







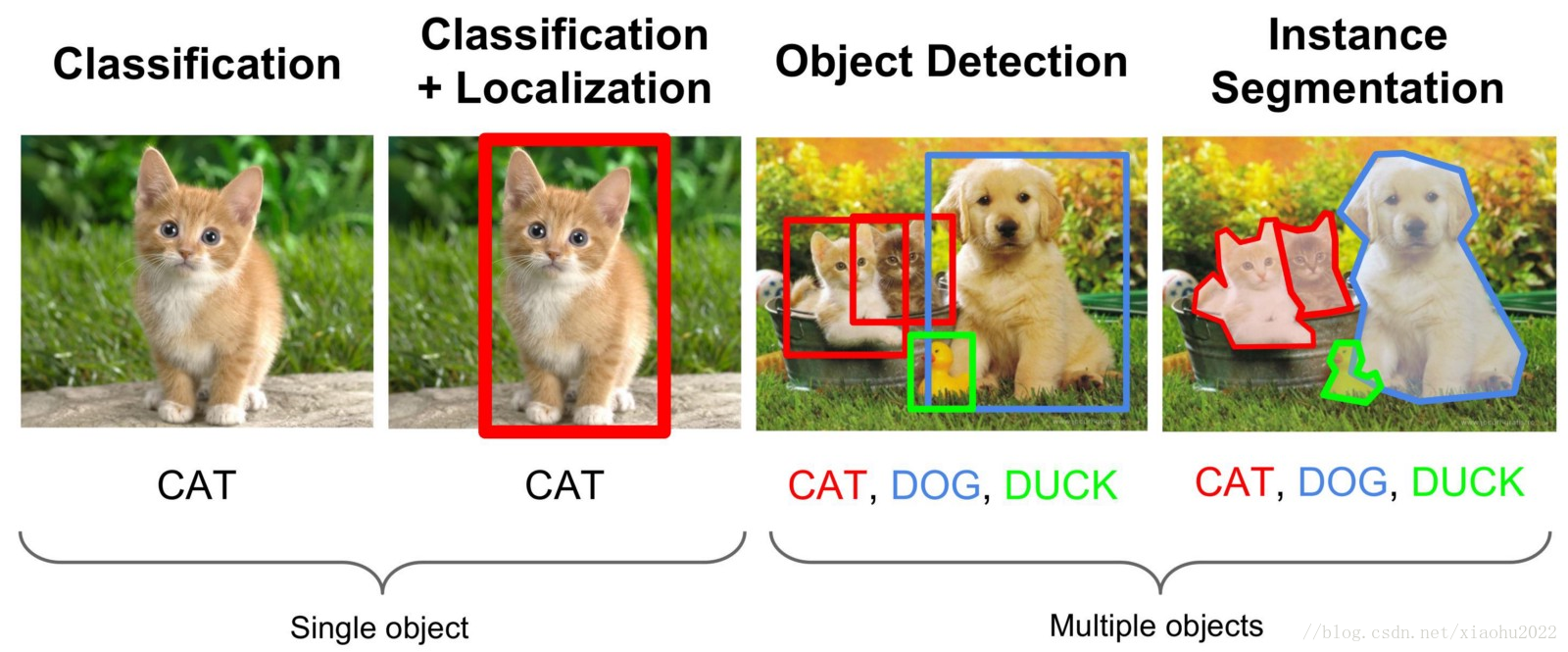
一、什么是目标检测
顾名思义,即从一张图片中,检测出有哪些想要知道的物体,同时给出目标所在的位置信息。在深度学习图像处理研究方面,主要分为两类----分类和检测,当然也包括图像合成等其他方面。分类相对简单,通常一张输入图片对应于一个类。分类的特点就是输入场景单一,一张图片属于一个类别,在分类方面也有很多经典的网络,例如AlexNet、VggNet、ResNet等等,现在的准确率也是越来越高。物体检测(目标检测 object detection)相对于分类来说比较复杂,因为一张图片里面可能存在属于多个类的多个物体,不仅仅要检测出多少个目标、每个目标属于什么类别,还要确定每个目标的位置(bounding boxes)或者轮廓(图像分割),并且目标的分布存在方向不定、大小不定、位置不定、形状不定、相互交叉重叠等情况,比较常用的场景有行人检测、车辆检测、文本检测等场景,在应用领域主要包括无人驾驶、安全保障、医疗、农业、生产等领域。
二、发展
在传统视觉领域,目标检测就是一个非常热门的研究方向。传统的目标检测一般使用滑动窗口的框架,主要包括三个步骤:
1、利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;
2、提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征;行人检测和普通目标检测常用的HOG特征等;
3、利用分类器进行识别,比如常用的SVM模型。
传统的目标检测中,非常经典的是多尺度形变部件模型DPM(Deformable Part Model),连续获得VOC 2007到2009的检测冠军,2010年其作者Felzenszwalb Pedro被VOC授予”终身成就奖”。DPM把物体看成了多个组成的部件(比如人脸的鼻子、嘴巴等),用部件间的关系来描述物体,这个特性非常符合自然界很多物体的非刚体特征。DPM可以看做是HOG+SVM的扩展,很好的继承了两者的优点,在人脸检测、行人检测等任务上取得了不错的效果,但这种特征提取方式存在明显的局限性,首先,DPM特征计算复杂,计算速度慢;其次,人工特征对于旋转、拉伸、视角变化的物体检测效果差。这些弊端很大程度上限制了算法的应用场景。正当大家热火朝天改进DPM性能的时候,基于深度学习的目标检测横空出世,迅速盖过了DPM的风头,很多之前研究传统目标检测算法的研究者也开始转向深度学习。
目前目标检测领域的深度学习方法主要分为两类:two stage的目标检测算法,这类算法的典型代表是基于region proposal的R-CNN系算法,如R-CNN,Fast R-CNN,Faster R-CNN等;one stage的目标检测算法,比较典型的算法如YOLO和SSD。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优。
三、数据集
PASCAL VOC:http://host.robots.ox.ac.uk/pascal/VOC/
PASCAL VOC对比:http://host.robots.ox.ac.uk:8080/leaderboard/main_bootstrap.php
