







目录
一、
目标检测两个分支,two-stage和one-stage算法
-
two-stage算法主要是RCNN系列,,包括RCNN, Fast-RCNN,Faster-RCNN,其中RCNN和Fast-RCNN之间过渡了一个SPPNet。之后在Faster-RCNN框架的基础上,又出现了更好的backbone网络Pyramid Networks。之后的Mask-RCNN融合了Faster-RCNN架构、ResNet和FPN(Feature Pyramid Networks)backbone,以及FCN里的segmentation方法,在多完成了segmention的同时也提高了detection的AP。
-
one-stage算法最早是YOLO(后面又更新了YOLO2,YOLO3···),该算法速度极快,AP也极低。之后出现了速度和AP兼具的SSD(在SSD基础上又出现了DSSD,RefineNet,RFB-SSD,FSSD等改进网络)。还有解决了one-stage算法里正负样本极不平衡问题的Retina-Net。
- 区别:
- two-stage说法1:two-stage算法会先使用一个网络生成proposal,如selective search和RPN网络,前者是基于一些人造特征来的,RPN是一个也需要进行训练的网络,RPN出现后,ss方法基本就被摒弃。RPN网络接在图像特征提取网络backbone后(和之后的fast-RCNN网络架构共用特征提取层),会设置RPN loss(bbox regression loss+classification loss)对RPN网络进行训练,RPN生成的proposal再送到后面的网络中进行更精细的bbox regression和classification。
- two-stage说法2:Two-stage方法是先生成region proposal再将其喂给detect head。detect head 只是一个将二维图的部分区域对应的region feature通过Fully-connected layers 输出softmax结果(分类)和box regressor结果(位置)
- One-stage追求速度舍弃了two-stage架构,即不再设置单独网络生成proposal,而是直接在feature map上进行密集抽样,产生大量的先验框,如YOLO的网格方法和SSD沿用Faster-RCNN的Anchor方法。这些先验框没有经过两步处理,且框的尺寸往往是人为规定,精度肯定会比较低,而且Retina-Net论文中提到,one-stage产生的先验框正负样本比例严重失衡(背景样本占多数),会引起训练上的问题(Focal Loss正是为了解决这个问题)。
- 区别:
什么是端到端(end2end)
链接
在神经网络中,经常看到end2end的训练方式。
end2end在不同的应用场景中有不同的诠释,对于视觉领域而言,神经网络的输入为图片,输出就是我们想要的结果。例如:
1,自动驾驶中,输入为道路的图片,输出就是转向的角度。
2,视觉机器人,输入的是图片,输出就是机械手运动的指令。
3,目标识别中,输入为待检测图片,输出就是检测到的目标类别以及目标位置。
非end2end模式下进行目标检测,一般神经网络中会分为两个部分,第一部分是Region Proposal,这部分的功能是负责找出图片中目标的位置和大小。第二部分就是判断第一部分中是否真的存在目标,以及目标是属于哪一类,判断一般是在CNN中来完成的。这种套路一般都是在RCNN中经常使用。
在end2end模式下,位置和类别全部由一个模型解决,原始图像输入,模型输出的结果就是位置和类别。一端输入原始图像,一端输出想要的结果,只关心输入和输出,中间的步骤全部都不管。
二、产生候选框的方法:
Sliding Window
在图像上滑动一个框或窗口来选择一个区域,并使用目标识别模型对窗口覆盖的每个图像块进行分类。
RegionProposal
由于一张图片里有很多地方是没有物体的。Region Proposal意思是建议检测的区域,排除哪些没有物体的区域。Region Proposal就是通过像素的聚类,把可能是同一类的事物进行聚为一类。这样就减少了检测的范围。
区域建议算法利用分割的方法识别图像中的前景物体。选择性搜索是最常用的:
- Selective Search
- 首先,对输入图像进行分割算法产生许多小的子区域。
- 其次,根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。
- 每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域外切矩形就是通常所说的候选框。
RPN(用深度学习,自动生成)

