









Qwen3-30B-A3B部署(使用vllm和sglang)
-
模型:Qwen3-30B-A3B
-
显卡:4090 4 张
-
python版本
python 3.12
-
重要包的版本
vllm==0.8.6 sglang== 0.4.6.post1 -
阿里云Qwen发布的微信公众号链接
https://mp.weixin.qq.com/s/UZE5T7iyFqbXS05ReouOzw
安装
模型下载
-
使用modelscope下载,需要安装modelscope库
pip install modelscope已经有modelscope库的需要升级下面的几个包
pip install --upgrade modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple pip install --upgrade transformers -i https://pypi.tuna.tsinghua.edu.cn/simple pip install --upgrade peft -i https://pypi.tuna.tsinghua.edu.cn/simple pip install --upgrade diffusers -i https://pypi.tuna.tsinghua.edu.cn/simple -
下载
默认下载在当前用户的.cache文件夹下,比如现在是root用户,则默认在
/root/.cache/modelscope/hub/models/Qwen/Qwen3-30B-A3B
我们希望将其下载在
/root/Qwen/Qwen3-30B-A3B
from modelscope.hub.snapshot_download import snapshot_download model_name = "Qwen/Qwen3-30B-A3B" cache_dir = "/root" # 替换为你希望的路径 snapshot_download(model_name, cache_dir=cache_dir)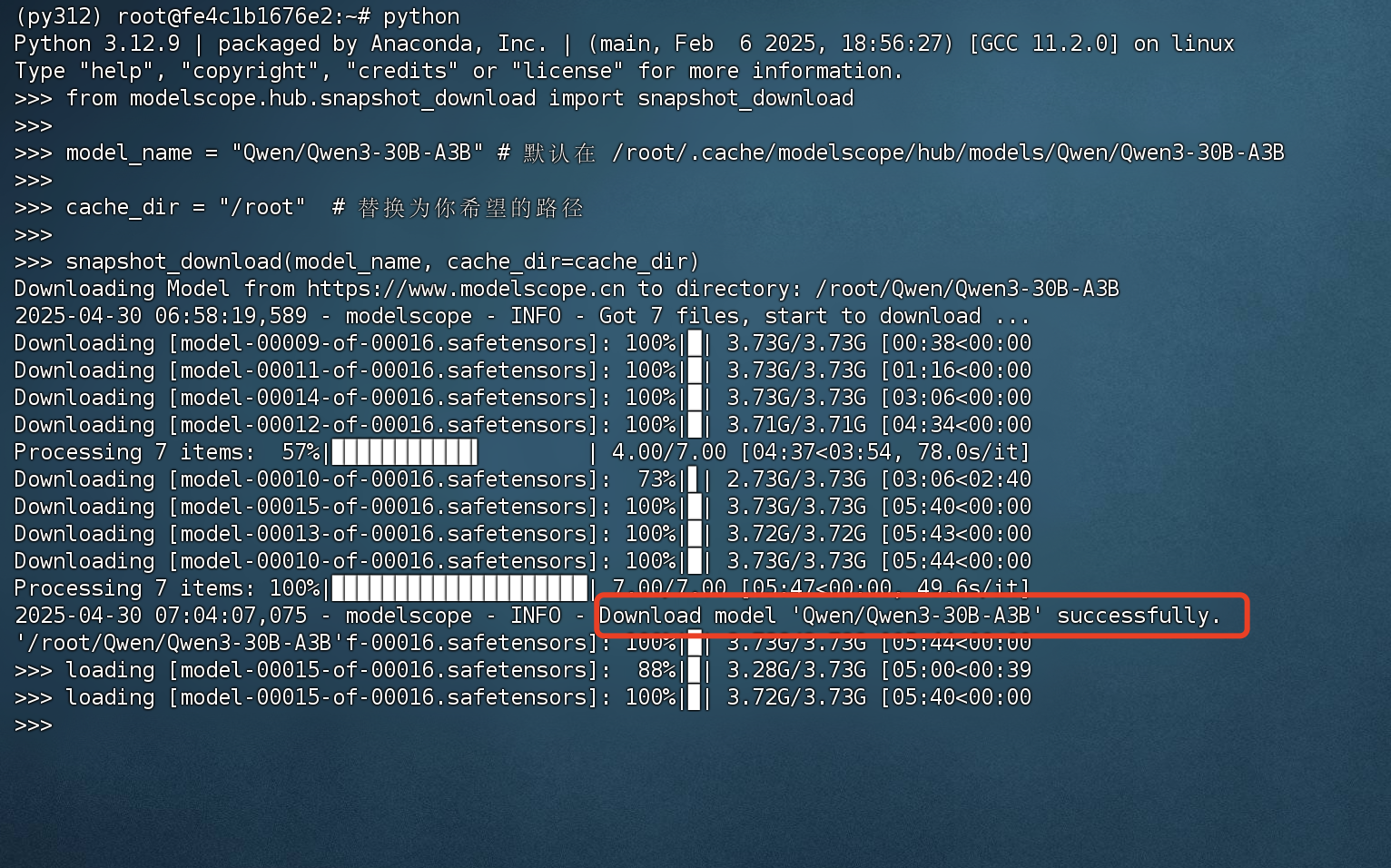
-
下载完成后查看下
ls -lha /root/Qwen/Qwen3-30B-A3B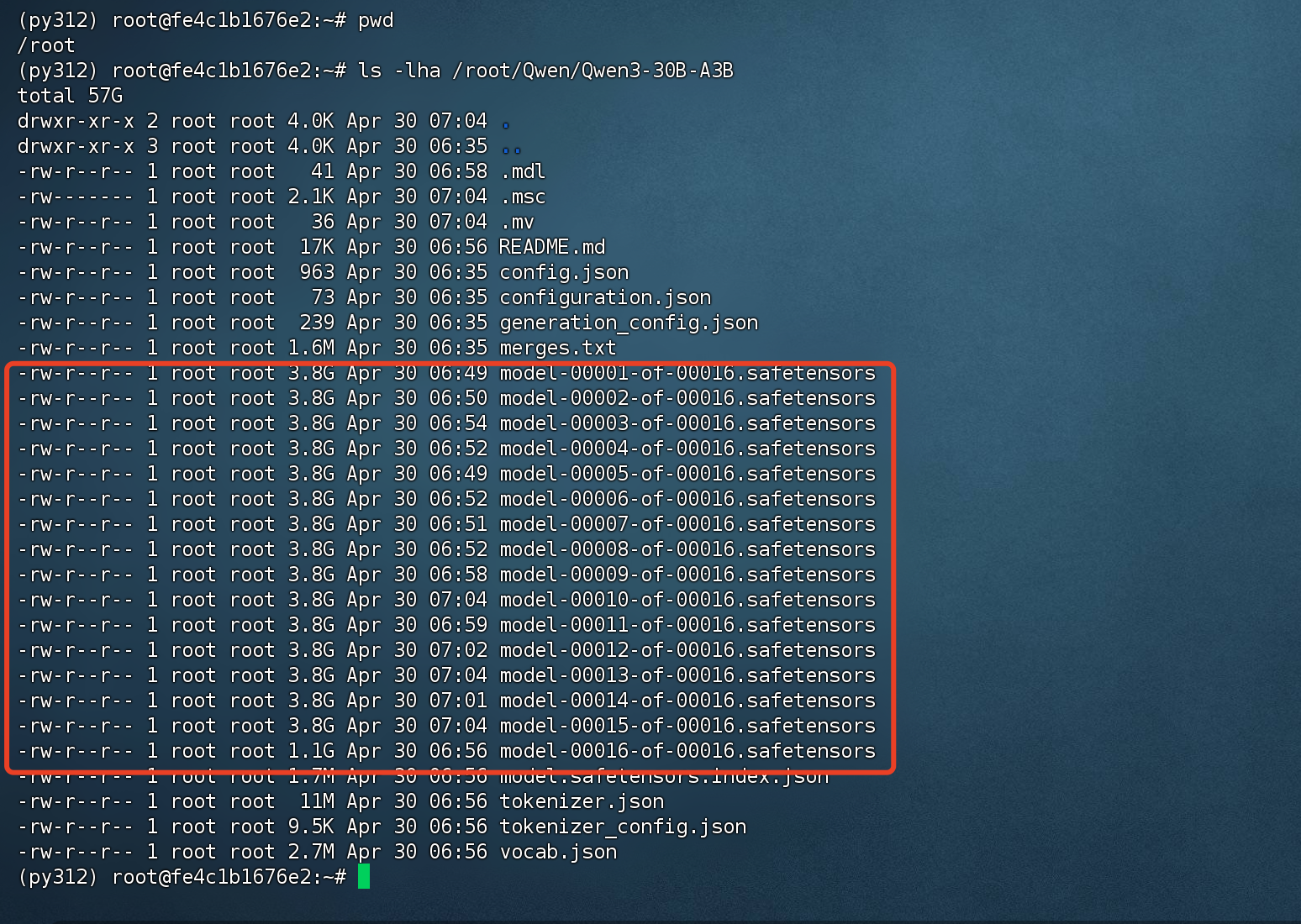
-
按照官方提供的测试代码就是如下的,不过我们后续使用vllm和sglan启动
