








获取更多资讯,赶快关注上面的公众号吧!
食肉植物算法 carnivorous plant algorithm (CPA)是由马拉西亚的Ong Kok Meng,于2020年受食肉植物如何适应恶劣环境(比如捕食昆虫和传粉繁殖)的启发而提出的。扫码关注公众号,后台回复“食肉植物”或“CPA”可以获取Matlab代码。
背景
众所周知,大多数植物是动物的直接食物来源,但是自然界中也有例外,食肉植物就是其中一种。它们通常生长在缺乏营养的恶劣环境中,例如,湿地、沼泽和以水丰富为特征的泥泞海岸。为了获取生长和繁殖所需的氮和磷等额外的营养,食肉植物用它们分泌的酶吸引、诱捕和吃掉苍蝇、蝴蝶、蜥蜴和老鼠等动物。猪笼草、茅膏菜、狸藻、维纳斯捕蝇草等都是常见的食肉植物。[PS:北航还在猪笼草身上发现了水倒流的现象,并因此成功发表了全国机械领域的第一篇Nature]

食肉植物算法的数学模型
那么接下来就介绍一下用于模拟食肉植物吸引、诱捕、消化和繁殖策略的数学模型。CPA从随机初始化一组解开始,然后这些解被分为食肉植物和猎物,再按生长和繁殖过程分组,进行适应度值的更新,最后将所有解合并。整个过程循环执行直到满足终止条件。
初始化
CPA是一种基于种群的优化算法,因此首先需要初始化待求解问题的可能解,即在湿地中随机初始化
n
C
P
l
a
n
t
nCPlant
nCPlant个食肉植物和
n
P
r
e
y
nPrey
nPrey个猎物个体,每个个体的位置由以下矩阵表示:
P
o
p
=
[
Individual
1
,
1
Individual
1
,
2
⋯
⋯
Individual
1
,
d
Individual
2
,
1
Individual
2
,
2
⋯
⋯
Individual
2
,
d
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
Individual
n
,
1
Individual
n
,
2
⋯
⋯
Individual
n
,
d
]
(1)
P o p=\left[\begin{array}{ccccc} \text { Individual }_{1,1} & \text { Individual }_{1,2} & \cdots & \cdots & \text { Individual }_{1, d} \\ \text { Individual }_{2,1} & \text { Individual }_{2,2} & \cdots & \cdots & \text { Individual }_{2, d} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ \text { Individual }_{n, 1} & \text { Individual }_{n, 2} & \cdots & \cdots & \text { Individual }_{n, d} \end{array}\right] \tag{1}
Pop=⎣⎢⎢⎢⎢⎢⎢⎡ Individual 1,1 Individual 2,1⋮⋮ Individual n,1 Individual 1,2 Individual 2,2⋮⋮ Individual n,2⋯⋯⋮⋮⋯⋯⋯⋮⋮⋯ Individual 1,d Individual 2,d⋮⋮ Individual n,d⎦⎥⎥⎥⎥⎥⎥⎤(1)
其中
d
d
d为维度,即变量个数,
n
n
n为
n
C
P
l
a
n
t
nCPlant
nCPlant和
n
P
r
e
y
nPrey
nPrey的总和,每个个体使用下式进行随机初始化:
Individual
i
,
j
=
L
b
j
+
(
U
b
j
−
L
b
j
)
×
rand
(2)
\text { Individual }_{i, j}=L b_{j}+\left(U b_{j}-L b_{j}\right) \times \text { rand }\tag{2}
Individual i,j=Lbj+(Ubj−Lbj)× rand (2)
其中,
L
b
Lb
Lb和
U
b
Ub
Ub分别为搜索域的下界和上界,即自变量的最小值和最大值,
i
∈
[
1
,
2
,
.
.
.
,
n
]
i\in[1,2,...,n]
i∈[1,2,...,n],
j
∈
[
1
,
2
,
.
.
.
