下:
- OpenPose预处理器是OpenPose算法中最基础的预处理器,能够识别图像中人物的整体骨架(眼睛、鼻子、眼睛、脖子、肩膀、肘部、腕部、膝盖和脚踝等);
- OpenPose_face预处理器是在OpenPose预处理器的基础上增加脸部关键点的检测与识别;
- OpenPose_faceonly预处理器仅检测脸部的关键点信息,如果我们想要固定脸部,改变其他部位的特征的话,可以使用此预处理器;
- openpose_full预处理器能够识别图像中人物的整体骨架+脸部关键点+手部关键点,是一个非常全面的预处理器;
- openpose_hand预处理器能够识别图像中人物的整体骨架+手部关键点;
- dw_openpose_full预处理器是目前OpenPose算法中最强的预处理器,是OpenPose_full预处理器的增强版,使用了传统深度学习中的王牌检测模型yolox_l作为人体关键点的检测base模型,其不但能够人物的整体骨架+脸部关键点+手部关键点,而且精细程度也比openpose_full预处理器更好。
MLSD使用详解
MLSD是一种线条检测算法,通过分析图片的线条结构和几何形状来构建出建筑外框(直线),它对于提取具有直边的轮廓非常有用,例如室内设计、建筑物、街景、相框和纸张边缘,但是对人或其它有弧度的物体边缘提取效果很差。
如果我们想要对室内、建筑等输入图片进行重构,原图环境中有人物出现,但是新生成的图片中不希望有人物,那么使用MLSD算法就可以很好的避开人物线条的检测,从而能够生成纯建筑的新图片。
总的来说,ControlNet MLSD算法非常适合用于室内设计、建筑设计等场景。mlsd预处理,mlsd_invert预处理两种。
Lineart使用详解
ControlNet Lineart算法(线稿模型)与Canny算法大同小异,可以检测出输入图像中的线稿信息。
Lineart算法一共有五种预处理器,分别是lineart_anime预处理器、lineart_anime_denoise预处理器、lineart_coarse预处理器、lineart_realistic预处理器和lineart_standard 预处理器。
下面是Lineart算法各预处理器的具体效果:
- Lineart_anime预处理器:用于生成动漫风格的线稿/素描信息。
- Lineart_anime_denoise预处理器:Lineart_anime预处理器的优化版,在提取动漫风格线稿/素描信息的同时进行降噪处理。
- Lineart_coarse预处理器:用于生成粗糙线稿/素描,线条相比较于其它预处理器,的确更粗一些,效果也很不错,生成的图像则趋于真实。
- Lineart_realistic预处理器:能较好地提取人物线稿部分。
- Lineart_standard(from white bg&black line)预处理器:是一种特殊模式,将白色背景和黑色线条的图像转换为线稿或素描,能较好的还原场景中的线条,跟原图较为相似。
SoftEdge使用详解
ControlNet SoftEdge算法的主要作用是检测图像的软边缘轮廓,与Canny算法相比检测出的边缘轮廓没有那么细致和严格,相对比较宽松和柔性。
SoftEdge算法一共有四种Preprocessor,分别是softedge_hed预处理器、softedge_hedsafe预处理器、softedge_pidinet预处理器以及softedge_pidinetsafe预处理器,其中带有“safe”字样的表示精简版。
softedge_hed预处理器跟Canny算法类似,也是一种边缘检测算法,可以把Canny算法理解为用铅笔提取边缘,而softedge_hed预处理器则是换用毛笔,被提取的图像边缘将会非常柔和,细节也会更加丰富,绘制的人物明暗对比明显,轮廓感更强,适合在保持原来构图的基础上重新着色和对画面风格进行改变。
如果是生成棱角分明或者机甲一类的图像,我们推荐使用Canny算法。如果是想要生成人物和动物等图像,使用softedge_hed预处理器效果会更好。
同样的,softedge_pidinet预处理器也是一种边缘检测算法,比起softedge_hed预处理器,它的泛化性与鲁棒性更强。
鲁棒性:SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
最好效果上限:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