from modelscope import AutoModelForCausalLM, AutoTokenizer import time model_name = "/root/Qwen/Qwen3-30B-A3B" cache_dir = '/root' tokenizer = AutoTokenizer.from_pretrained(model_name,local_files_only=True) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto", low_cpu_mem_usage=True, local_files_only=True ) prompt = "介绍下你自己." messages = [ {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True # Switch between thinking an non-thinking modes, Default is True ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) # conduct text completion start_time = time.time() generated_ids = model.generate( **model_inputs, max_new_tokens=32768 ) end_time = time.time() - start_time() output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content try: # rindex finding 151668</think> index = len(output_ids) -output_ids[::-1].index(151668) except ValueError: index=0 thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n") content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n") print("thinking content:", thinking_content) print("content:", content)
环境安装
-
使用conda创建虚拟环境
conda create -n sglang python=3.12 conda activate sglang -
下载vllm(指定清华源,否则极慢)
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple -
下载sglang
pip install sglang -i https://pypi.tuna.tsinghua.edu.cn/simple pip install sgl_kernel -i https://pypi.tuna.tsinghua.edu.cn/simple -
后续使用中一些其他报错需要装的包
pip install orjson pip install torchao
vllm启动
-
vllm启动命令
CUDA_VISIBLE_DEVICES=0,1,2,3 \ vllm serve /root/Qwen/Qwen3-30B-A3B \ --tensor-parallel-size 4 \ --max-model-len 32768 \ --gpu-memory-utilization 0.8 \ --host 0.0.0.0 \ --port 8081 \ //--enable-reasoning --reasoning-parser deepseek_r1 \ --served-model-name Qwen3-30B-A3B-vllm以下是对VLLM启动命令参数的简要说明
参数 简要说明 CUDA_VISIBLE_DEVICES=0,1,2,3指定要使用的GPU设备编号,这里选择使用0、1、2、3四个GPU设备 vllm serve /root/Qwen/Qwen3-30B-A3B启动VLLM服务、指定模型路径 --tensor-parallel-size张量并行大小 --max-model-le模型处理的最大序列长度 --gpu-memory-utilization预分配的GPU内存比例 (vllm默认为0.9) --host设置服务监听的主机地址,0.0.0.0表示监听所有网络接口 --port设置服务监听的端口号 --enable-reasoning启用推理功能(think) --reasoning-parser指定推理解析器 --served-model-nam设置模型名 -
以8081端口启动成功
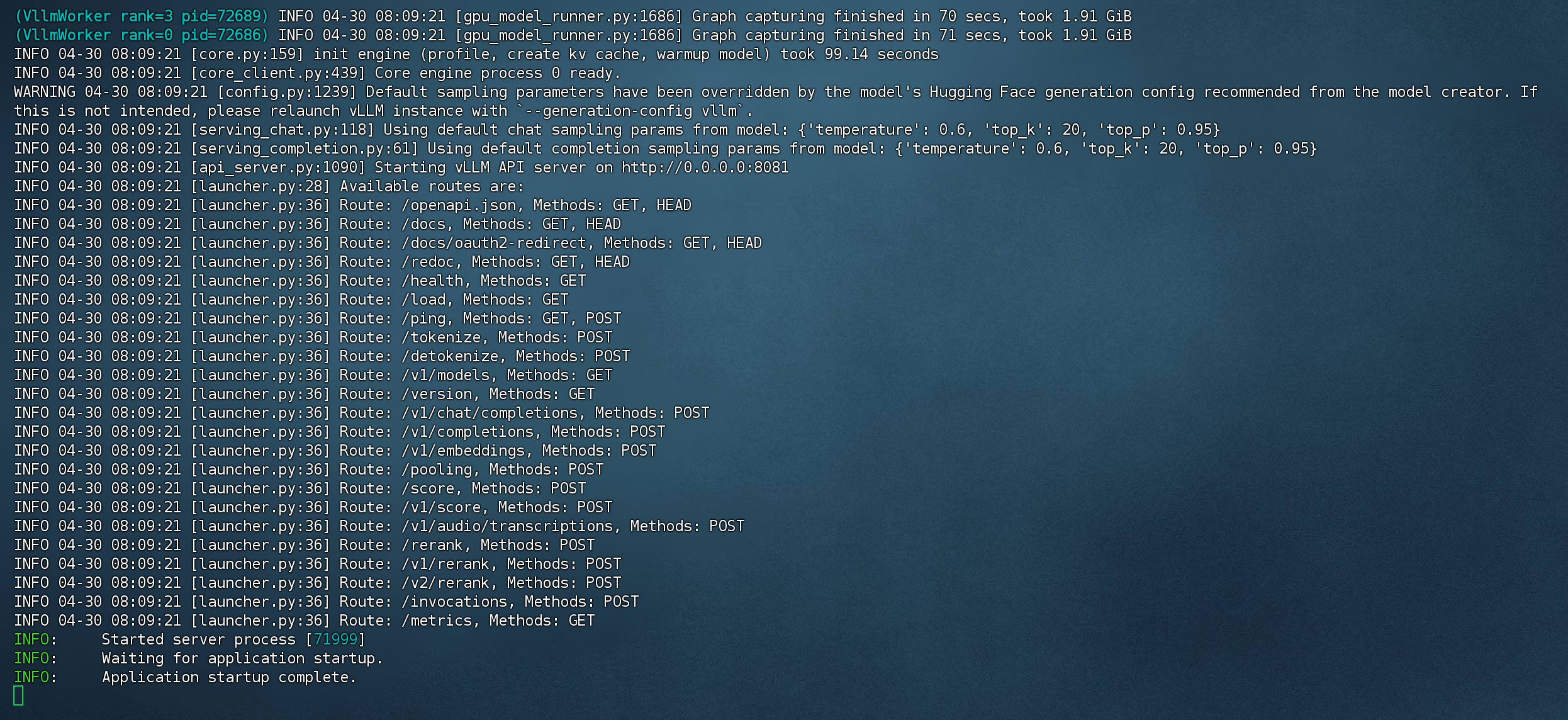
-
显存占用情况
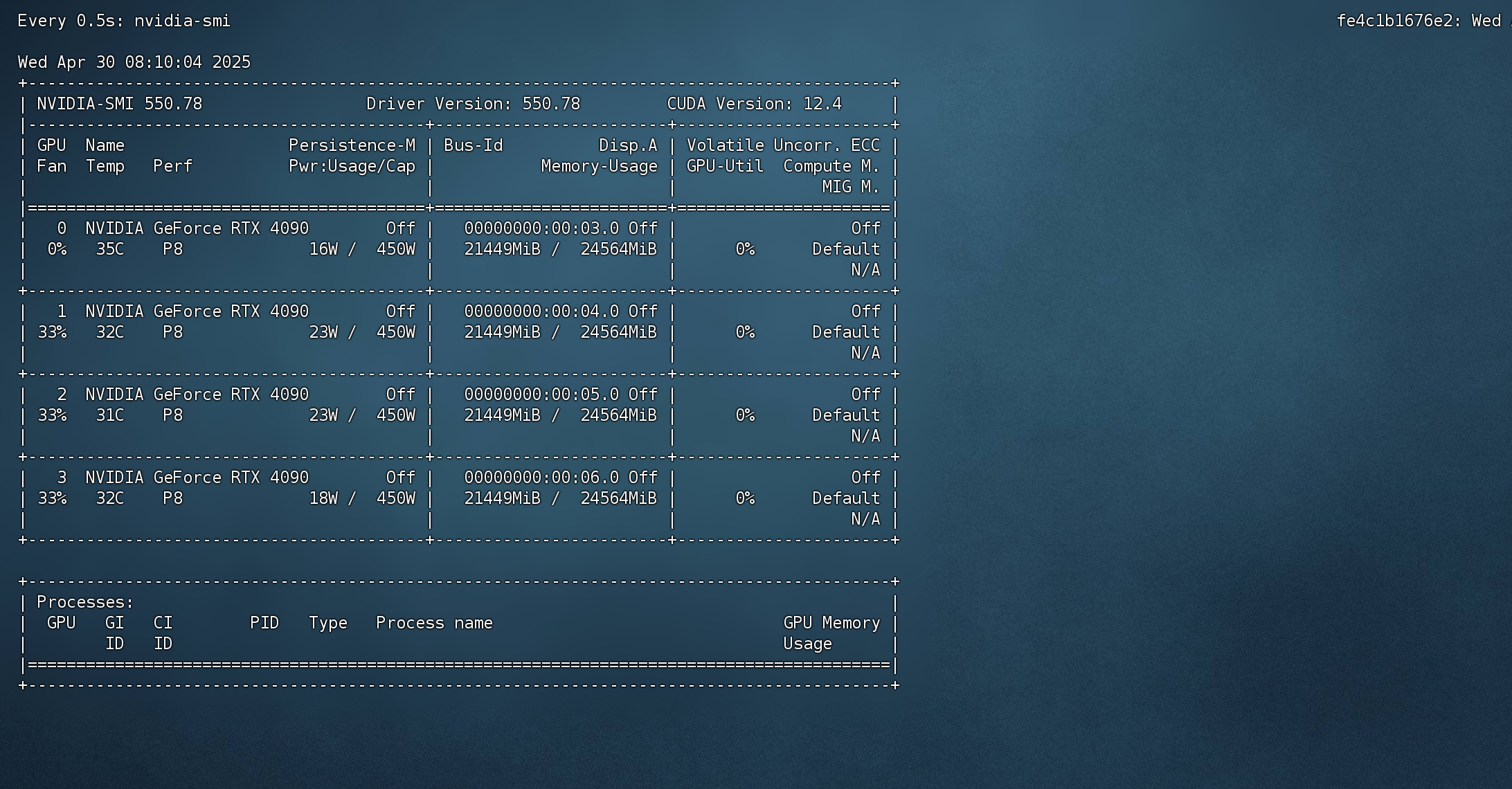
-
测试
测试代码