,
d
]
j\in[1,2,...,d]
j∈[1,2,...,d],
r
a
n
d
rand
rand为
[
0
,
1
]
[0,1]
[0,1]之间的随机数。
对于第
i
i
i个个体,通过将每一行(即所有维度)作为适应度函数的输入来评估适应度值,计算得到的适应度值存储在以下矩阵中:
Fit
=
[
f
(
Individual
1
,
1
Individual
1
,
2
⋯
⋯
Individual
1
,
d
)
f
(
Individual
2
,
1
Individual
2
,
2
⋯
⋯
Individual
2
,
d
)
⋮
⋮
f
(
Individual
n
,
1
Individual
n
,
2
⋯
⋯
Individual
n
,
d
)
]
(3)
\text { Fit }=\left[\begin{array}{ccccc} f\left(\text { Individual }_{1,1}\right. & \text { Individual }_{1,2} & \cdots & \cdots & \text { Individual } \left._{1, d}\right) \\ f\left(\text { Individual }_{2,1}\right. & \text { Individual }_{2,2} & \cdots & \cdots & \text { Individual } \left._{2, d}\right) \\ & \vdots & & & \\ & \vdots & & & \\ f\left(\text { Individual }_{n, 1}\right. & \text { Individual }_{n, 2} & \cdots & \cdots & \text { Individual } \left._{n, d}\right) \end{array}\right]\tag{3}
Fit =⎣⎢⎢⎢⎢⎢⎢⎡f( Individual 1,1f( Individual 2,1f( Individual n,1 Individual 1,2 Individual 2,2⋮⋮ Individual n,2⋯⋯⋯⋯⋯⋯ Individual 1,d) Individual 2,d) Individual n,d)⎦⎥⎥⎥⎥⎥⎥⎤(3)
分类和分组
接下来,式(1)中的每个个体按照其适应度值升序排序(考虑最小化问题),那么排在最前面的
n
C
P
l
a
n
t
nCPlant
nCPlant个解就作为食肉植物
C
P
CP
CP,而剩余的
n
P
r
e
y
nPrey
nPrey个解就是猎物
P
r
e
y
Prey
Prey。图2可视化了食肉植物和猎物种群。
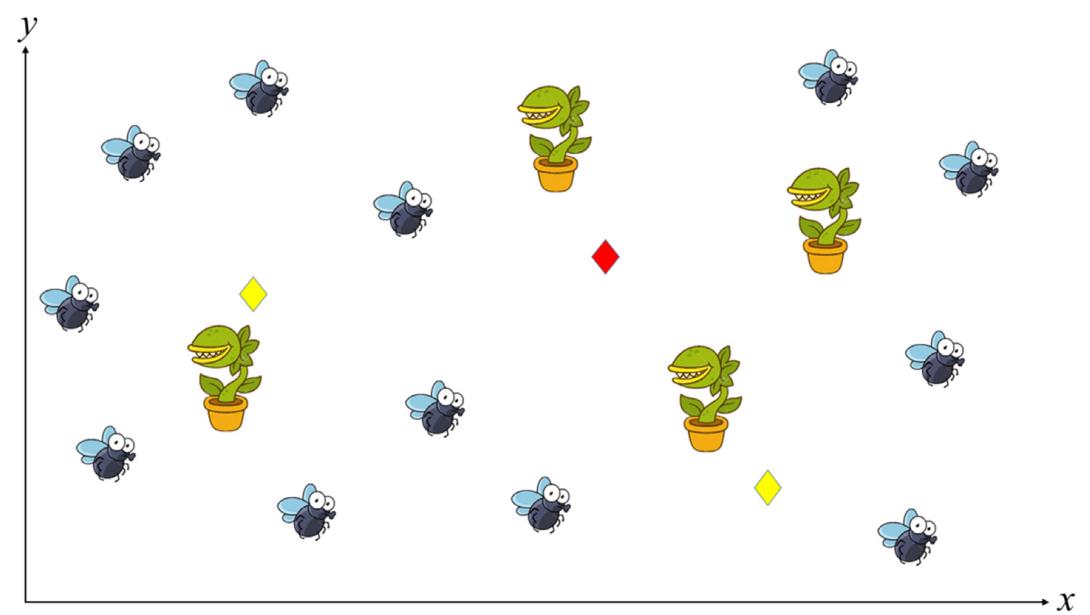
排序后的适应度值和种群可通过式(4)和式(5)表达:
Sorted_Fit = [ f C P ( 1 ) f C P ( 2 ) ⋮ f C P ( n C P l a n t ) f Prey ( n C P l a n t + 1 ) f Prey ( n C P l a n t + 2 ) ⋮ f Prey ( n C P l a n t + n p r e y ) ] (4) \text { Sorted\_{Fit} }=\left[\begin{array}{c} f_{C P(1)} \\ f_{C P(2)} \\ \vdots \\ f_{C P(n C P l a n t)} \\ f_{\text {Prey }(n C P l a n t+1)} \\ f_{\text {Prey }(n C P l a n t+2)} \\ \vdots \\ f_{\text {Prey }(n C P l a n t+n p r e y)} \end{array}\right]\tag{4} Sorted_Fit =⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡fCP(1)fCP(2)⋮fCP(nCPlant)fPrey (nCPlant+1)fPrey (nCPlant+2)⋮fPrey (nCPlant+nprey)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤(4)
