







Bag of Tricks for Image Classification with Convolutional Neural Networks
论文:https://arxiv.org/pdf/1812.01187.pdf
本文作者总结了模型训练过程中可以提高准确率的方法,如题,作者说 bag of tricks,阅读了一遍文章,有用的内容挺多,为了比赛上分,可以一试,总结如下。文中提到的方法在GLuonCV 0.3中有实现,可以参考这个源代码。
文中提到技巧不仅可以应用于图像分类任务中,还可以应用于图像识别和语义分割任务中。
有效训练
利用更大的batch size 进行训练,但利用更大的batch size使得验证集上的准确率降低,为解决这个问题,文中提出了四种解决方法,分别为:Linear scaling learning rate, Learning rate warmup, Zero γ \gamma γ ,No bias decay。具体可参考文中说明,实验结果如下,对准确率几乎无提升。

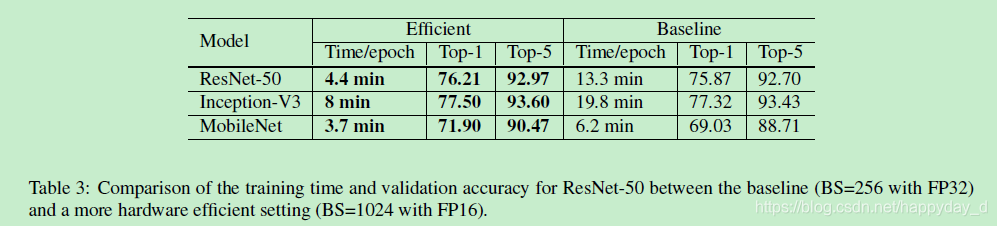
利用16位进行训练可有效的减少模型的训练时间,结果如下:
模型优化
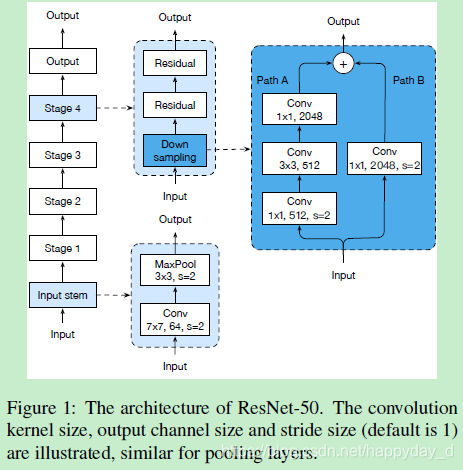
在ResNet的结构基础上调整了模型中间部分结构,下图为ResNet-50网络结构:
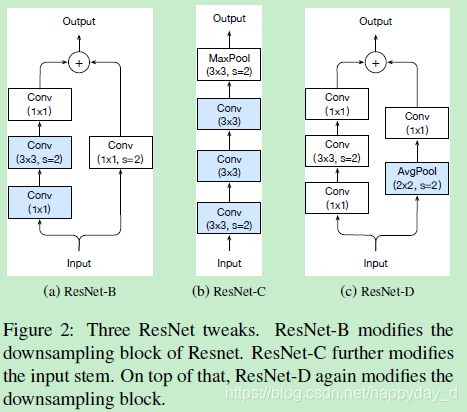
修改上图中的Down Sampling结构为下图中的ResNet-D,其中下图中的(a)是之前修改使用的模型,(b)是将输入部分的7x7卷积核换成了3x3卷积核,Inception-v2网络中有使用。
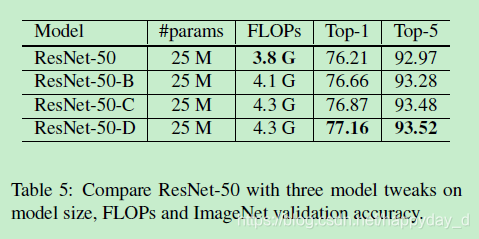
实验结果为下表,从表中可以看出修改模型后的准确率有较明显的提升。
训练过程优化
1) cos学习率衰减
常用的学习率衰减方法为“step decay”,如每过30个epochs,学习率乘以0.1,cos学习率衰减公式如下:
η
t
=
1
2
(
1
+
cos
(
t
π
T
)
)
η
\eta _ { t } = \frac { 1 } { 2 } \left( 1 + \cos \left( \frac { t \pi } { T } \right) \right) \eta
ηt=21(1+cos(Ttπ))η
其中,
T
T
T为总的batches数,t为第几个batch,
η
\eta
η为初始学习率,实验过程学习率变化如下图,cos学习率衰减方法在起始阶段,学习率衰减较慢,中间阶段趋于线性衰减,后序阶段衰减较快,认为该衰减方法有效的原因是cos衰减在训练没过多久学习率很大,而step方法的学习率降低很多,而起始阶段的高学习率可以加速训练过程。
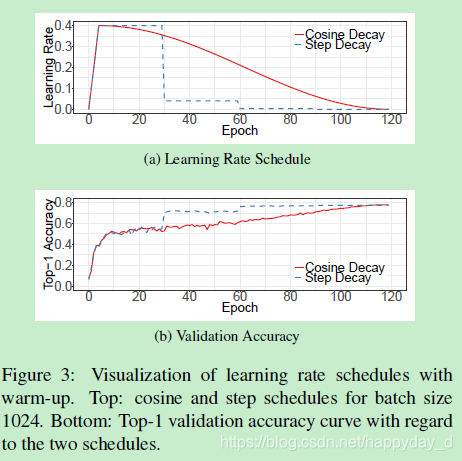
2) label 平滑
这个label平滑大致意思就是正常情况下真值是1,非真值是0,平滑处理后真值不等于1,变换方法如下:
q
i
=
{
1
−
ε
if
i
=
y
ε
/
(
K
−
1
)
otherwise