from openai import OpenAI import openai openai.api_key = '1111111' # 这里随便填一个 openai.base_url = 'http://127.0.0.1:8081/v1' def get_completion(prompt, model="QwQ-32B"): client = OpenAI(api_key=openai.api_key, base_url=openai.base_url ) messages = [{"role": "user", "content": prompt}] response = client.chat.completions.create( model=model, messages=messages, stream=False ) return response.choices[0].message.content prompt = '请计算straberry这个单词中字母r的出现次数' response = get_completion(prompt, model="Qwen3-30B-A3B-vllm" ) print(response)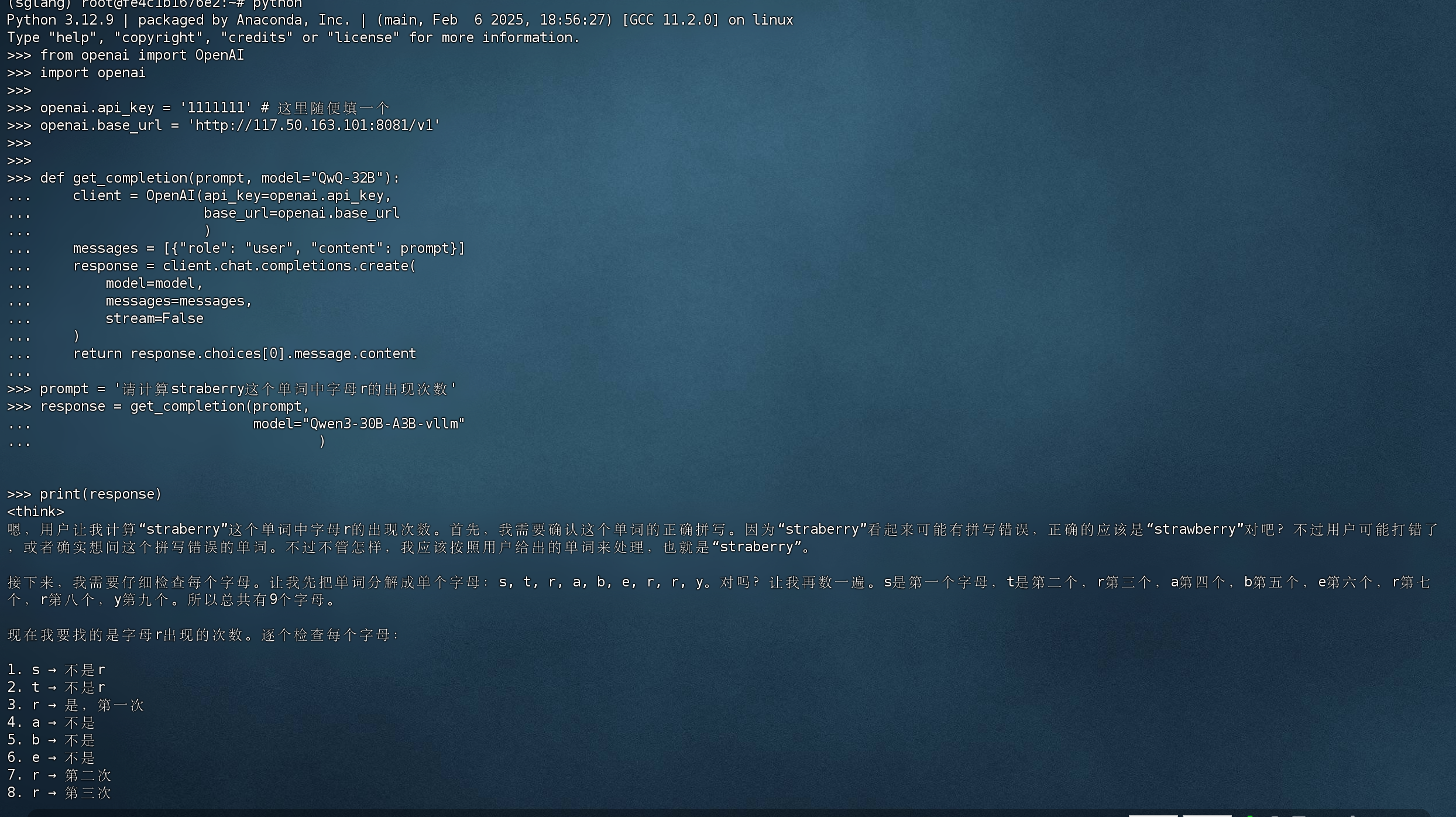
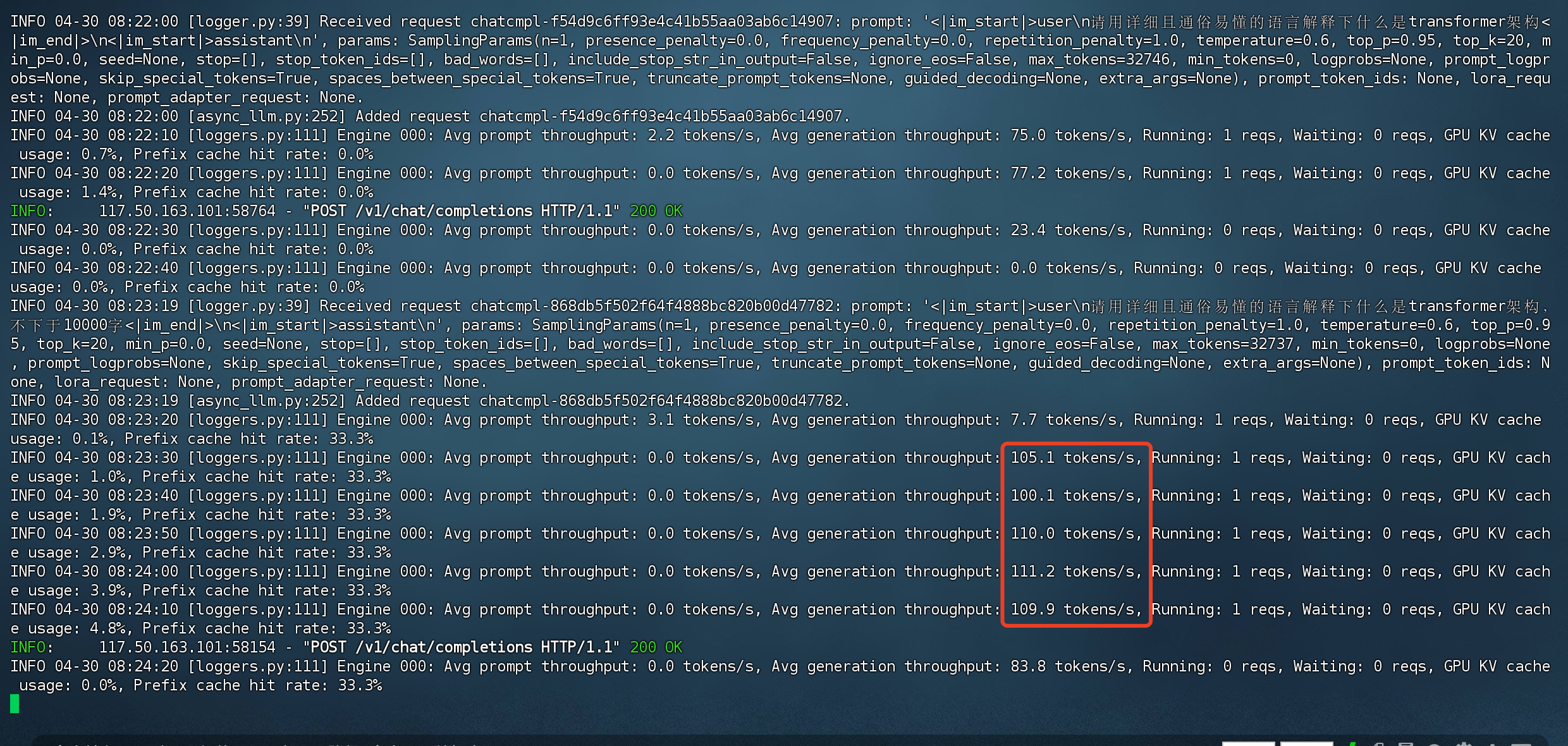
能到 100tokens/s
sglang启动
-
sglang启动命令
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m sglang.launch_server \ --model-path /root/Qwen/Qwen3-30B-A3B \ --tp 4 \ --max-prefill-tokens 32768 \ --mem-fraction-static 0.8 \ --host 0.0.0.0 \ --port 8081 \ --served-model-name Qwen3-30B-A3B参数说明:
参数 简要说明 CUDA_VISIBLE_DEVICES=0,1,2,3指定要使用的GPU设备编号,这里选择使用0、1、2、3四个GPU设备 python -m sglang.launch_server启动SGLang服务的主命令 --model-path指定模型权重的路径
可以是本地文件夹或Hugging Face仓库ID--tp张量并行大小 --max-prefill-tokens最大token长度 --mem-fraction-staticGPU内存使用比例 --hos设置服务监听的主机地址,0.0.0.0表示监听所有网络接口 --port 8081设置服务监听的端口号 --served-model-name模型名称(在API响应中使用) -
以8081端口启动成功
-
测试代码
