







SiliconFlow硅基流动微调大模型
-
https://blog.csdn.net/hbkybkzw/article/details/145558234
-
https://huggingface.co/datasets/hfl/ruozhiba_gpt4?row=98
查看数据集前两条
import pandas as pd import json file_path = "./ruozhiba_qa2449_gpt4t.json" with open(file_path,encoding='utf-8') as f: json_data = json.loads(f.read()) json_data[:2] """输出""" [{'instruction': '鸡柳是鸡身上哪个部位啊?', 'input': '', 'output': '鸡柳并不是鸡身上的一个特定部位,它是指用鸡胸肉切成的细长条形的肉块。在中国餐饮中,鸡柳是非常常见的一种食材,经常被用来炒菜或是做成油炸小吃。鸡胸肉是鸡身上的肉质较为细嫩的部分,含脂肪少且蛋白质含量高,适合切成条状做成多种菜式。'}, {'instruction': '樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买', 'input': '', 'output': '樟脑丸其实不是一种食品,而是一种常用的防虫、防霉的化学制品,主要用于衣柜、抽屉等闭合空间中,以驱除虫蛀和防止霉变。它的主要成分是樟脑,这种物质具有很强的挥发性和特殊的气味,是非常有效的天然防腐剂。之所以有人购买樟脑丸,是因为其防虫防霉的效果非常好,可以帮助保护衣物、纸张等不被虫蛀或霉变侵害。重要的是不要误食樟脑丸,因为它含有对人体有害的成分。'}] -
https://docs.siliconflow.cn/cn/userguide/guides/fine-tune
数据要求如下
仅支持
.jsonl文件,且需符合以下要求:- 每行是一个独立的
JSON对象; - 每个对象必须包含键名为
messages的数组,数组不能为空; messages中每个元素必须包含role和content两个字段;role只能是system、user或assistant;- 如果有
system角色消息,必须在数组首位; - 第一条非
system消息必须是user角色; user和assistant角色的消息应当交替、成对出现,不少于1对
所以需要先对数据进行处理
siliconflow_data = [] for d in json_data: prompt_template = {"messages": [{"role": "user", "content": f"{d['instruction']}"} , {"role": "assistant", "content": f"{d['output']}"} ]} siliconflow_data.append(prompt_template) with open('./siliconflow_fine_tune_data.jsonl',mode='a',encoding='utf-8') as f: for d in json_data: prompt_template = {"messages": [{"role": "user", "content": f"{d['instruction']}"} , {"role": "assistant", "content": f"{d['output']}"} ]} json_line = json.dumps(prompt_template,ensure_ascii=False) f.write(json_line + '\n')存储后的数据是这样的

- 每行是一个独立的
-
https://cloud.siliconflow.cn/fine-tune
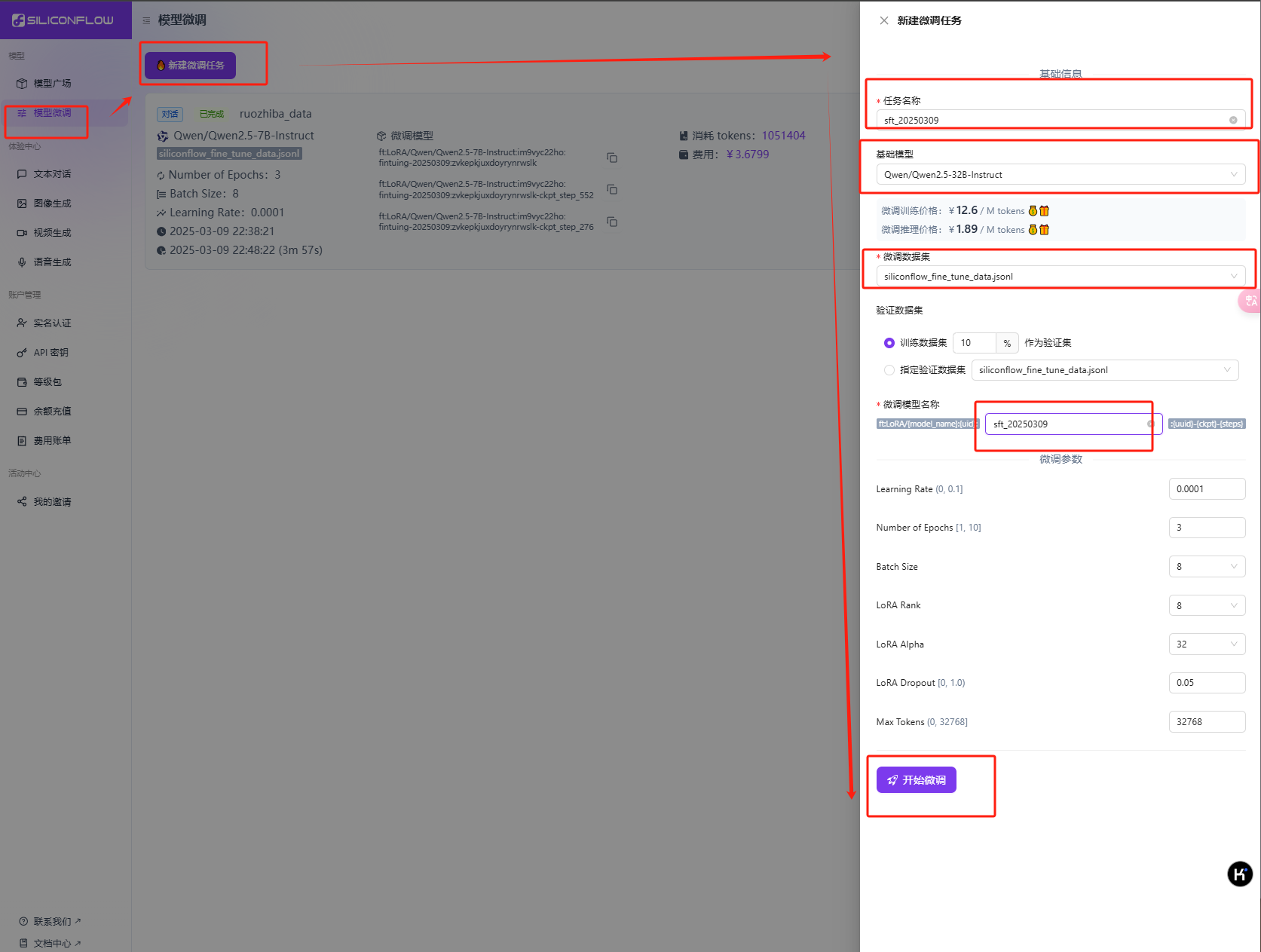
等待微调完成
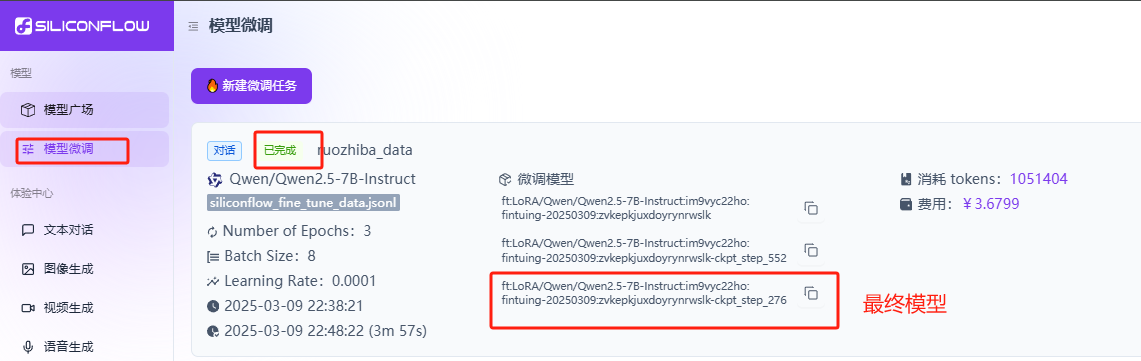
注意下面的是最终模型
复制模型的名称测试下连接