q _ { i } = \left\{ \begin{array} { l l } { 1 - \varepsilon } & { \text { if } i = y } \\ { \varepsilon / ( K - 1 ) } & { \text { otherwise } } \end{array} \right.
qi={1−εε/(K−1) if i=y otherwise
3) 知识蒸馏
利用教师模型来指导学生模型训练,教师模型是指对同一个任务准确率高的模型,例如,利用ResNet-152作为教师模型,ResNet-50作为学生模型,引入蒸馏损失函数来进行优化,公式如下:
ℓ
(
p
,
softmax
(
z
)
)
+
T
2
ℓ
(
softmax
(
r
/
T
)
,
softmax
(
z
/
T
)
)
\ell ( p , \text { softmax } ( z ) ) + T ^ { 2 } \ell ( \text { softmax } ( r / T ) , \text { softmax } ( z / T ) )
ℓ(p, softmax (z))+T2ℓ( softmax (r/T), softmax (z/T))
p
p
p表示真实值,
z
z
z表示学生模型预测输出,
r
r
r表示老师模型预测输出,
T
T
T为超参数,
ℓ
(
p
,
softmax
(
z
)
)
\ell(p,\text{softmax}(z))
ℓ(p,softmax(z))表示交叉熵损失函数;
4) 混合训练
混合的意思是给定两个值,根据给定的两个值获得一个新的值,利用如下公式:
x
^
=
λ
x
i
+
(
1
−
λ
)
x
j
y
^
=
λ
y
i
+
(
1
−
λ
)
y
j
\begin{array} { l } { \hat { x } = \lambda x _ { i } + ( 1 - \lambda ) x _ { j } } \\ { \hat { y } = \lambda y _ { i } + ( 1 - \lambda ) y _ { j } } \end{array}
x^=λxi+(1−λ)xjy^=λyi+(1−λ)yj
上述4个方法的实验结果如下,提到的方法对模型的准确率提升都有影响,而知识蒸馏方法对Inception-V3和MobileNet没有提升,文中的解释是使用Resnet-152作为教师模型,而和后两个模型属于不同的模型家族,预测结果的分布也不同,因此对后两个模型到来的负面的影响。
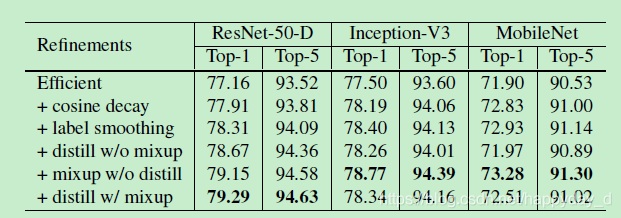
总结
本文从模型优化,学习率衰减,label平滑,知识蒸馏,混合训练等方面总结了一些模型训练技巧,对准确率提升有较好的作用。
参考
https://github.com/kmkolasinski/deep-learning-notes/tree/master/seminars/2018-12-Improving-DL-with-tricks
https://zhuanlan.zhihu.com/p/51870052

















 3363
3363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