from openai import OpenAI import openai openai.api_key = '1111111' # 这里随便填一个 openai.base_url = 'http://127.0.0.1:8081/v1' def get_completion(prompt, model="QwQ-32B"): client = OpenAI(api_key=openai.api_key, base_url=openai.base_url ) messages = [{"role": "user", "content": prompt}] response = client.chat.completions.create( model=model, messages=messages, stream=False ) return response.choices[0].message.content prompt = '请计算straberry这个单词中字母r的出现次数' response = get_completion(prompt, model="Qwen3-30B-A3B" ) print(response)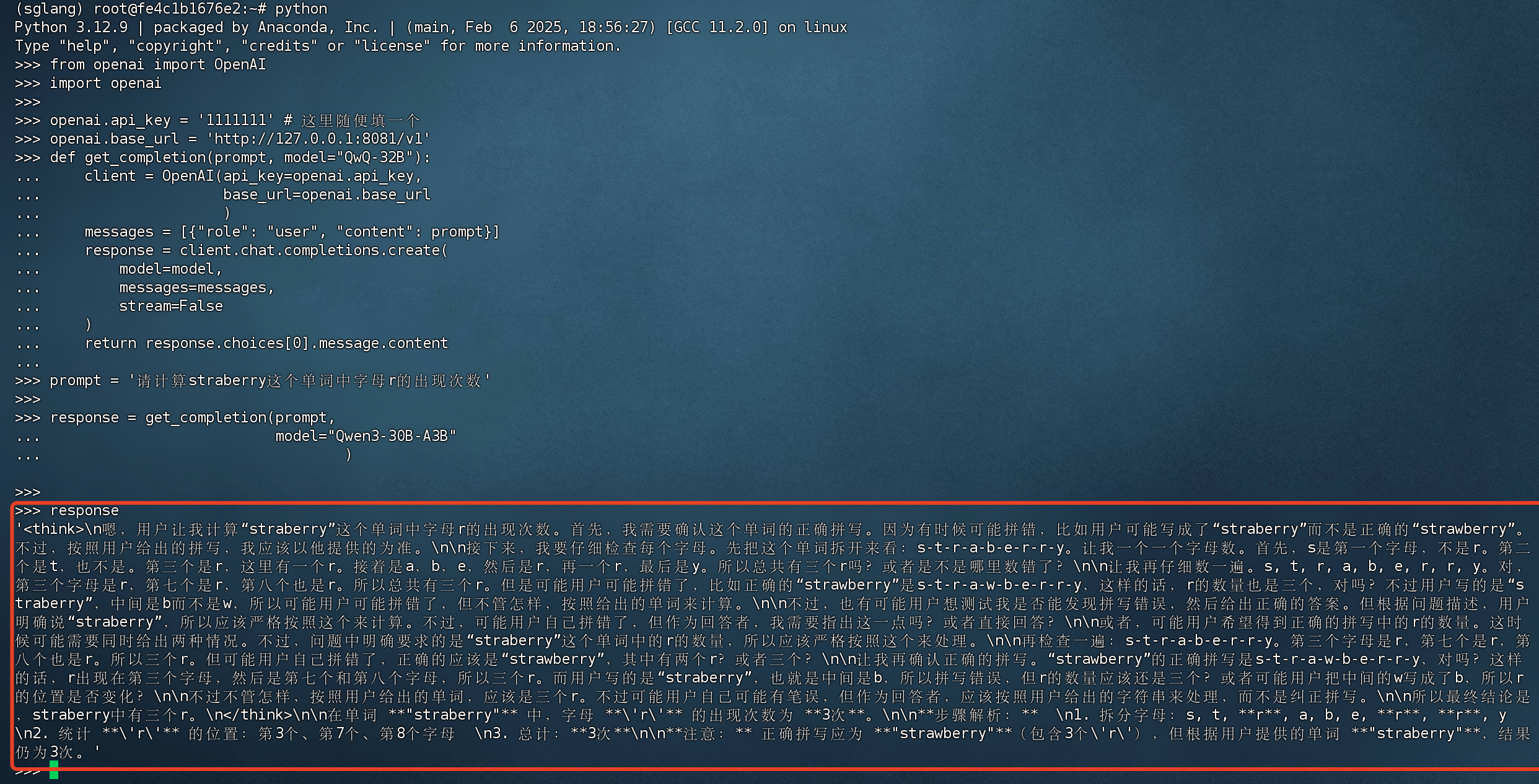
-
显存占用情况
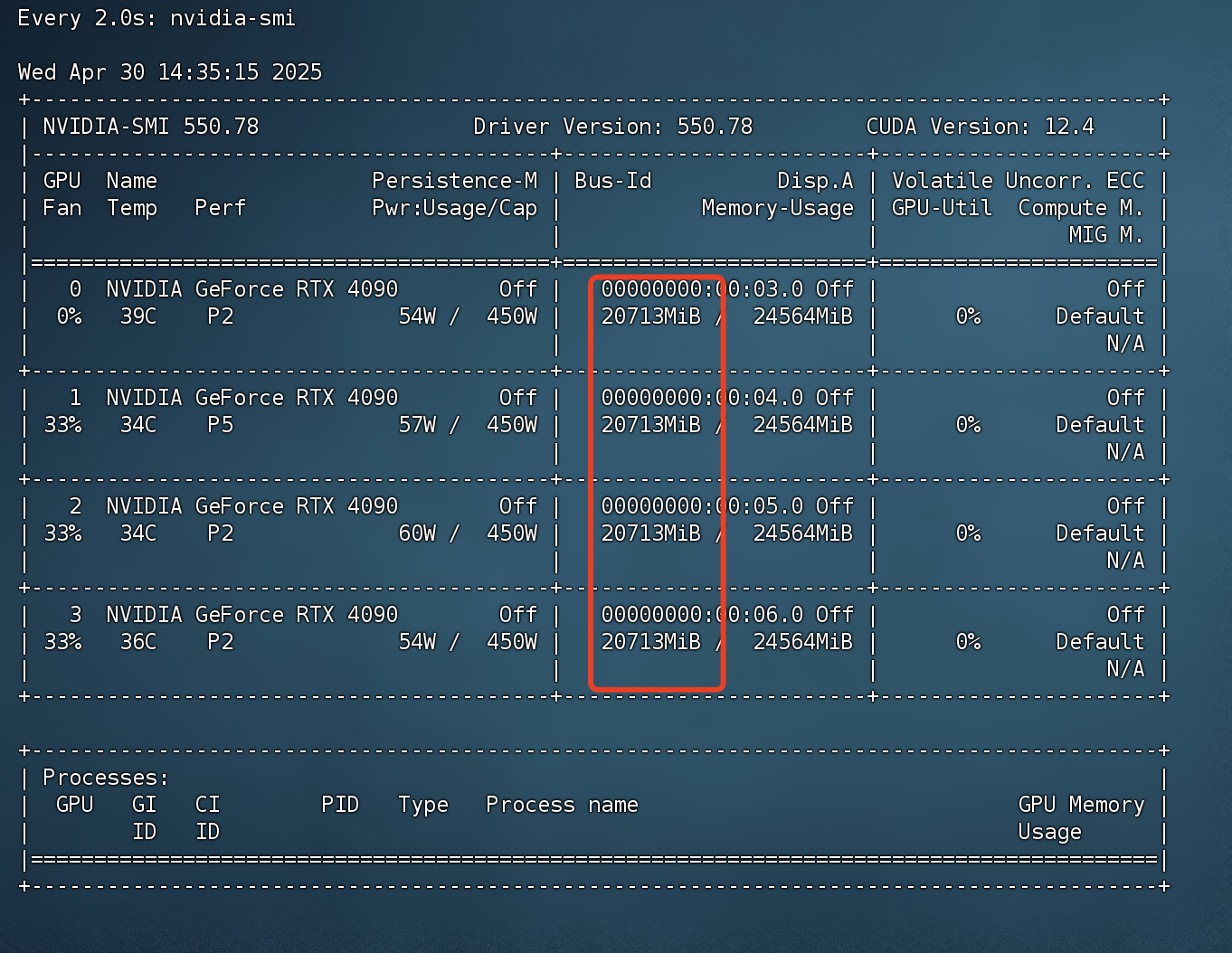
-
平均可以达到160 tokens /s
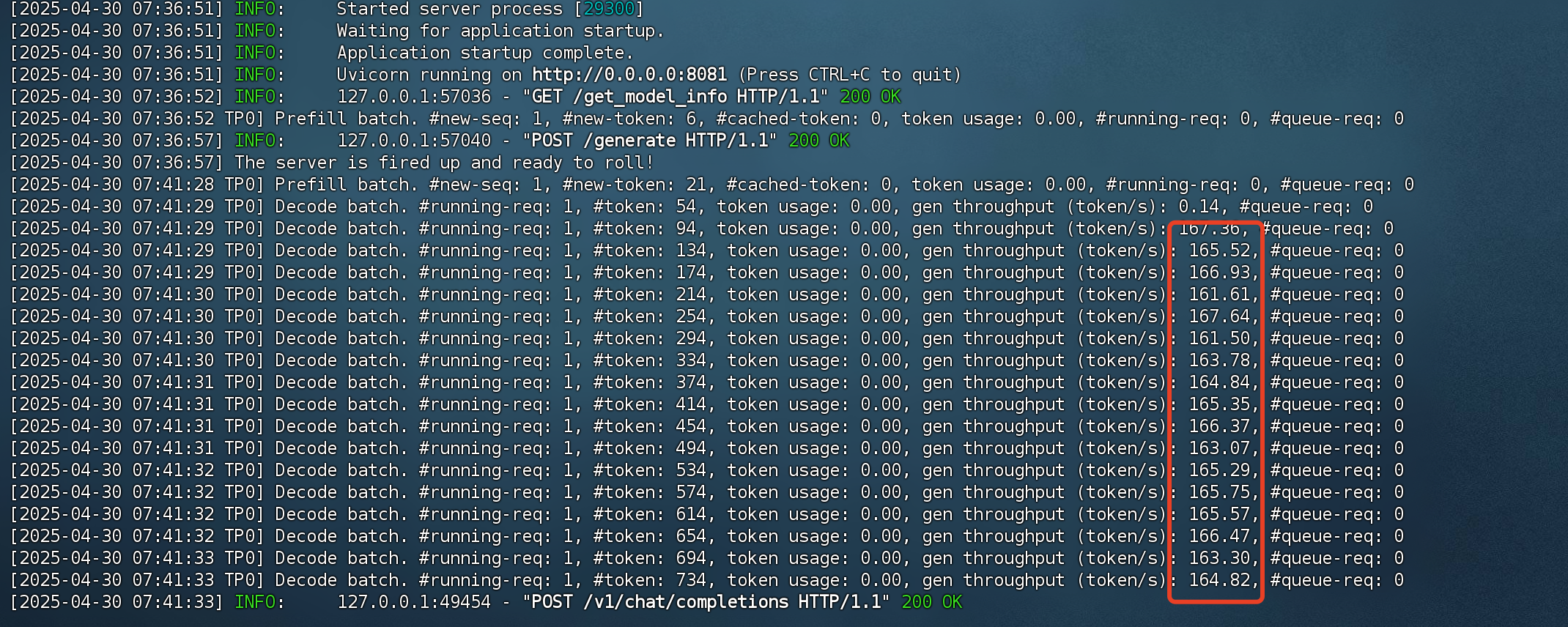
modelscope压测
压测结果
-
modelscope压测的方法可以看之前的博客
https://blog.csdn.net/hbkybkzw/article/details/147641988
-
GPU机器4卡4090,在自己电脑使用modelscope分别对vllm和sglang进行以下并发数的压测,都统一用的开放数据集
并发数列表
parallel_list = [1,5,10,20,30,40,50] -
vllm压测代码(使用
---.--.--.---隐藏了GPU机器的ip )from evalscope.perf.main import run_perf_benchmark def run_perf(parallel,model_name): task_cfg = { 'url': 'http://---.--.--.