Sorted_Pop
=
[
C
P
1
,
1
C
P
1
,
2
⋯
⋯
C
P
1
,
d
C
P
2
,
1
C
P
2
,
2
⋯
⋯
C
P
2
,
d
⋮
⋮
⋮
⋮
⋮
C
P
n
C
P
l
a
n
t
,
1
C
P
n
C
P
l
a
n
t
,
2
⋯
⋯
C
P
n
C
P
l
a
n
t
,
d
Prey
n
C
P
l
a
n
t
+
1
,
1
Prey
n
C
P
l
a
n
t
+
1
,
2
⋯
⋯
Prey
n
C
P
l
a
n
t
+
1
,
d
Prey
n
C
P
l
a
n
t
+
2
,
1
Prey
n
C
P
l
a
n
t
+
2
,
2
⋯
⋯
Prey
n
C
P
l
a
n
t
+
2
,
d
⋮
⋮
⋮
⋮
⋮
Prey
n
C
P
l
a
n
t
+
n
P
r
e
y
,
1
Prey
n
C
P
l
a
n
t
+
n
P
r
e
y
,
2
⋯
⋯
Prey
n
C
P
l
a
n
t
+
n
P
r
e
y
,
d
]
(5)
=\left[\begin{array}{ccccc} C P_{1,1} & C P_{1,2} & \cdots & \cdots & C P_{1, d} \\ C P_{2,1} & C P_{2,2} & \cdots & \cdots & C P_{2, d} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ C P_{n C P l a n t}, 1 & C P_{n C P l a n t, 2} & \cdots & \cdots & C P_{n C P l a n t, d} \\ \text { Prey }_{n C P l a n t+1,1} & \text { Prey }_{n C P l a n t+1,2} & \cdots & \cdots & \text { Prey }_{n C P l a n t+1, d} \\ \text { Prey }_{n C P l a n t+2,1} & \text { Prey }_{n C P l a n t+2,2} & \cdots & \cdots & \text { Prey }_{n C P l a n t+2, d} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ \text { Prey }_{n C P l a n t+n P r e y, 1} & \text { Prey }_{n C P l a n t+n P r e y, 2} & \cdots & \cdots & \text { Prey }_{n C P l a n t+n P r e y, d} \end{array}\right]\tag{5}
=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡CP1,1CP2,1⋮CPnCPlant,1 Prey nCPlant+1,1 Prey nCPlant+2,1⋮ Prey nCPlant+nPrey,1CP1,2CP2,2⋮CPnCPlant,2 Prey nCPlant+1,2 Prey nCPlant+2,2⋮ Prey nCPlant+nPrey,2⋯⋯⋮⋯⋯⋯⋮⋯⋯⋯⋮⋯⋯⋯⋮⋯CP1,dCP2,d⋮CPnCPlant,d Prey nCPlant+1,d Prey nCPlant+2,d⋮ Prey nCPlant+nPrey,d⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤(5)