ImageNet:http://www.image-net.org/
MS COCO:http://cocodataset.org/#home
Open Images:https://storage.googleapis.com/openimages/web/index.html
CIFAR:https://www.cs.toronto.edu/~kriz/cifar.html
Mnist:http://yann.lecun.com/exdb/mnist/
KITTI(自动驾驶):http://www.cvlibs.net/datasets/kitti/
Cityscapes(自动驾驶):https://www.cityscapes-dataset.com/
LFW(人脸检测):http://vis-www.cs.umass.edu/lfw/
nuScenes(自动驾驶):https://d3u7q4379vrm7e.cloudfront.net/download
四、论文
https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html
https://github.com/hoya012/deep_learning_object_detection#2014
五、概念
在目标检测领域,也有一些特殊的概念和评价标准,主要有:
1. IOU
当模型检测出目标的位置(bbox)时,我们应该怎么判断识别的是否正确呢?不同于物体分类可以精确地定义正负,目标检测几乎很难做到输出的目标位置和实际框定的目标一丝不差,一般我们会按照识别结果和实际位置的重合度来判断正负,比如如果模型输出的bbox和实际的bbox重合度在50%以上,我们就认为输出正确。那么这个重合度是怎么计算的呢?
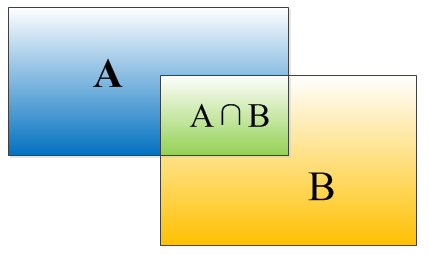
IOU定义了两个bounding box的重叠度,如图2所示,IOU=(A∩B)/(A∪B),就是矩形框A、B的重叠面积占A、B并集的面积比例。在实际中,我们也常设定一个IOU阈值来判断识别正误。
2. 非极大值抑制(nms)

如图3,定位一个车辆,最后算法可能找出了一堆的方框,有些是比较合理的,有些可能只包含了一部分,我们需要判别哪些矩形框是没用的。先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
- 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值
- 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的
- 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框
- 就这样一直重复,找到所有被保留下来的矩形框
非极大值抑制(NMS)非极大值抑制顾名思义就是抑制不是极大值的元素,搜索局部的极大值。














 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