---:8081/v1/chat/completions', 'parallel': parallel, 'model': model_name, 'number': 100, 'api': 'openai', 'dataset': 'openqa', 'stream': True, 'debug': False, } run_perf_benchmark(task_cfg) model_name = 'Qwen3-30B-A3B-vllm' # vllm启动时设置的model_name parallel_list = [1,5,10,20,30,40,50] if __name__ == '__main__': for parallel in parallel_list: run_perf(parallel,model_name) -
sglang压测代码(使用
---.--.--.---隐藏了GPU机器的ip )from evalscope.perf.main import run_perf_benchmark def run_perf(parallel,model_name): task_cfg = { 'url': 'http://---.--.--.---:8081/v1/chat/completions', 'parallel': parallel, 'model': model_name, 'number': 100, 'api': 'openai', 'dataset': 'openqa', 'stream': True, 'debug': False, } run_perf_benchmark(task_cfg) model_name = 'Qwen3-30B-A3B' # sglang启动时设置的model_name parallel_list = [1,5,10,20,30,40,50] if __name__ == '__main__': for parallel in parallel_list: run_perf(parallel,model_name) -
整理了下压测结果如下
推理引擎 并发数 总请求数 成功数 失败数 总时长 每秒输出tokens 每秒总tokens qps 平均用时 平均首帧用时 生成每个token的平均时间 平均输入token长度 平均输出token长度 vllm 1 100 100 0 1120.52 110.20 112.78 0.09 11.20 0.15 0.01 28.89 1234.81 sglang 1 100 100 0 753.52 162.47 166.30 0.13 7.53 0.19 0.01 28.89 1224.24 vllm 5 100 100 0 375.81 323.67 331.35 0.27 18.57 0.17 0.02 28.89 1216.38 sglang 5 100 100 0 306.32 402.64 412.07 0.33 15.15 