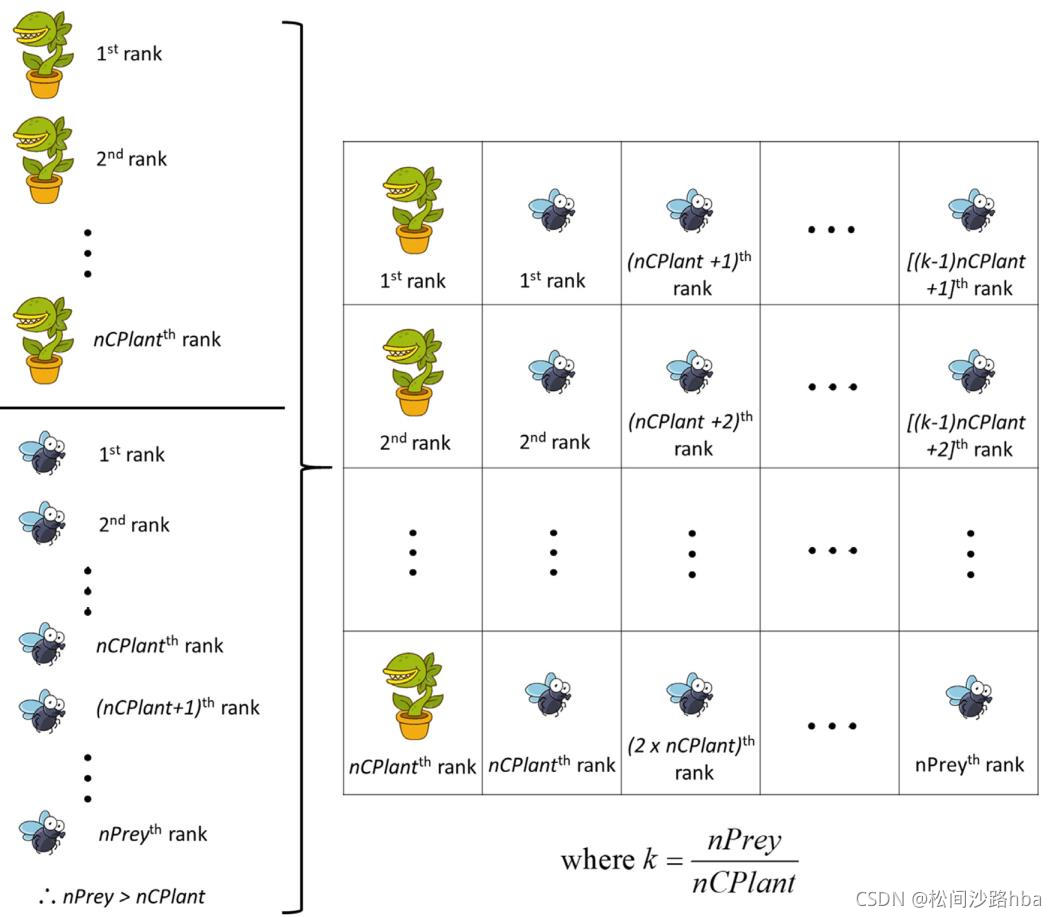
分组的过程主要是用于模拟每个食肉植物及其猎物的环境,在分组过程中,将适合度值最高的猎物分配给排名第一的食肉植物,类似地,第二名和第三名猎物分别属于第二和第三名食肉植物。重复该过程,直到排名第
n
C
P
l
a
n
t
nCPlant
nCPlant的猎物分配给排名第
n
C
P
l
a
n
t
nCPlant
nCPlant的食肉植物,然后第
n
C
P
l
a
n
t
+
1
nCPlant+1
nCPlant+1名猎物分配给第1名食肉植物(所以这里默认猎物是多余食肉植物的)。整个分组过程入图3所示。对食肉植物进行分组主要是为了减少食肉植物生长过程中出现大量劣质猎物的可能性,这对提高食肉植物的生存能力至关重要。
成长(探索)
由于土壤营养不良,食肉植物会吸引、诱捕和消化猎物来生长。这种植物的香味能引诱猎物,但猎物也能偶尔成功地从食肉植物的魔爪中逃脱,所以这里引入了一个吸引率。
每一种群都随机选择一个猎物,如果吸引率高于随机生成的数字,食肉植物就会捕获猎物并消化来生长。新的食肉植物的生长模型为:
NewCP
i
,
j
=
growth
×
C
P
i
,
j
+
(
1
−
growth
)
×
Prey
v
,
j
(6)
\text { NewCP }_{i, j}=\text { growth } \times C P_{i, j}+(1-\text { growth }) \times \text { Prey }_{v, j}\tag{6}
NewCP i,j= growth ×CPi,j+(1− growth )× Prey v,j(6)
growth = g r o w t h _ r a t e × rand i , j (7) \text { growth }= growth\_rate \times \text { rand }_{i, j}\tag{7} growth =growth_rate× rand i,j(7)
其中 C P i , j CP_{i,j} CPi,j是排名第 i i i的食肉植物, P r e y v , j Prey_{v,j} Preyv,j为随机选择的猎物,成长率 g r o w t h _ r a t e { growth\_rate} growth_rate为预定义的值, r a n d rand rand为 [ 0 , 1 ] [0,1] [0,1]之间的随机数。在CPA中,每一个种群内部只有一个食肉植物,而猎物的数量必须多于两个。大多数情况下,CPA的吸引率设置为0.8。
另一方面,如果吸引率低于产生的随机值,则猎物设法逃脱陷阱并继续生长,数学上表示为:
NewPrey i , j = growth × Prey u , j + ( 1 − growth ) × Prey v , j , u ≠ v (8) \text { NewPrey }_{i, j}=\text { growth } \times \text { Prey }_{u, j}+(1-\text { growth }) \times \text { Prey }_{v, j}, \quad u \neq v\tag{8} NewPrey i,j= growth × Prey u,j+(1− growth )× Prey v,j,u=v(8)