一般情况下,我们默认使用 SoftEdge_PIDI。大多数情况下它的效果都很好。
Scribble/Sketch使用详解
Scribble/Sketch算法能够提取图片中曝光对比度比较明显的区域,生成
黑白稿,涂鸦成图,其比Canny算法的自由度更高,也可以用于对手绘线稿进行着色处理。
从下图可以看到提取的涂鸦,不但保留了曝光度对比较大的部分,而且细节保留的也很不错。细节保留的越多,那么SD重新生成图片时所能更改的部分就越少。当然的,我们也可以直接上传涂鸦,然后通过Scribble/Sketch算法进行补充绘图。
ControlNet Scribble/Sketch算法一共有四种预处理器,分别是:scribble_hed预处理器、scribble_pidinet预处理器、scribble_xdog预处理器以及t2ia_sketch_pidi预处理器。
- scribble_hed预处理器:由Holistically-Nested Edge Detection(HED) 边缘检测器构成,擅长生成像真人一样的轮廓,能够配合SD系列模型进行图像进行重新着色和重新设计样式等任务。
- scribble_pidinet预处理器:由Pixel Difference network(Pidinet) 网络构成,能够检测图像中曲线和直线边缘等特征。其结果与scribble_hed预处理器类似,但通常会产生更清晰的线条和更少的细节。
- scribble_xdog预处理器:由EXtendedDifferenceofGaussian(XDoG)技术构成,同样是一种图像边缘检测算法。与其他预处理器不同的是,scribble_xdog预处理器附带一个XDoG Threshold参数可供我们调整阈值,这让我们的控制效果更佳精细化。
- t2ia_sketch_pidi预处理器:t2ia_sketch_pidi预处理器在处理涂鸦图像时考虑一些特定的因素,例如涂鸦的形状、颜色、纹理等,以帮助算法更好地理解和利用图像中的信息(待确认补充)。
Segmentation使用详解
Segmentation算法是传统深度学习三大支柱(分类,分割,检测)核心之一,主要通过对图片内容(人物、背景、建筑等)进行语义分割,可以区分画面色块,适用于大场景的画风更改。
但是输入图像的所有精细细节和深度特征都会丢失,与此同时会生成多个与输入图像中的物体的形状基本保持一致的mask(掩膜)。ControlNet中的Segmentation算法天然地能够与SD系列模型的inpatinting相结合使用,后者需要输入mask,并对mask部分进行局部重绘,而Segmentation算法就能够自动提供相应的mask部分。Segmentation算法一共有三种预处理器,分别是seg_ofade20k预处理器、seg_ofcoco预处理器和seg_ufade20k预处理器。
整体上seg_ofade20k预处理器的效果是最好的。
接下来我们ControlNet Segmentation模型进行控制生成:
Shuffle使用详解
ControlNet中的Shuffle算法能够获取输入的参考图像的配色,并控制SD/SDXL模型生成相似配色方案的图像。与ControlNet其他的预处理方法相比,Shuffle算法非常简洁明了。使用Shuffle算法后,生成的每一张图片都有参考图像的配色特征,参考图像的画风一定程度上融合进了生成图像中。
目前Shuffle算法有一个预处理器:shuffle预处理器;同时有两个对应的ControlNet模型:control_v11e_sd15_shuffle.pth和control_v11e_sd15_shuffle.safetensors(FP16)。
Tile/Blur使用详解
【1】ControlNet中的Tile算法
ControlNet中的Tile算法和超分算法部分类似,能够增大图像的分辨率。但不同的是,ControlNet Tile算法在增加图像分辨率的同时,还能生成大量的细节特征而不是简单地进行插值。
总的来说,ControlNet中Tile算法有两种使用方法:
- 在图片尺寸不变的情况下,优化生成图片的细节。
- 在对图片尺寸进行超分的同时,生成相应的细节,完善超分后的图片效果。
由于Tile算法可以生成新的细节,因此我们可以使用该算法去除不良细节并添加更精致的细节。例如,消除因图像超分或者尺寸变化而导致的图像细节模糊的问题。
具体效果如下图所示:

目前Tile算法一共有三种预处理器,分别是tile_resample预处理器、tile_colorfix+sharp预处理器以及tile_colorfix预处理器。
目前Tile算法一共有两个模型,分别是control_v11u_sd15_tile模型和control_v11f1e_sd15_tile模型。
总的来说,Tile算法的功能主要有:
- 优化模糊、细节较差的图片。这个功能在图生图中也可以使用,区别在于图生图更改细节的同时,也会变更主体,加上Tile算法进行控制后,生成过程中主体不变。
- Tile算法+特定提示词来微调图像细节。
- 对图片进行超分辨率重建的同时,补充生成细节特征。
【2】ControlNet中的Blur算法
Blur算法通常用于降噪、图像平滑、简化图像细节、柔化边缘等。Blur算法有多种,每种都有其特定的应用和效果,常见的Blur算法有:均值Blur、高斯Blur、中值Blur、运动Blur等。
ControlNet中的Blur算法主要是用了高斯Blur作为预处理器(blur_gaussian),可以通过模糊输入图像的特征,从而进行重新生成质量更的图像,整体效果与用法和Tile算法类似。
Inpaint/outpaint使用详解
ControlNet Inpaint算法与Stable DIffusion系列模型原生的Inapinting操作一样,使用mask对需要重绘的部分进行遮盖,然后进行局部的图像重新生成。
ControlNet Inpaint模型是用50%随机mask和50%随机光流mask共同训练的。这意味着模型不仅支持常规的图像重绘应用,还可以处理视频光流变形任务。
与此同时,ControlNet Inpaint算法也可以进行扩充重绘(outpainting),比如说将人物半身图片扩充重绘成全身图片,将风景画的内容扩展补充,得到一个更大尺寸的图像。社交平台上时不时火一阵的AI扩图,其核心技术就是通过ControlNet Inpaint来实现。
目前ControlNet Inpaint算法中包含了三个预处理器,分别是inpaint_global_harmonious预处理器,inpaint_only预处理器以及inpaint_only+lama预处理器。对原始图片进行左右和上下方向的outpainting。
InstryctP2P使用详解
ControlNet InstryctP2P算法是一种通过提示词编辑图像的算法,在传统深度学习时代,著名的以GAN为核心的Pix2Pix模型就是图像编辑算法的代表。
ControlNet InstryctP2P模型是在Instruct Pix2Pix数据集上进行训练的。不过不同于原生的Instruct Pix2Pix模型,ControlNet InstryctP2P模型是使用50%的指令提示和50%的描述提示进行训练的。举个例子,“一个可爱的男孩”是一个描述提示,而“让这个男孩变得可爱”是一个指令提示。
ControlNet InstryctP2P算法不包含预处理器,目前只有一个control_v11e_sd15_ip2p模型。
Reference-only使用详解
Reference-only算法可以说是CotrolNet系列算法中的一个“异类”,它只有预处理器,没有对应的ControlNet模型,也就是说它不需要进行训练,而是一个纯算法。
Reference-only算法的预处理器能够直接使用输入的图像作为参考图(图像提示词)来控制SD模型的生成过程,类似于inpainting操作,从而可以生成与参考图像相似的图像。与此同时,SD模型在图像生成过程中仍会受到Prompt的约束与引导。
Reference-only算法的实现原理是通过将SD U-Net的自注意力模块与参考图像进行映射来实现的,我们先将参考图像加噪声送入U-Net中,提取在SelfAttention模块中的keys和values并与SD模型原本的特征叠加,这样一来就结合了自身特征和参考图特征,从而实现了无训练的参考图像特征作为图像提示词的功能逻辑。下面是Reference-only算法的实现流程图:
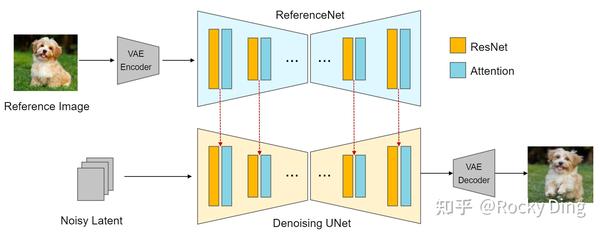
上面的示意图中为了方便观察设计了两个U-Net结构,实际上我们也可以用同一个U-Net实现,这样就不需要额外的ReferenceNet。在SD模型的Denoising循环中每一步先走上半部分的Reference过程,把需要“关联”的中间数据存起来,再走下半部分常规的Denoising过程,所以ControlNet中Reference-only算法不需要额外的模型支持。
总的来说,ControlNet Reference-only算法的整体流程完整包括:
- 输入参考图,使用VAE提取参考图的Latent特征。
- 使用SD系列模型进行文生图或者图生图任务,同时往U-Net架构中注入参考图的Latent特征。
- 参考图只在U-Net的Self-Attention层起作用,不影响Cross-Attention层。
- 调整参考图Latent特征与SD系列模型本身的图像特征之间的权重,逐步去噪生成图像。
ControlNet Reference-only算法中主要通过设计Style Fidelity参数,来控制参考图Latent特征与SD系列模型本身的图像特征之间的权重:
融合的自注意力机制 = style_fidelity * 融合自注意力机制 + (1.0 - style_fidelity) * 原始自注意力机制Reference-only算法一共包含三种预处理器,分别是reference_adain预处理器、reference_adain+attn预处理器和reference_only预处理器。
Recolor使用详解
Recolor算法主要起到对输入图像进行重新上色的效果。
目前Recolor算法有两个预处理器,分别是recolor_intensity预处理器和recolor_luminance预处理器。
recolor_intensity预处理器在提取图像特征时更注重颜色的饱和度。而recolor_luminance预处理器在提取图像特征时更注重颜色的亮度。
通常情况下选用recolor_intensity预处理器效果更好,ControlNet的Recolor算法用在颜色滤镜、老照片上色,局部颜色调整等领域非常有价值。
Revision使用详解
ControlNet里的Revision算法主要是在控制的过程中加入的“底图”,它用池化的CLIP Embedding来生成与输入“底图”概念相似的图像。Revision算法可以单独使用于SD系列模型的生成,也可以与提示词Prompt组合使用。
需要注意的是:Revision算法兼容Stable Diffusion和Stable Diffusion XL模型。
目前Revision算法一共有两种预处理器,分别是revision_clipvision预处理器和revision_ignore_prompt预处理器。
与此同时,Revision算法并不需要对应的ControlNet模型,因为其主要是对输入的图像进行处理,提取Embedding特征。
Revision算法不仅能提取一张图片的特征作为参考,也能将多张图片的特征提取后进行融合,多图像融合时各个图像的权重需要配置好,某个图像的权重配置的越高,那么其特征在融合生成后的图像中就越明显。
T2l-Adapter使用详解——另一种ControlNet模型
T2I-Adapter算法是由腾讯发布,和ControlNet模型一样,能够作为控制条件控制SD模型生成图片的过程。
下面是T2I-Adapter算法发挥作用的示意图:

T2I-Adapter算法的详细结构:

T2I-Adapter算法的一些特征:
- 即插即用:T2I-Adapter算法不会影响SD模型原本的生成能力。
- 简单且小巧:它们可以轻松地与SD模型结合,T2I-Adapter模型大约只有77M的参数和大约300M的存储空间。
- 灵活组合:可以轻松与多个ControlNet模型组合使用,以实现多条件控制。
- 泛化能力:在不同的SD模型上具备较好的泛化控制性能。
因为T2l-Adapter算法与ControlNet算法有很多相似的功能,所以在ContorlNet中一共集成了三种T2l-Adapter算法预处理器,分别是t2ia_color_grid,t2ia_sketch_pidi和t2ia_style_clipvision。
IP-Adapter使用详解——垫图
Stable Diffusion系列模型在正常情况下是只支持文本提示词的输入,而IP-Adapter算法能够在SD模型的图像生成过程中引入图像提示词(Image Prompt),从而能够识别输入图像的风格和内容,然后控制SD模型生成相似风格或者内容的图片,同时也可以搭配其他类型的ControlNet一起使用。

可以说IP-Adapter能让SD模型临摹艺术大师的作品,并且用在我们生成的图片中,在AI绘画开源社区中,大家给IP-Adapter算法的功能起了一个形象的名字:“垫图”。
接下来我们再看一下IP-Adapter算法的整体流程:

从上图可以看到,IP-Adapter算法主要分为三个步骤:
- 使用CLIP的Image Encoder模块提取图像特征。
- 使用CLIP的Text Encoder模块提取文本特征。
- 通过Cross Attention机制将图像特征和文本特征注入Stable Diffusion的U-Net中,用于引导图像的生成过程。
IP-Adapter算法的关键设计是解耦的交叉注意机制,它将文本特征和图像特征的交叉注意层分开。
知道了IP-Adapter算法的核心基础知识和整体流程,那么IP-Adapter算法和Stable Diffusion模型结合主要能干哪些有价值的事情呢?
- 可以同时使用图像提示词和文本提示词,引导图像的生成。
- 可以用于图生图以及图像inpainting。
- 与Stable Diffusion和Stable Diffusion XL模型同时适配,并且可以与其他ControlNet模型组合使用(T2I-Adapter)。
IP-Adapter算法一共有两个预处理器,分别是ip-adapter_clip_sd15预处理器(用于SD模型)和ip-adapter_clip_sdxl预处理器(SDXL模型)。
IP-Adapter模型一共有三个,分别是:
- ip-adapter_sd15:适用于Stable Diffusion 1.5模型。
- ip-adapter_sd15_plus:适用于 Stable Diffusion 1.5模型,能够细节更丰富的图像提示词,生成的图片和图像提示词的内容和风格更相似。
- ip-adapter_xl:适用于 Stable Diffusion XL模型。
下面我们来看看,我们以ip-adapter_clip_sd15预处理器和ip-adapter_sd15_plus模型为例,实现各种好玩的效果:
(1)只使用IP-Adapter算法进行文生图任务
(2)IP-Adapter算法+其他ControlNet进行文生图任务
(3)IP-Adapter算法进行换脸
(4)IP-Adapter算法对图像元素进行编辑
想要使用IP-Adapter算法对图像元素进行编辑,我们就需要文本提示词+图像提示词一起发挥作用。
我们可以看到下面的两个例子,在图生图中,使用IP-Adapter算法给第一幅图中的人物增加一顶帽子,将第二幅图片的背景设置为沙滩。

