







编者按:李世石与Google Deepmind AlphaGo对战在即,围棋界和人工智能界对结果各有预测,但对于程序员来说,了解AlphaGo的技术路线可能更有意思。本文来自出门问问NLP工程师李理,详细解读了AlphaGo背后的MCTS的工作原理及其对围棋AI的贡献,深度学习包括DCNN在围棋AI领域的发展(包括Facebook darkforest),以及二者在AlphaGo系统中的具体协作。文章还结合作者本人的经历对围棋算法与中国象棋算法的差异进行了比较。
本文原标题:AlphaGo的棋局,与人工智能有关,与人生无关
上接:AlphaGo对战李世石谁能赢?两万字长文深挖围棋AI技术(一)
CNN和Move Prediction
之前我们说了MCTS回避了局面估值的问题,但是人类下围棋显然不是这样的,所以真正要下好围棋,如此从模仿人类的角度来说,这个问题是绕不过去的。人类是怎么学习出不同局面的细微区别的呢?当然不能由人来提取特征或者需要人来编写估值函数,否则还是回到之前的老路上了。我们的机器能自动学习而不需要领域的专家手工编写特征或者规则来实现估值函数呢?
眼下最火热的深度学习也许可以给我们一条路径(当然可能还有其它路径,但深度学习目前看起来解决feature的自动学习是最promising的方法之一)。
深度学习和CNN简介
在机器学习流行之前,都是基于规则的系统,因此做语音的需要了解语音学,做NLP的需要很多语言学知识,做深蓝需要很多国际象棋大师。
而到后来统计方法成为主流之后,领域知识就不再那么重要,但是我们还是需要一些领域知识或者经验来提取合适的feature,feature的好坏往往决定了机器学习算法的成败。对于NLP来说,feature还相对比较好提取,因为语言本身就是高度的抽象;而对于Speech或者Image来说,我们人类自己也很难描述我们是怎么提取feature的。比如我们识别一只猫,我们隐隐约约觉得猫有两个眼睛一个鼻子有个长尾巴,而且它们之间有一定的空间约束关系,比如两种眼睛到鼻子的距离可能差不多。但怎么用像素来定义”眼睛“呢?如果仔细想一下就会发现很难。当然我们有很多特征提取的方法,比如提取边缘轮廓等等。
但是人类学习似乎不需要这么复杂,我们只要给几张猫的照片给人看,他就能学习到什么是猫。人似乎能自动”学习“出feature来,你给他看了几张猫的照片,然后问题猫有什么特征,他可能会隐隐预约的告诉你猫有什么特征,甚至是猫特有的特征,这些特征豹子或者老虎没有。
深度学习为什么最近这么火,其中一个重要的原因就是不需要(太多)提取feature。
从机器学习的使用者来说,我们以前做的大部分事情是feature engineering,然后调一些参数,一般是为了防止过拟合。而有了深度学习之后,如果我们不需要实现一个CNN或者LSTM,那么我们似乎什么也不用干。

CNN最早是Yann Lecun提出用来解决图像识别的问题的一种深度神经网络。由Yann LeCun提出,通过卷积来发现位置无关的feature,而且这些feature的参数是相同的,从而与全连接的神经网络相比大大减少了参数的数量。
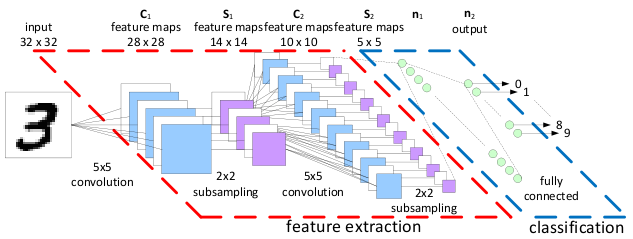
因此CNN非常适合围棋这种feature很难提取问题,比如图像识别。用CNN来尝试围棋的局面评估似乎也是很自然的想法。
Move Prediction using CNN
之前也分析过了,围棋搜索如果不到游戏结束,深的局面并不比浅的容易评估,所以我们不需要展开搜索树,而可以直接评估一个局面下不同走法的好坏。这样做的好处是很容易获得训练数据。我们有大量人类围棋高手的对局(海量中等水平的对局),每一个局面下“好”的走法直接就能够从高手对局库里得到,认为他们的对局都是“好”的走法。但是要得到一个局面的“绝对”得分却很难,因为我们只知道一盘对局最终的结果。一盘游戏最终的胜负可能是因为布局就下得很好,也可能是因为最后的官子阶段下得好,中间具体某个局面的好坏是很难判断的(当然强化学习试图解决这个问题,但是还是很难的,下面在讨论AlphaGo的时候会有涉及)。对于一个局面,如果能知道这个局面下最好的走法(或者几个走法),那么我们对弈时就直接选择这个走法(当然这个最好的走法可能得分也很差,比如败局已定的情况下怎么走都是输)。