f ( n ) = { growth_rate × rand i , j , f ( prey v ) > f ( prey u ) 1 − growth_rate × rand i , j , f ( prey v ) < f ( prey u ) (9) f(n)= \begin{cases} \text { growth\_rate } \times \text { rand }_{i, j},& f\left(\text { prey }_{v}\right)>f\left(\text { prey }_{u}\right) \\ 1-\text { growth\_rate } \times \text { rand }_{i, j},& f\left(\text { prey }_{v}\right)< f\left(\text { prey }_{u}\right) \end{cases}\tag{9} f(n)={ growth_rate × rand i,j,1− growth_rate × rand i,j,f( prey v)>f( prey u)f( prey v)<f( prey u)(9)
其中 P r e y u , j Prey_{u,j} Preyu,j是第 i i i个种群中随机选择的另一个猎物。食肉植物和猎物的生产过程都将持续 group_iter \text{group\_iter} group_iter代。
式(6)和(8)用于将新的解向高质量解空间方向指引,同时也为了保证在猎物的生长过程中起到类似的作用,引入了式(9),因为随机选择的 P r e y u Prey_u Preyu可能劣于 P r e y v Prey_v Preyv。如式(6)和(8)所示,算法的探索受生长率的影响,生长率越高,探索范围越大,错失全局最优解的可能性业越大。因此需要选择一个合适的生长率。
繁殖(利用)
食肉植物吸收猎物的营养,并利用这些营养生长和繁殖。在繁殖方面,只有排名第一的食肉植物,即种群中最好的解,才允许繁殖。这是为了确保CPA的利用只关注最优解,从而避免对其他解进行不必要的利用,节省计算成本。最优食肉植物的繁殖过程如下:
NewCP
i
,
j
=
C
P
1
,
j
+
Reproduction_rate
×
rand
i
,
j
×
mate
i
,
j
(10)
\text { NewCP }_{i, j}=C P_{1, j}+\text { Reproduction\_rate } \times \text { rand }_{i, j} \times \text { mate }_{i, j}\tag{10}
NewCP i,j=CP1,j+ Reproduction_rate × rand i,j× mate i,j(10)
mate i , j = { C P v , j − C P i , j f ( C P i ) > f ( C P v ) C P i , j − C P v , j f ( C P i ) < f ( C P v ) , i ≠ v ≠ 1 (11) \text { mate }_{i, j}=\begin{cases} C P_{v, j}-C P_{i, j} & f\left(C P_{i}\right)> f\left(C P_{v}\right) \\ C P_{i, j}-C P_{v, j} & f\left(C P_{i}\right)< f\left(C P_{v}\right) \end{cases}, i \neq v \neq 1\tag{11} mate i,j={CPv,j−CPi,jCPi,j−CPv,jf(CPi)>f(CPv)f(CPi)<f(CPv),i=v=1(11)
其中 C P 1 , j CP_{1,j} CP1,j为最优解, C P v , j CP_{v,j} CPv,j为随机选择的食肉植物,繁殖率 R e p r o d u c t i o n _ r a t e Reproduction\_rate Reproduction_rate是预定义的用于利用的值。繁殖过程重复 n C P l a n t nCPlant nCPlant次,繁殖过程中,为每个维度 j j j都随机选择一个食肉植物 v v v。
适应度更新和合并