在Faster R-CNN 中提出RPN。
- 在 RPN头部 ,通过以下结构生成 anchor(其实就是一堆有编号有坐标的bbox):
- 在 RPN中部, 分类分支(cls) 和 边框回归分支(bbox reg) 分别对这堆anchor进行各种计算
- 在 RPN末端,通过对 两个分支的结果进行汇总,来实现对anchor的 初步筛除(先剔除越界的anchor,再根据cls结果通过NMS算法去重)和 初步偏移(根据bbox reg结果),此时输出的都改头换面叫 Proposal 了:
- two stage型的检测算法在RPN 之后 还会进行 再一次 的 分类任务 和 边框回归任务,以进一步提升检测精度。
三、引入CNN的方法(tow-stage)
RCNN
- 使用Selective Search算法从待检测图像中提取2000个左右的区域候选框,这些候选框可能包含要检测的目标。
- 把所有侯选框缩放成固定大小(原文采用227×227)。
- 用DCNN提取每个候选框的特征,得到固定长度的特征向量。用于提取特征的卷积网络有 5 个卷积层和 2 个全连接层,其输入是固定大小的 RGB 图像,输出为4096 维特征向量
- 把特征向量送入SVM进行分类得到类别信息,送入全连接网络进行回归得到对应位置坐标信息。
流程示意:
图片->候选区域(ROI)->Conv特征提取->svm分类->全连接层进行坐标位置回归
- 缺点:
- 重复计算。 R-CNN 虽然不再是穷举,但通过 Proposal(Selective Search)的方案依然有两千个左右的候选框,这些候选框都需要单独经过 backbone 网络提取特征,计算量依然很大,候选框之间会有重叠,因此有不少其实是重复计算。
- 训练测试不简洁。候选区域提取、特征提取、分类、回归都是分开操作,中间数据还需要单独保存。
- 速度慢。前面的缺点最终导致 R-CNN 出奇的慢, GPU 上处理一张图片需要十几秒,CPU 上则需要更长时间。
- 图片必须固定大小。输入的图片 Patch 必须强制缩放成固定大小(原文采用 227×227),会造成物体形变,导致检测性能下降。
SPPNet(改进RCNN)

RCNN和SPPNet过程比较
该方法虽然还依赖候选框的生成,但将提取候选框特征向量的操作转移到卷积后的特征图上进行,将 R-CNN中的多次卷积变为一次卷积,大大降低了计算量。
特点
引入了 Spatial Pyramid pooling(空间金字塔池化) 层,对卷积特征图像进行空间金字塔采样获得固定长度的输出,可对特征层任意长宽比和尺度区域进行特征提取。
对特征图像区域进行固定数量的网格划分,对不同宽高的图像,每个网格的高度和宽度是不规定的,对划分的每个网格进行池化,这样就可以得到固定长度的输出。

在特征图上划4X4, 2X2, 1X1的格子,对这些格子里的像素进行pooling操作,最后把三个尺度的输出concat到一起,形成21x256的特征图,组成一个特征向量做分类,给全连接层。
流程示意:
原图通过卷积->用SS->把SS的位置映射在卷积后的特征图上->通过SPP->全连接层->分类,定边框位置
- PS: SPPNet 和 R-CNN 一样,它的训练要经过多个阶段,中间特征也要进行存储; backbone网络参数沿用了分类网络的初始参数,没有针对检测问题进行优化。
- 缺点:不能进行反向传播,所以训练的时候分别训练前半段网络和后面的FC层,使训练步骤更复杂。 为什么不能? 主要还是这个pyramid的问题,特征图被分为4x4, 2x2, 1x1三个层级,每个层级的pooling层都能回传,只是这三个在回传之后要怎样融合到一起?简单相加也没有依据,所以不能进行反向传播。
Fast R-CNN
特点:根据SPPNet 中的spp层改进设计了RoI Pooling(即只有一个尺寸的spp Layer),可以进行反向传播,使用muti-task loss同时训练物体种类和位置。网络在 Pascal VOC 上的训练时间从R-CNN 的 84 小时缩短到 9.5 小时,检测时间更是从 45 秒缩短到 0.32 秒。
- SoftmaxLoss代替了SVM,证明了softmax比SVM更好的效果;
- SmoothL1Loss取代Bouding box回归
- 分类直接在原来CNN的基础上加入FC层和softmax即可; 框回归是让CNN的输出直接是bounding box regressor需要的4个比例,偏移量。
- 缺点:依然是耗时的候选框提取过程


流程示意:
原图通过卷积->用SS->把SS的位置映射在卷积后的特征图上->通过RoI Pooling->全连接层->用muti-task loss 同时分类,定边框位置
- Fast R-CNN总结一下就是:前面Selective Search提取框的过程配上后面的CNN+softmax,以现在的眼光去比喻,有点像造好了一辆汽车(CNN),但是在用马(selective search)拉着跑的感觉。因为selective search的计算过程就挺慢的,想让物体检测达到实时,就得改造候选框提取的方法。
Faster R-CNN
通过添加额外的RPN(Region Proposal Network))分支网络,将候选框提取合并到深度网络中,这正是Faster-RCNN里程碑式的贡献。
RPN网络接在图像特征提取网络后,共享了特征提取层。
结构:

-
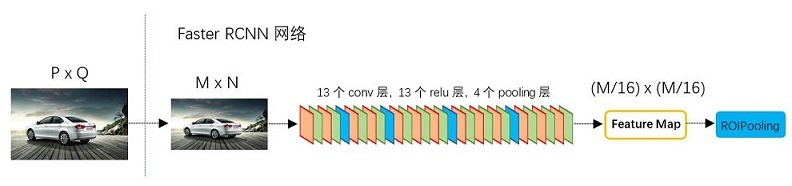
基础Conv 层。首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。一共13个conv层+13个relu层+4个pooling层;
-
所有的conv层都是:kernel_size=3,pad=1,stride=1
所有的pooling层都是:kernel_size=2,pad=0,stride=2 -
其中,对所有卷积做了扩边处理(pad = 1),使原图变为M+2 X N+2,在经过3X3卷积还是MXN,没有改变输入和输出矩阵大小。
-
所有池化层后,使输出长宽都变为输入的1/2。最终,一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16)!这样Conv layers生成的feature map中都可以和原图对应起来
-
-
RPN。先3x3卷积,上方通过softmax生成positive/negative anchors,下方计算对应bounding box regression偏移量,最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。这里已经对目标进行定位

-
Roi Pooling层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别
-
Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
anchors(RPN第一分支)
详细介绍https://zhuanlan.zhihu.com/p/55824651
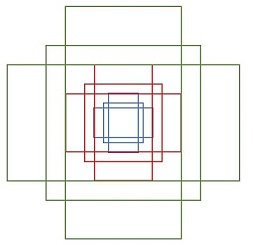
-
Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature
map每个点都是256-dimensions -
遍历Conv layers计算获得的feature maps,为每一个点都配备9种anchors作为初始的检测框。
-
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2•k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4•k coordinates
-
训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。
bounding box regression

绿色框为飞机的Ground Truth(GT),红色为提取的positive anchors。
对于窗口一般使用四维向量(x,y,w,h)表示,分别表示窗口的中心点坐标和宽高。
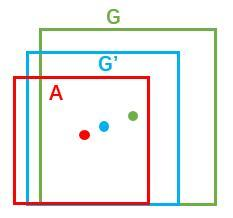
怎么从A到G’? 先做平移再做缩放。
当输入的anchor A与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(只有当anchors A和GT比较接近时,才能使用线性回归模型)
proposals(RPN第二分支)
Proposal Layer负责综合所有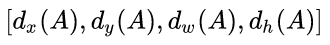
变换量和positive anchors,再加上im_info,一共三个输入,计算出精准的proposal,送入后续RoI Pooling Layer。
每个ROI(文中叫candidate object)主要有两个输出,一个输出是分类结果,也就是预测框的标签;另一个输出是回归结果,也就是预测框的坐标offset
- 解释im_info。对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。然后经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量
总体描述

先输入一个图像image,用一个CNN提特征,在这段CNN输出的特征图(feature map)上做anchor处理,如上图所示,假设这个层级的特征图通道数是256。那么这个特征图多大,就相当于设定了多少个锚点,比如特征图长宽是13x13, 那就有169个锚点,每一个锚点按照论文中的说法可以产生9个锚点框,这9个锚点框共用一组1×256的特征,即锚点所在位置上所有通道的数据,接一个1×1的卷积核控制维度,做位置回归和前后景判断,这就是RPN的输出。在RPN的输出基础上,对所有anchor box的前景置信度排序,挑选出前top-N的框作为预选框proposal, 继续用一段CNN做进一步特征提取,最后再进行位置回归和物体种类判断。
四、one-stage
YOLO
Yolo把整张图划分成7×7个格子,每个格子预测俩个框,一共98个,只有当目标物体的中心落在某个格子里时,才在计算loss时使用这个格子。这就相当于是在Faster R-CNN中每张图片用7×7个锚点,每个锚点产生2个候选框。
YOLOv1只预测了目标物体中心点附近的点的边界框,所以召回率低(low recall),召回率是针对原样本来说,样本中的正例有多少被预测正确了。
1)将图像划分为固定的网格(比如7*7),如果某个样本Object中心落在对应网格,该网格负责这个Object位置的回归;
2)每个网格预测包含Object位置与置信度信息,这些信息编码为一个向量;
3)网络输出层即为每个Grid的对应结果,由此实现端到端的训练。
SSD
RetinaNet
使用Focal Loss的全新结构RetinaNet,使用ResNet+FPN作为backbone,再利用单级的目标识别法+Focal Loss

- 训练时FPN每一级的所有example都被用于计算Focal Loss,loss值加到一起用来训练;
- 测试时FPN每一级只选取score最大的1000个example来做nms;
- 整个结构不同层的head部分(图2的c和d部分)共享参数,但分类和回归分支间的参数不共享;
- 分类分支的最后一级卷积的bias初始化成前面提到的-log((1-π)/π);
CornerNet
检测到边界框的一对角,并将其分组,形成最终检测到的边界框。CornerNet需要更复杂的后处理来对属于同一实例的角对进行分组
FCOS
https://blog.csdn.net/weixin_44176643/article/details/123209444















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