所以大部分研究都是用CNN来预测一个局面下最好的走法。【预测走法比估值一个局面容易,如果我们能够准确估值局面,那么最佳走法就是从走之后的局面中选择对自己最有利的走法。或者用我们做问答系统常用的比喻,预测走法是搜索引擎,局面评估是问答系统。搜索引擎只要把好的排前面就行了(甚至不一定要求排在第一,排在第一页也就差不多了),而问答不仅要把好的排前面,而且还要知道这个最“好”的结果是否足够“好”,因为排序的好是相对“好”,问答的好必须是绝对的“好”,是唯一正确答案】。
Van Der Werf等(2003)
最早用CNN(当然还有用其它机器学习方法)来预测走法是2003年Van Der Werf等人的工作,他们用了很多手工构造的feature和预处理方法,他们取得了25%的预测准确率。没有细看论文,在2006年Deep Learning火之前,所以估计网络的层次很浅。
Sutskever & Nair(2008)
之后在2008年,这个时候Deep的神经网络已经逐渐流行了。Sutskever & Nair用来2层的CNN,第一层有15个7*7的filter,第二层用了5*5的filter,最后用了一个softmax层,输出19*19,表示每个可能走法的概率(当然需要后处理去掉不合法或者不合理的走法,比如违反棋规的打劫局面立即提回,或者在自己的眼里下棋)。他们得到了34%的预测准确率。不过有一点问题就是他们出来使用当前局面,还用了上一步走法(这个走子导致了当前局面,也就是对手的上一步走子),这个可能是有问题的,因为实际对局时对手的水平是不能确定的,用这个feature当然能提高“数字”上的准确率,但是对于下棋水平是否有负面影响是很难说的。
Clark & Storkey(2015)
到了2015年,计算机的计算能力更强,深度神经网络的层次也越来越深,在围棋领域也能看到这种趋势。Clark & Storkey使用了8层的CNN,用的特征包括最原始的棋子(用了3个feature plane,表示361个点是黑棋/白棋/空白),ko(劫)的约束,一个group(块)的气。包括使用很多trick来保证symmetries(因为围棋的局面旋转90/180/270/360度后以及做180度的镜像之后应该是一样的)。他们在GoGoD数据上的预测准确率达到了41.1%,在KGS数据上的准确率达到44.4%。GoGoD上大部分是职业选手的对局,而KGS数据有很多业余高手的对局。
Maddison等(2015)
光是预测准确率,并不能说明下棋的水平。因此Maddison等人的工作把Move Prediction用到了实际的对弈当中。
他们的CNN增加到了12层,feature也有所增加,下面是他们使用的feature。
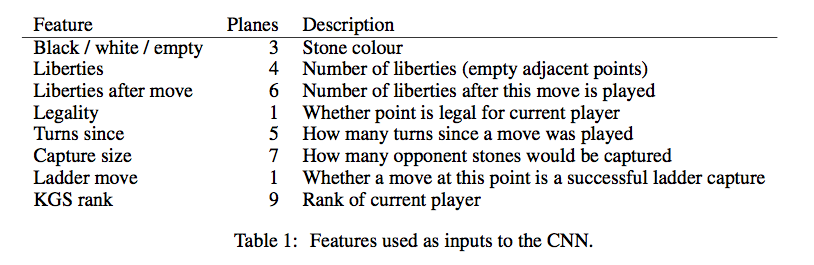
第一组feature是棋子(Stone)的颜色,和之前一样。
第二组是棋子(所在group)的气,用4个plane来表示,分别是1,2,3 >=4口气。
第三组是走了这步棋之后的气,用了6个plane,代表1,2,3,4,5,>=6口气。
第四组表示这个走法在当前局面是否合法。
第五组表示这个棋子距离当前局面的轮次,比如上一步对手走的就是1,上上一步自己走的就是2。因为围棋很多都是局部的战役,所以这个feature应该是有用的。
第六组就是表示走这这后能吃对方多少个棋子。
第七组表示走这能否征子成功。
第八组feature比较有趣,按照作者的说法就是因为KGS的对弈水平参差不齐,如果只留下高手的对局数据太少,所以用这个feature。
他们在KGS数据上的预测准确率达到55%。相对于Clark等人的工作,Maddison的工作除了增加了CNN的层次(8到12),增加的feature应该是很有帮助的,比如Turns Since,Capture Size和Ladder Move。尤其是Ladder Move,下过围棋的都知道征子能否成功对应是否要走这步棋已经局部的计算非常重要。
根据他们的使用,人类6d的预测准确率也只有52%,所以从预测走法的角度来说,CNN的水平已经达到了6d的水平。
另外他们还做了实验,证明Clark那些用来保证symmetry的tricky并没有什么卵用,直接简单粗暴的把数据做symmetr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









