







Chapter 6 -Fine-tuning for classification
6.7-Finetuning the model on supervised data
-
在本节中,我们定义并使用训练函数来提高模型的分类精度
下面的train_classifier_simple函数实际上与我们在第5章中用于预训练模型的train_model_simple函数相同
唯一的两个区别是我们现在- 跟踪看到的训练示例的数量(‘examples_seen’),而不是看到的token数量
- 计算每个epoch后的准确性,而不是在每个epoch后打印示例文本

PyTorch 中训练深度神经网络的典型训练循环需在多轮次中遍历训练集批次,通过计算批次损失确定梯度以更新模型权重来降低损失。实现相关概念的训练函数与预训练所用的
train_model_simple函数相似,区别在于跟踪训练样本数而非标记数,且每轮次后计算准确率而非打印示例文本 。 -
训练代码
# Overall the same as `train_model_simple` in chapter 5 def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs, eval_freq, eval_iter): # Initialize lists to track losses and examples seen train_losses, val_losses, train_accs, val_accs = [], [], [], [] examples_seen, global_step = 0, -1 # Main training loop for epoch in range(num_epochs): model.train() # Set model to training mode for input_batch, target_batch in train_loader: optimizer.zero_grad() # Reset loss gradients from previous batch iteration loss = calc_loss_batch(input_batch, target_batch, model, device) loss.backward() # Calculate loss gradients optimizer.step() # Update model weights using loss gradients examples_seen += input_batch.shape[0] # New: track examples instead of tokens global_step += 1 # Optional evaluation step if global_step % eval_freq == 0: train_loss, val_loss = evaluate_model( model, train_loader, val_loader, device, eval_iter) train_losses.append(train_loss) val_losses.append(val_loss) print(f"Ep {epoch+1} (Step {global_step:06d}): " f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}") # Calculate accuracy after each epoch train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter) val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter) print(f"Training accuracy: {train_accuracy*100:.2f}% | ", end="") print(f"Validation accuracy: {val_accuracy*100:.2f}%") train_accs.append(train_accuracy) val_accs.append(val_accuracy) return train_losses, val_losses, train_accs, val_accs, examples_seentrain_classifier_simple中使用的evaluate_model函数与我们在第 5 章中使用的函数相同# Same as chapter 5 def evaluate_model(model, train_loader, val_loader, device, eval_iter): model.eval() with torch.no_grad(): train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter) val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter) model.train() return train_loss, val_loss -
接下来,我们初始化优化器,设置训练周期的数量,并使用
thetrain_classifier_simple函数启动训练。import time start_time = time.time() torch.manual_seed(123) optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1) num_epochs = 5 train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple( model, train_loader, val_loader, optimizer, device, num_epochs=num_epochs, eval_freq=50, eval_iter=5, ) end_time = time.time() execution_time_minutes = (end_time - start_time) / 60 print(f"Training completed in {execution_time_minutes:.2f} minutes.") """输出""" Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392 Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637 Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557 Training accuracy: 70.00% | Validation accuracy: 72.50% Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489 Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397 Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353 Training accuracy: 82.50% | Validation accuracy: 85.00% Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320 Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306 Training accuracy: 90.00% | Validation accuracy: 90.00% Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200 Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132 Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137 Training accuracy: 100.00% | Validation accuracy: 97.50% Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143 Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074 Training accuracy: 100.00% | Validation accuracy: 97.50% Training completed in 0.67 minutes.在M3 MacBook Air笔记本电脑上训练大约需要6分钟,在V100或A100 GPU上训练不到半分钟,我的电脑是windows,显卡3060 12G,训练总时长 40s (0.67minutes)。
-
然后我们使用Matplotlib绘制训练和验证集的损失函数。
import matplotlib.pyplot as plt def plot_values(epochs_seen, examples_seen, train_values, val_values, label="loss"): fig, ax1 = plt.subplots(figsize=(5, 3)) # Plot training and validation loss against epochs ax1.plot(epochs_seen, train_values, label=f"Training {label}") ax1.plot(epochs_seen, val_values, linestyle="-.", label=f"Validation {label}") ax1.set_xlabel("Epochs") ax1.set_ylabel(label.capitalize()) ax1.legend() # Create a second x-axis for examples seen ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis ax2.plot(examples_seen, train_values, alpha=0) # Invisible plot for aligning ticks ax2.set_xlabel("Examples seen") fig.tight_layout() # Adjust layout to make room plt.savefig(f"{label}-plot.pdf") plt.show()epochs_tensor = torch.linspace(0, num_epochs, len(train_losses)) examples_seen_tensor = torch.linspace(0, examples_seen, len(train_losses)) plot_values(epochs_tensor, examples_seen_tensor, train_losses, val_losses)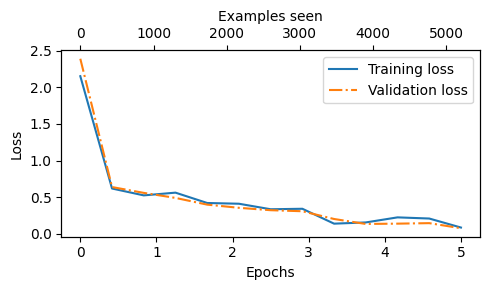
早些时候,当我们启动训练时,我们将训练的轮数(epochs)设置为 5。轮数的选择取决于数据集和任务的难度,虽然没有通用的解决方案或推荐值,但 5 轮通常是一个不错的起点。如果在前几轮训练后,模型出现过拟合现象,则可能需要减少轮数。相反,如果趋势线表明验证损失可能随着进一步训练而改善,则应增加轮数。在本例中,5 轮是一个合理的数值,因为没有出现早期过拟合的迹象,且验证损失接近 0。
现在使用相同的plot_values函数,现在让我们绘制分类精度:
epochs_tensor = torch.linspace(0, num_epochs, len(train_accs)) examples_seen_tensor = torch.linspace(0, examples_seen, len(train_accs)) plot_values(epochs_tensor, examples_seen_tensor, train_accs, val_accs, label="accuracy")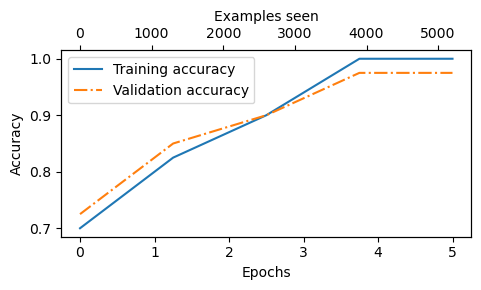
基于上面的准确度图,我们可以看到模型在第 4 和第 5 阶段之后实现了相对较高的训练和验证准确度但是,我们必须记住,我们之前在训练函数中指定了 “eval_iter=5”,这意味着我们只估计了训练和验证集的性能,我们可以计算完整数据集的训练、验证和测试集性能,如下所示。
train_accuracy = calc_accuracy_loader(train_loader, model, device) val_accuracy = calc_accuracy_loader(val_loader, model, device) test_accuracy = calc_accuracy_loader(test_loader, model, device) print(f"Training accuracy: {train_accuracy*100:.2f}%") print(f"Validation accuracy: {val_accuracy*100:.2f}%") print(f"Test accuracy: {test_accuracy*100:.2f}%") """输出""" Training accuracy: 97.21% Validation accuracy: 97.32% Test accuracy: 95.67%训练集和测试集的性能几乎相同。训练集和测试集准确率之间的细微差异表明训练数据的过拟合程度极低。通常情况下,验证集的准确率会比测试集的准确率略高一些,这是因为模型开发过程中常常需要调整超参数,以使模型在验证集上表现良好,但这些调整后的超参数可能无法同样有效地泛化到测试集上。这种情况很常见,不过,可以通过调整模型设置来尽可能缩小这一差距,比如在优化器配置中提高丢弃率(drop_rate)或权重衰减参数(weight_decay) 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