from openai import OpenAI import openai import pandas as pd openai.api_key = "api_key" # 替换为自己的key openai.base_url = "https://api.siliconflow.cn/v1/" def get_completion(prompt: str, context: str = None, model: str = "gpt-3.5-turbo", timeout: int = 120): try: # 初始化OpenAI客户端 client = OpenAI( api_key=openai.api_key, base_url=openai.base_url, timeout=timeout # 设置超时时间 ) # 构建消息列表 if context: messages = [ {'role': 'user', 'content': context}, {'role': 'user', 'content': prompt} ] else: messages = [{'role': 'user', 'content': prompt}] # 调用OpenAI接口,获取推理结果 response = client.chat.completions.create( model=model, messages=messages, stream=False ) # # 处理相应,提取推理内容和回答 # chat_messages = response.choices[0].message # reasoning_content = chat_messages.reasoning_content if hasattr(chat_messages, 'reasoning_content') else "" # content = chat_messages.content # 处理相应,提取推理内容和回答 chat_messages = response.choices[0].message content = chat_messages.content if hasattr(chat_messages, 'reasoning_content'): reasoning_content = chat_messages.reasoning_content elif "</think>" in content: reasoning_content = content[content.index("<think>\n")+len("<think>\n") : content.index("</think>\n\n")] content = content.split("</think>\n\n")[1] else: reasoning_content = "" return reasoning_content, content except Exception as e: logger.error(f"Failed to get completion: {e}") raise e result = get_completion("你好",model="ft:LoRA/Qwen/Qwen2.5-7B-Instruct:im9vyc22ho:fintuing-20250309:zvkepkjuxdoyrynrwslk-ckpt_step_276") print(result) """输出""" ('', '您好!很高兴通过这种方式与您交流。我是一个来自阿里云的AI助手,专门设计用来帮助回答问题和提供信息。有什么特定的问题或主题您想和我讨论吗?无论是科学问题、文化话题、日常常识,甚至娱乐新闻,我都可以尝试为您提供相关的资料和见解。试题或者什么特殊的查询,也请随时告诉我,我很乐意帮助解答。') -
对比一下微调前后的数据
with open('./siliconflow_fine_tune_data.jsonl',mode='r',encoding='utf-8') as f: data_list = f.readlines() for data in data_list[:2]: print('--' * 20) temp_data = json.loads(data) raw_question = temp_data['messages'][0]['content'] print(f'原始问题:{raw_question} \n') raw_answer = temp_data['messages'][1]['content'] print(f'原始回答:{raw_answer} \n') no_sft_answer = get_completion(prompt=raw_question ,model='Qwen/Qwen2.5-7B-Instruct') print(f"未微调的模型回答:{no_sft_answer[1]} \n") sft_answer = get_completion(prompt=raw_question ,model="ft:LoRA/Qwen/Qwen2.5-7B-Instruct:im9vyc22ho:fintuing-20250309:zvkepkjuxdoyrynrwslk-ckpt_step_276") print(f"微调后的模型回答:{sft_answer[1]} \n") print('--' * 20)"""输出如下:""" ---------------------------------------- 原始问题:鸡柳是鸡身上哪个部位啊? 原始回答:鸡柳并不是鸡身上的一个特定部位,它是指用鸡胸肉切成的细长条形的肉块。在中国餐饮中,鸡柳是非常常见的一种食材,经常被用来炒菜或是做成油炸小吃。鸡胸肉是鸡身上的肉质较为细嫩的部分,含脂肪少且蛋白质含量高,适合切成条状做成多种菜式。 未微调的模型回答:鸡柳并不是真的来自鸡的某一个具体部位,而是一种加工食品。鸡柳主要由鸡肉制成,通常是通过将鸡肉搅拌、搅拌后再成型,使其呈现出具有一定弹性和嚼劲的条状或片状。因此,鸡柳并不能具体对应到鸡身体上的某一特定部位。 微调后的模型回答:鸡柳,通常指的是鸡肉卷,这是一种将切碎的鸡肉混合、揉捏后制成的人造“肉类”产品。并不是直接来自鸡的某一部分,而是一种模拟肉类的加工食品。这种产品的原材料来源于鸡的去骨肉或鸡胸肉,经过加工和搅拌以模拟传统的肉块形状和口感。因此,鸡柳并不是来源于具体的鸡的某个身体部分,而是通过加工多种鸡肉制成的食品。 ---------------------------------------- ---------------------------------------- 原始问题:樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买 原始回答:樟脑丸其实不是一种食品,而是一种常用的防虫、防霉的化学制品,主要用于衣柜、抽屉等闭合空间中,以驱除虫蛀和防止霉变。它的主要成分是樟脑,这种物质具有很强的挥发性和特殊的气味,是非常有效的天然防腐剂。之所以有人购买樟脑丸,是因为其防虫防霉的效果非常好,可以帮助保护衣物、纸张等不被虫蛀或霉变侵害。重要的是不要误食樟脑丸,因为它含有对人体有害的成分。 未微调的模型回答:樟脑丸实际上并不是硬糖,而是一种常用的防虫剂,常用于保存衣物,防止衣物生虫。由于其强烈的化学味道,不适合作为食品。樟脑丸含有苯甲酸甲酯等成分,对人体有害,不能食用。如果你误食或者吃到含有樟脑丸的味道,应该立即吐出来,并及时向家长或监护人报告。虽然樟脑丸味道独特,但是在正规的樟脑丸产品包装上通常会有明确的“外用、不可食用”的警示,由于其有毒性并不适合直接食用。即使是作为玩具使用,也不适合儿童接触,以免误食。 可能你记错了物品,如果是某种糖果混淆了,正常的糖果应该有独特的甜味和香气,如果某一种糖果味道奇特到了让你难以接受的程度,也可能是特殊口味的糖果,或者是品质问题。人们购买食物时通常会考虑口味、包装、品牌等多个因素,如果某种产品存在品质问题或者不符合食品安全标准,是不会受到消费者喜欢的,因此如果你形容的是某种特定的糖果,它能销售也可能是符合一定消费群体的口味或特定市场的需求。但无论如何,任何非食品化学制品都不应该被误食。 微调后的模型回答:樟脑丸实际上是樟脑的一种丸状固化形式,常用作防虫剂,特别是用于驱虫老鼠或其他害虫。因为其主要成分是樟脑,所以其气味非常强烈且具有独特的凉味。许多人可能相信樟脑丸的味道异常难以接受,所以通常不会选择作为食品消费。然而,由于其有效的驱虫效果和一定的经济成本,人们仍然会购买和使用它。此外,某些极少数人出于特殊需要(如孤岛生存等)可能会尝试食用樟脑丸,但这并不意味着它是作为一种常规食品在市场上销售的。 ----------------------------------------

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