将新生成的食肉植物和猎物于先前的种群进行合并,就得到了一个新的维度为 [ n + n C P l a n t ( g r o u p _ i t e r + n C P l a n t ) ] x d [n+nCPlant({group\_iter}+nCPlant)]\text{x} d [n+nCPlant(group_iter+nCPlant)]xd维( n n n个原始个体, n C P l a n t ( g r o u p _ i t e r nCPlant({group\_iter} nCPlant(group_iter个生长过程个体和 n C P l a n t nCPlant nCPlant个繁殖过程个体)的新种群,之后,新种群按照适应度值升序排序,选择排名前 n n n的个体作为新的候选解,保证种群大小不变。这种精英选择策略保证了选择更优的解用于下一代的繁殖。
停止准则
重复整个分类、分组、生长和繁殖的过程,直到到达终止停止准则。如下 为CPA的伪代码。
食肉植物算法
1.定义目标函数 f ( x ⃗ ) , x ⃗ = ( x 1 , x 2 , . . , x d ) f(\vec{x}), \quad \vec{x}=\left(x_{1}, x_{2}, . ., x_{d}\right) f(x),x=(x1,x2,..,xd)
2.定义组内迭代次数 g r o u p _ i t e r {group\_iter} group_iter、吸引率 a t t r a c t i o n _ r a t e {attraction\_rate} attraction_rate、生长率 g r o w t h _ r a t e {growth\_rate} growth_rate、繁殖率 r e p r o d u c t i o n _ r a t e {reproduction\_rate} reproduction_rate、食肉植物数量 n C P l a n t nCPlant nCPlant和猎物数量 n P r e y nPrey nPrey
3.随机初始化大小为 n n n、维度为 d d d的种群
4.评估每个个体的适应度值
5.找到最优个体 g ∗ g^* g∗作为排名第一的食肉植物
6.Repeat until 满足终止条件
7. 将排名前 n C P l a n t nCPlant nCPlant的个体分类为食肉植物
8. 将剩余的 n P r e y nPrey nPrey个个体分类为猎物
9. 将食肉植物和猎物进行分组
10. // 食肉食物和猎物的生长过程
11. for i = 1 : n C P l a n t i=1:nCPlant i=1:nCPlant
12. for G r o u p _ c y c l e = 1 : g r o u p _ i t e r Group\_cycle=1:{group\_iter} Group_cycle=1:group_iter
13. if a t t r a c t i o n _ r a t e > 随 机 数 {attraction\_rate}>随机数 attraction_rate>随机数
14. 根据式(6)生成新的食肉植物
15. else
16. 根据式(8)生成新的猎物
17. end for
18. end for
19. //最优食肉植物的繁殖过程
20. for i = 1 : n C P l a n t i=1:nCPlant i=1:nCPlant
21. 根据式(10)基于最优食肉植物生成新的食肉植物
22. end for
23. 评估新生成的每个食肉植物和猎物
24. 合并之前和新生成的食肉植物和猎物
25. 对个体进行排序,并选择前 n n n个个体进入下一代
26. 确定当前最优个体 g ∗ g^* g∗作为排名第一的食肉植物
27.end while
28.展示当前最优解 g ∗ g^* g∗















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











