







在量化领域,Pandas是不可或缺的工具,它以强大的数据处理和分析功能,极大地简化了数据操作流程。
今天我们介绍两个技巧,都跟因子检验场景相关。第一个技巧是日期按月对齐;第二个是如何提取分组的前n条记录。讲解的概念涉及到group操作、索引的frequency概念以及多级索引的操作(读取和删除)。
在最后一个例子中,更是反复使用了groupby,以简洁的语法,完成了一个略为复杂的数据操作。
日期按月对齐
我们在做因子检验的时候,如果使用的是日线以上的频率,依赖于所使用的数据源,就有可能遇到这样一种情况:比如,今年的1月份收盘日是1月31日,但个股可能在1月31日停牌,那么数据源传给我们的月线,就可能把日期标注在1月30日。也就是,我们在生成月度因子数据时,有的个股的日期是1月31日,有的则是1月30或者更早的时间。
如果我们使用Alphalens来进行因子检验,就会产生日期无法对齐,计算前向收益出错的问题。不过,这不是我们今天要介绍的问题。我们今天只讲解决方案,即如何实现所有个股的因子日期都对齐到月。
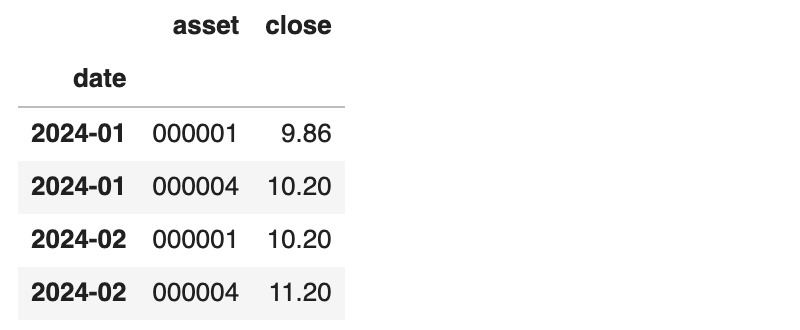
假设我们有以下数据:

这里无论是1月还是2月,两个个股的收盘日期都不一致。最简单的方案是使用index.to_period函数,将日期对齐到月份。
df.index = df.index.to_period(freq='M')
经过转换,就会生成下面的结果:
这样的转换尽管实现了对齐,但会丢失具体的日期信息。我们也可以使用groupby来实现同样的功能:
(df
.groupby(['asset', pd.Grouper(freq='M')])
.last()
.reset_index("asset")
结果是:

语法要点是,asset与index构成一个事实上的惟一索引,我们现在要调整索引的日期,按’asset’进行分组,并且通过Grouper来指定分组的频率。Grouper是作用在索引上的。
.last()提供了如何从分组记录中选取记录的功能。它是一种聚合函数,除此之外,还有first, min, max, mean等。在我们的例子中,由于asset与index构成一个惟一的索引,所以,无论使用first, last还是min, max,结果都一样。
提取分组的前n条记录
假如,我们通过因子检验,已经确认了某个因子有效,想使用test数据集来进行验证。test数据集也由好多期数据组成,我们需要对每一期数据,取前20%的股票,然后计算它在之后的T1~T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