(5)IP-Adapter算法将图片主体特征相融合

使用多个ControlNet(Multi ControlNet)
叠加多个ControlNet模型有助于更加精细化的控制,从而有助于更好的提升SD生成图片的效果。所以我们在实际使用中,可以开启多个ControlNet对图像的生成过程进行多条件的控制。
假如我们想对一张图片中的人物姿态和背景分别进行控制,就可以分别配置OpenPose模型和Depth模型对人物姿态和背景结构进行提取与控制,并生成相同姿态和背景结构的新人物内容与新背景风格。
除此此外,我们在保持种子(seed)相同的情况下,固定出画面结构和风格,然后定义人物不同姿态,渲染后进行多帧图像拼接,就能生成一段动画啦。
下面是一个简单的使用多个ControlNet的例子:

基于Stable Diffusion训练自己的ControlNet模型
ControlNet模型训练流程
ControlNet系列模型的训练流程主要分成以下几个步骤:
- 设计我们想要的生成条件:除了上面章节中讲到的控制条件,我们还可以根据实际需求自定义一些条件,从而使用ControlNet控制Stable Diffusion朝着我们想要的方向生成内容。
- 构建数据集:确定好生成条件后,我们就可以开始构建数据集了。ControlNet数据集中需要包含三个维度的信息: Ground Truth图片、作为条件(Conditional)的图片,以及Prompt标签。
- 构建ground truth 图片 (
image):这里指的就是真实人脸图片 - 构建条件图片 (
conditioning_image):对应的条件图像 - 构建图片标签 (
caption):描述图片的文字
- 构建ground truth 图片 (
- 训练我们自己的ControlNet模型:数据集构建好后,我们就可以开始训练自己的ControlNet模型了,我们需要一个至少8G显存的GPU才能满足ControlNet模型的训练要求。
设计ControlNet的控制条件
我们设计ControlNet的控制条件可以说是整个流程中最重要的一环了,因为条件设计的好与坏,直接影响到我们训练的ControlNet模型的易用性与在开源社区爆火的可能性。
我们可以从以下两方面思考如何设计ControlNet的生成条件:
- 思考生成条件:我们需要哪些生成条件?哪些生成条件可以满足实际需求?比如电商场景的模特图控制,我们需要设计手部生成的控制条件;再比如泛娱乐场景,我们需要根据热点信息,设计对应的生成控制条件。
- 确定生成条件算法:在确定好生成条件后,我们需要确定将Ground Truth图片转换成条件(Conditional)图片的算法和模型。
在这里,Rocky拿人脸关键点作为控制条件举例。
人脸关键点控制可以应用在AI绘画领域几乎所有的场景中,是一个穿越周期的经典实用任务,所以训练人脸关键点ControlNet是有价值的,接下来我们需要获取训练数据中的人脸关键点信息,作为条件(Conditional)数据,我们可以使用传统深度学习时代的人脸关键点检测模型来提取人脸关键点信息。
人脸关键点特征提取过程
使用技巧
| 使用 🧨 Diffusers 实现 ControlNet 高速推理 在使用ControlNet进行稳定扩散的情况下,我们首先使用CLIP文本编码器,然后使用扩散模型unet和控制网,然后使用VAE解码器,最后运行安全检查器。 在DreamBooth中使用ControlNet(使用 Dreambooth 微调的 Stable Diffusion 模型作为基准模型) 多个ControlNet条件组合用于单个图像生成。 | https://huggingface.co/blog/zh/controlnet |
| 使用 diffusers 训练你自己的 ControlNet 🧨 使用diffusers训练模型 | https://huggingface.co/blog/zh/train-your-controlnet |
| 使用ControlNet生成图像 Text-to-image Image-to-image Inpainting Guess mode ControlNet with Stable Diffusion XL MultiControlNet | https://huggingface.co/docs/diffusers/using-diffusers/controlnet |
| 代码训练自己的ControlNet过程 | https://huggingface.co/docs/diffusers/training/controlnet |
| ControlNet源代码 | GitHub - lllyasviel/ControlNet: Let us control diffusion models! |


















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









