







这一步,我们根据E-step得到的 γ,ϕ ,最大化 L(γ,ϕ;α,β) ,得到 α,β .
1,拉格朗日乘数法求解 β
首先把
L(γ,ϕ;α,β)
简化,只保留与
β
有关的部分。因为
β
是每一行存一个主题的词分布,所以每一行的和是1,存在等式约束
∑Vj=1βij=1
,所以是带等式约束的最大化问题,使用拉格朗日乘数法,可得到拉格朗日函数如下:
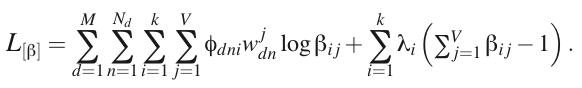
用拉格朗日函数对
β
求偏导,令偏导为0,可得:
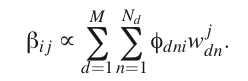
这里的
ϕdni
指的是对第d个文档的变分参数
ϕni
,也就是第n个单词在第i个主题的词分布中的概率,
wjdn
是第d个文档中第n个单词
wn
,
wn
是一个V维向量,其中只有一个元素是1,其他都是0,这个为1的元素对应的索引号就是这个单词在文档集字典中的ID,上标j是指
wn
向量中的每个元素,如果
wjdn=1
那么单词
wn
在文档集字典中的ID就是j。
2,牛顿法求解 α
首先把
L(γ,ϕ;α,β)
简化,只保留与
α
有关的部分:
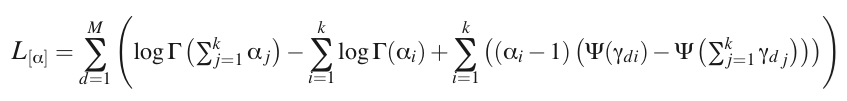
因为
α
是Dirichlet分布的参数(K维的,K是主题个数),所以它没有约束条件,直接对
α
求偏导:
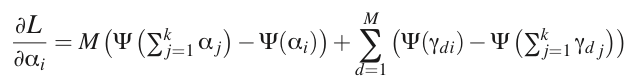
可以看到,一阶导数的结果中包含
αj
,这里不能直接令偏导为0解出
α
。所以需要考虑迭代的方法去求解,作者在这里使用牛顿迭代法。牛顿法的理解可以参考这里:http://blog.csdn.net/luoleicn/article/details/6527049
对于K维向量
α
,它的牛顿迭代式如下:
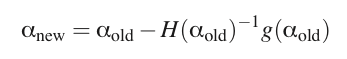
其中
H(α),g(α)
分别是
α
处的Hessian矩阵和梯度。这里我们可以看到有对Hessian矩阵求逆的操作,这个操作时间复杂度高达
O(n3)
,所以考虑简化这个求逆操作。
Hessian矩阵的元素是:
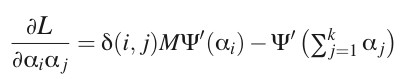
首先对Hessian矩阵H进行分解:
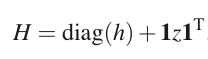
这样Hessian矩阵的逆就成了如下形式:
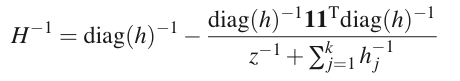
对于
α
的第i个分量,Hessian矩阵的逆和梯度的乘积:
其中:
这样可以看到,
(H−1g)i
只与
hi
和
gi
有关,它们的值各有k个,所以这时的牛顿法是线性的。
本文内容来自LDA原始论文《Latent Dirichlet Allocation》的附录A.2, A.4.















 8837
8837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









