






0. 简介
protobuf也叫protocol buffer是google 的一种数据交换的格式,它独立于语言,独立于平台。google 提供了多种语言的实现:java、c#、c++、go 和 python,每一种实现都包含了相应语言的编译器以及库文件。
由于它是一种二进制的格式,比使用 xml 、json进行数据交换快许多。可以把它用于分布式应用之间的数据通信或者异构环境下的数据交换。作为一种效率和兼容性都很优秀的二进制数据传输格式,可以用于诸如网络传输、配置文件、数据存储等诸多领域。
更多详情请看:https://developers.google.com/protocol-buffers/docs/overview
1. 基础语法
1 字段限制
required: 必须赋值的字符optional: 可有可无的字段,可以使用[default = xxx]配置默认值repeated: 可重复变长字段,类似数组
2 tag
每个字段都有独一无二的tag
tag 1-15是字节编码,16-2047使用2字节编码,所以1-15给频繁使用的字段
3 类型
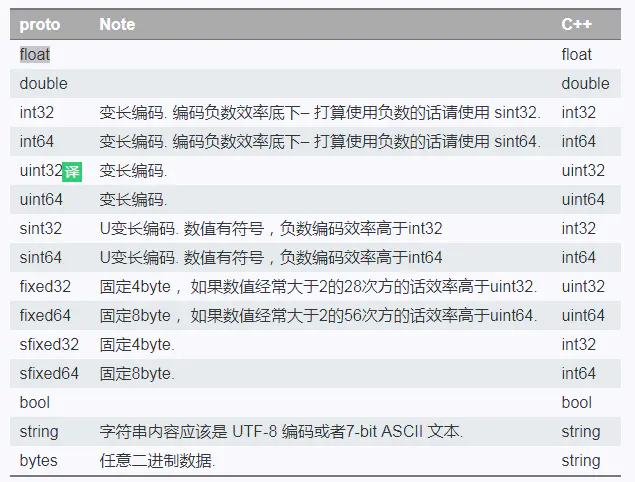
系统默认值:
string默认为空字符串;
bool默认为false;
数值默认为0;
enum默认为第一个元素
4 解析与序列化
每个message都包含如下方法,用于解析和序列化,注意目标是字节形式,非文本。bool SerializeToString(string* output) const: 将message序列化成二进制保存在output中,注意保存的是二进制,不是文本;仅仅是string作为容器。bool ParseFromString(const string& data): 从给定的二进制数值中解析成messagebool SerializeToOstream(ostream* output) const: 序列化到ostream中bool ParseFromIstream(istream* input): 从istream中解析出message
3. 讲解举例
建立.proto文件
syntax = "proto3";//指定版本信息,不指定会报错message Person //message为关键字,作用为定义一种消息类型{ string name = 1; //姓名 int32 id = 2; //id string email = 3; //邮件}message AddressBook{ repeated Person people = 1;}字段API
一般我们会经常使用protoc来自动生成:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto其中protoc工具地址:protoc
而对于字段修饰符为repeated的字段生成的函数,则稍微有一些不同,如people字段,则编译器会为其产生如下的代码:
int people_size() const;void clear_people();const ::Person& people(int index) const;::Person* mutable_people(int index);::Person* add_people();::google::protobuf::RepeatedPtrField< ::Person >* mutable_people();const ::google::protobuf::RepeatedPtrField< ::Person >& people() const;测试程序
void set_addressbook(){ AddressBook obj; Person *p1 = obj.add_people(); //新增加一个Person p1->set_name("mike"); p1->set_id(1); p1->set_email("mike@qq.com"); Person *p2 = obj.add_people(); //新增加一个Person p2->set_name("jiang"); p2->set_id(2); p2->set_email("jiang@qq.com"); Person *p3 = obj.add_people(); //新增加一个Person p3->set_name("abc"); p3->set_id(3); p3->set_email("abc@qq.com"); fstream output("pb.xxx", ios::out | ios::trunc | ios::binary); bool flag = obj.SerializeToOstream(&output);//序列化 if (!flag) { cerr << "Failed to write file." << endl; return; } output.close();//关闭文件}void get_addressbook(){ AddressBook obj; fstream input("./pb.xxx", ios::in | ios::binary); obj.ParseFromIstream(&input); //反序列化 input.close(); //关闭文件 for (int i = 0; i < obj.people_size(); i++) { const Person& person = obj.people(i);//取第i个people cout << "第" << i + 1 << "个信息\n"; cout << "name = " << person.name() << endl; cout << "id = " << person.id() << endl; cout << "email = " << person.email() << endl << endl; }}运行结果:
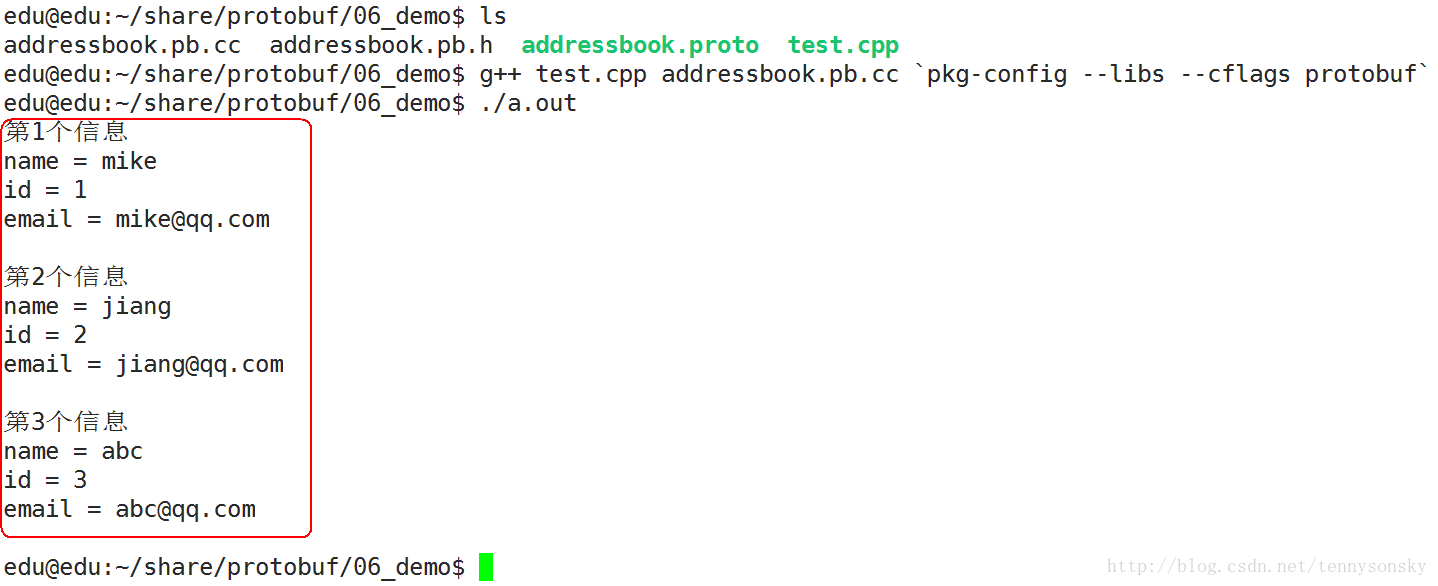















 2711
2711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