0.23 0.01 28.89 1233.38 vllm 10 100 100 0 282.89 428.24 438.46 0.35 27.69 0.18 0.02 28.89 1211.45 sglang 10 100 100 0 234.75 509.23 521.54 0.43 23.03 0.22 0.02 28.89 1195.40 vllm 20 100 100 0 189.23 654.34 669.61 0.53 35.92 0.23 0.03 28.89 1238.22 sglang 20 100 100 0 159.30 755.89 774.02 0.63 30.05 0.26 0.02 28.89 1204.13 vllm 30 100 100 0 145.56 843.25 863.10 0.69 38.70 0.25 0.03 28.89 1227.45 sglang 30 100 100 0 133.24 926.01 947.69 0.75 35.78 0.26 0.03 28.89 1233.78 vllm 40 100 100 0 132.34 924.52 946.35 0.76 45.43 0.29 0.04 28.89 1223.48 sglang 40 100 100 0 122.12 1002.87 1026.52 0.82 41.82 0.41 0.03 28.89 1224.73 vllm 50 100 100 0 133.63 917.30 938.92 0.75 55.64 0.33 0.05 28.89 1225.82 sglang 50 100 100 0 119.47 1014.74 1038.92 0.84 50.43 0.29 0.04 28.89 1212.29
压测结果可视化
-
每秒输出tokens对比
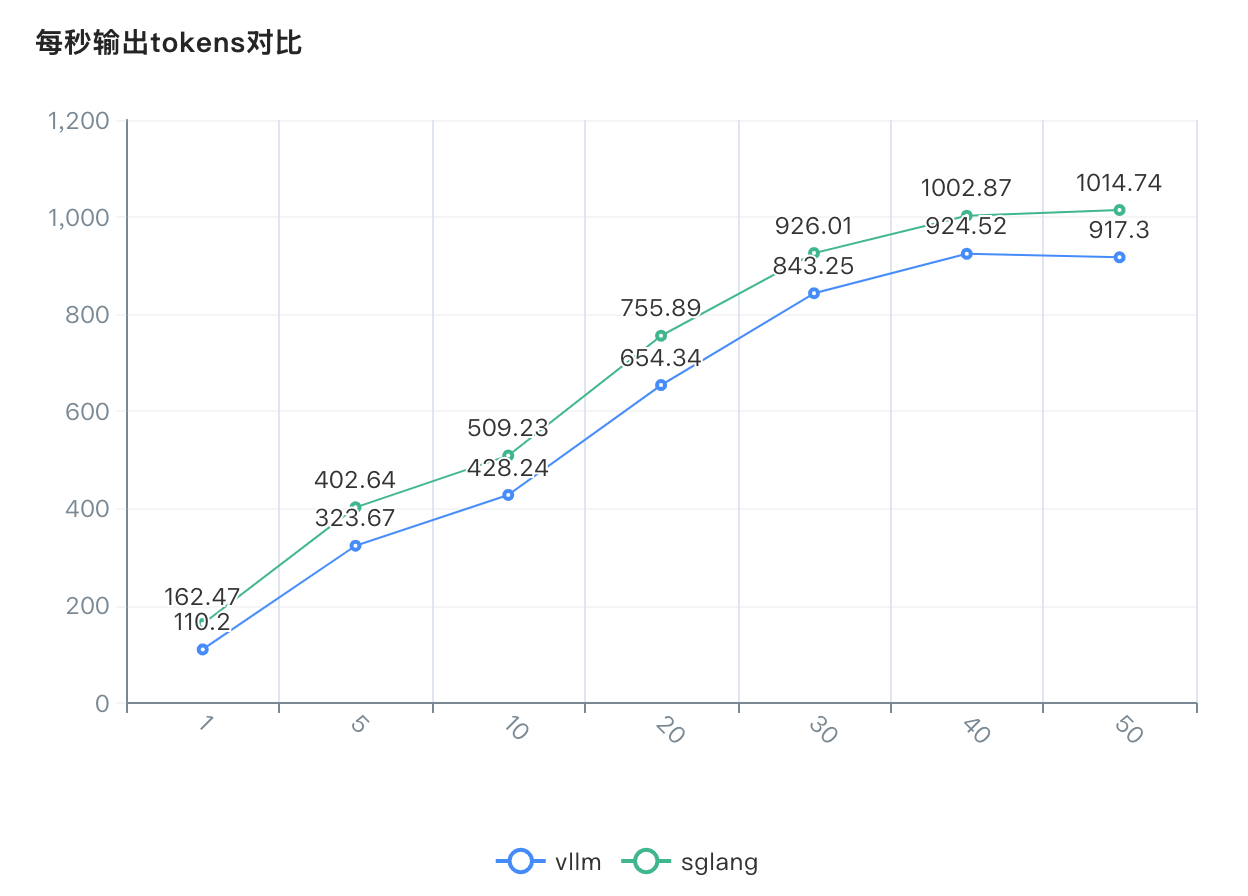
-
QPS对比
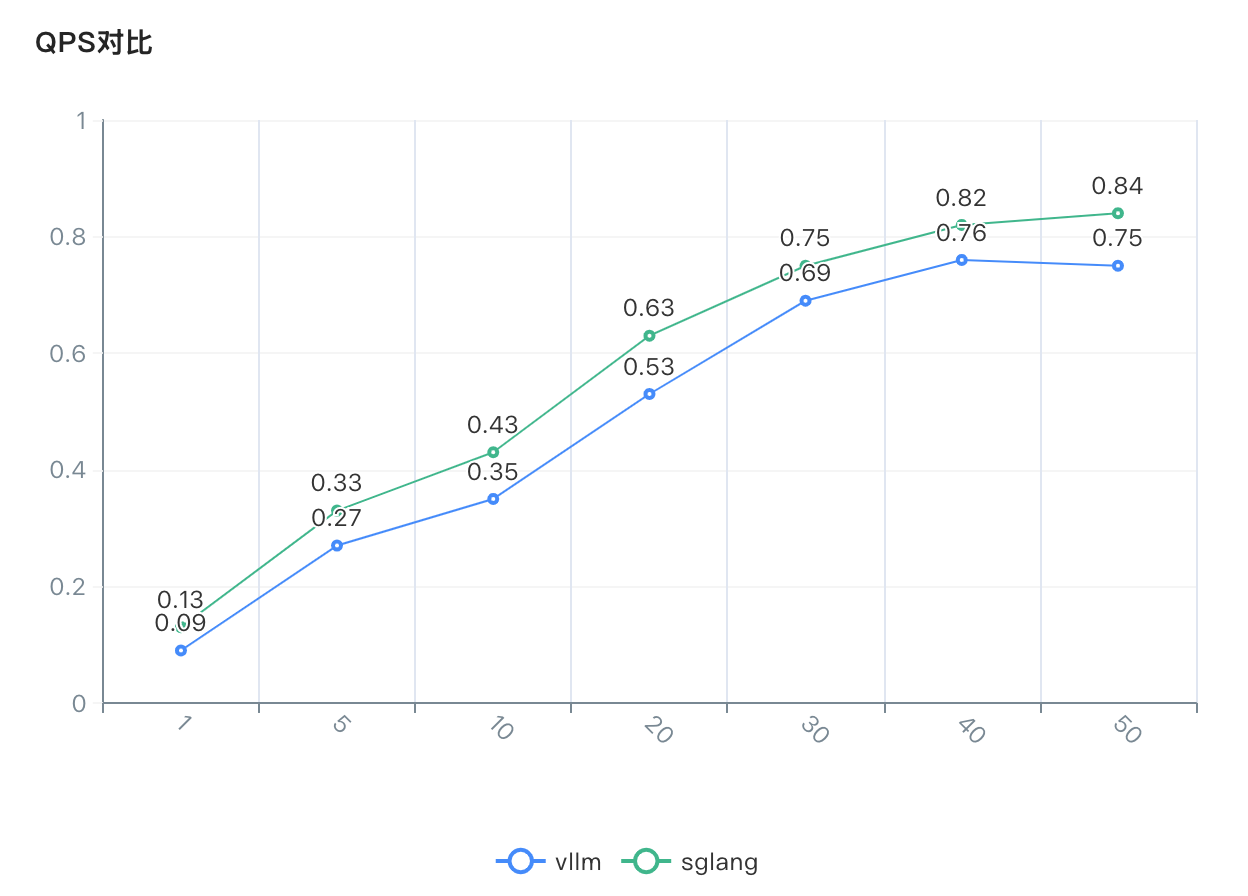
-
平均用时对比
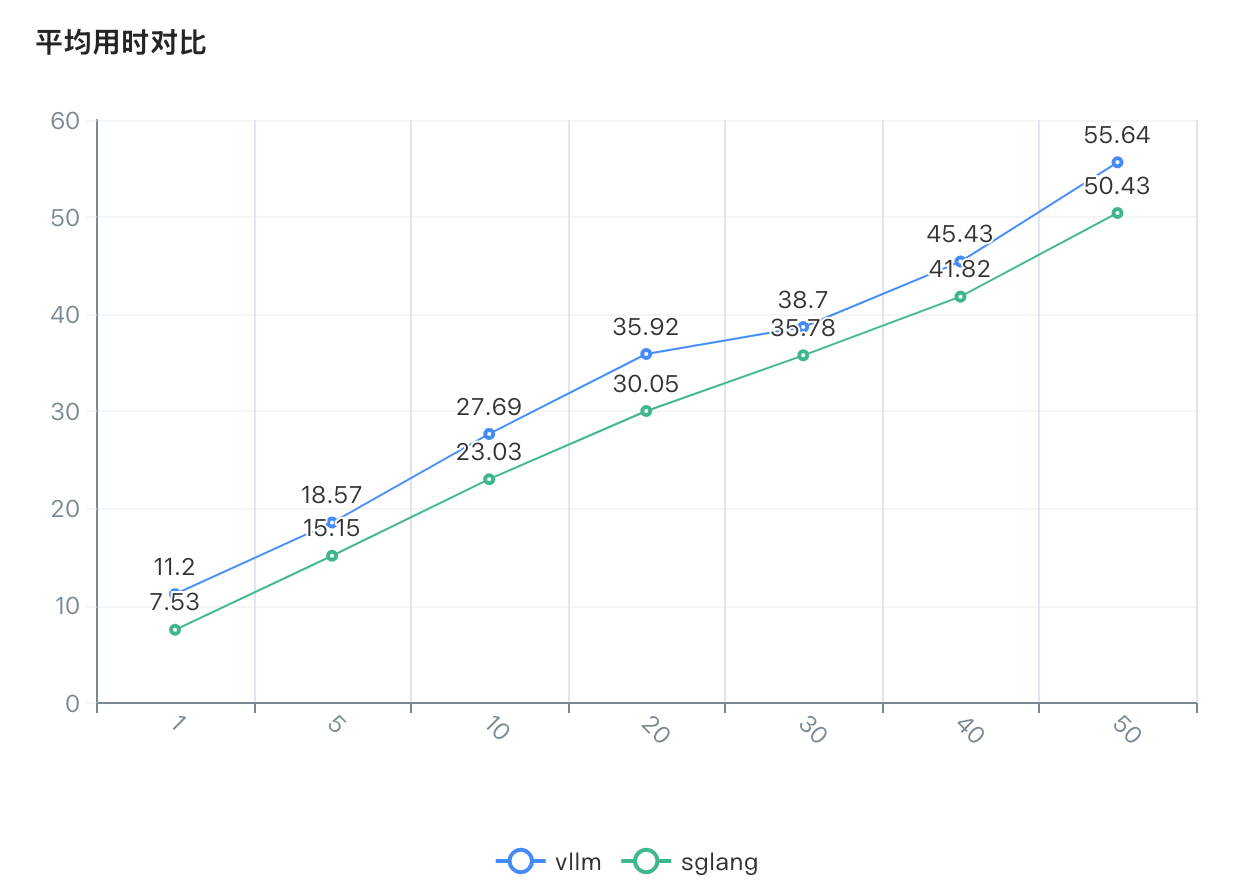
-
首帧用时对比
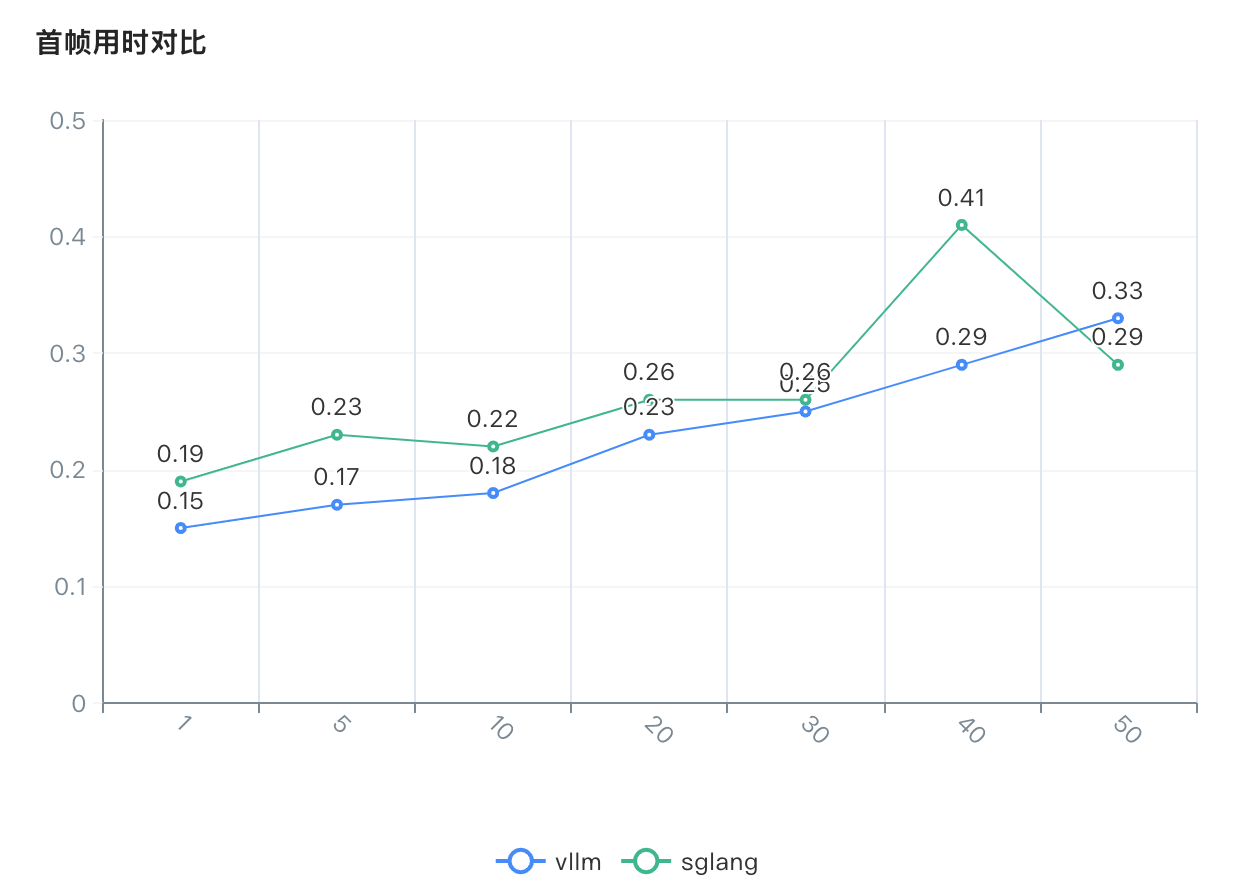
压测结果分析
-
针对vllm和sglang两种推理引擎在不同并发数下的性能进行了分析。
-
吞吐量分析(每秒输出tokens)
vllm:随着并发数从1增加到30,每秒输出tokens从110.20提升到843.25,提升了约7.7倍。当并发数达到40时,性能达到峰值924.52。当并发数增加到50时,性能略有下降至917.30。
sglang:随着并发数从1增加到50,每秒输出tokens持续增长,从162.47提升到1014.74,提升了约6.2倍。在所有并发数下,sglang的吞吐量均高于vllm。
-
响应时间分析
平均用时:两种引擎的平均用时都随着并发数增加而增加,但sglang在各个并发数下的平均用时均低于vllm。
平均首帧用时:两种引擎的首帧用时差异不大,但随着并发数增加,首帧用时也有所增加。
-
性能提升百分比
sglang相对于vllm的性能提升:
并发数 每秒输出tokens提升 平均用时改善 1 47.4% 32.8% 5 24.4% 18.4% 10 18.9% 16.8% 20 15.5% 16.3% 30 9.8% 7.5% 40 8.5% 7.9% 50 10.6% 9.4% -
稳定性分析
从数据来看,两种引擎在所有测试的并发数下(1-50)都保持了100%的成功率,没有失败请求。但从性能曲线来看:
vllm:在并发数为40时达到性能峰值(每秒输出tokens为924.52)当并发数增加到50时,性能略有下降(每秒输出tokens为917.30,下降约0.8%)平均用时从40并发的45.43秒增加到50并发的55.64秒,增加了22.5%
sglang:在测试范围内(1-50并发),性能一直呈上升趋势,50并发时每秒输出tokens达到1014.74,比40并发时的1002.87略有提升(约1.2%),平均用时从40并发的41.82秒增加到50并发的50.43秒,增加了20.6%
-
结论
- 在4卡3090下,vllm和sglang
-
性能对比:在所有测试的并发数下,sglang的性能均优于vllm,无论是吞吐量还是响应时间。
-
稳定支持的并发数:
vllm:可以稳定支持40并发,此时性能达到峰值,超过此并发数性能开始下降。
sglang:在测试范围内(1-50并发)都表现稳定,且性能仍有上升趋势,可以稳定支持50并发。若需确定其极限,可以进行更高并发数的测试。
-
选择建议:
如果追求更高的吞吐量和更低的响应时间,sglang是更好的选择。
如果系统需要支持40以上的并发,sglang的优势更为明显。
两种引擎在低并发数(如1-10)下的性能差异更大,如果主要在低并发场景使用,sglang的优势更为突出。
-
总体而言,sglang在各项指标上均优于vllm,特别是在高并发场景下表现更为稳定,是部署Qwen3-30B-A3B模型的更佳选择。

















 5189
5189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









