






0.简介
ALOHA算得上是今年年初很惊艳的具身项目了,其项目网站: Mobile ALOHA 。而ACT模仿学习算法能够有效处理复合误差,通过动作分块和时间集成减少任务的有效范围,缓解模仿学习中的复合误差问题,提高了在精细操作任务中的性能。将策略训练为条件变分自编码器(CVAE),能够更好地对有噪声的人类演示数据进行建模,准确预测动作序列。实验证明在多个模拟和真实世界的精细操作任务中显著优于之前的模仿学习算法。我们主要的代码可以在GitHub - tonyzhaozh/act或者GitHub - MarkFzp/act-plus-plus: Imitation learning algorithms with Co-training for Mobile ALOHA: ACT, Diffusion Policy, VINN看到并学习。
1. ACT原理
ACT作为斯坦福最新的Mobile ALOHA系统的最核心的算法:Action Chunking with Transformer。它为啥效果这么好,其实主要的就是Transformer生成式算法,在ACT中主要使用的是CVAE,下面我们就AE(自动编码器)、VAE(变分自动编码器)、CVAE(条件变分自编码器)来进行介绍,这些都是比较老的方法了,但是思想可以借鉴
1.1 AE(自动编码器)
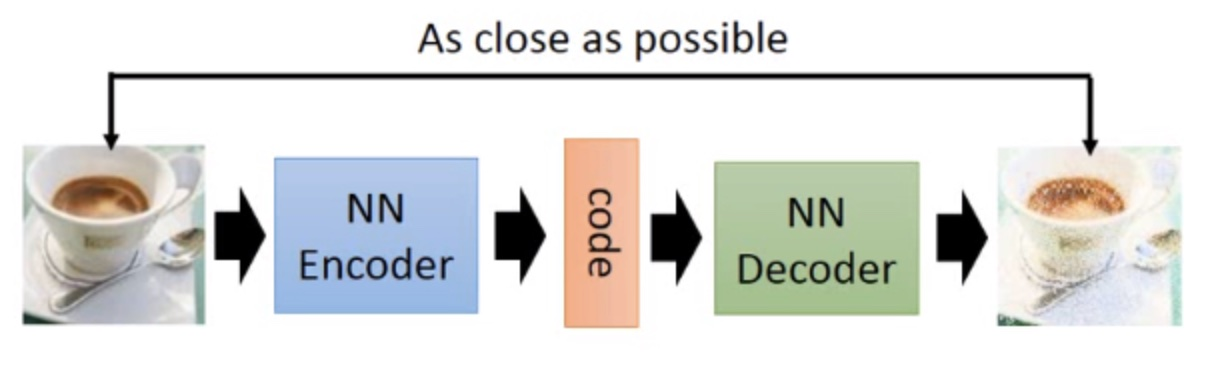
如上图所示,自动编码器主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器和解码器可以看作是两个函数,一个用于将高维输入(如图片)映射为低维编码(code),另一个用于将低维编码(code)映射为高维输出(如生成的图片)。这两个函数可以是任意形式,但在深度学习中,我们用神经网络去学习这两个函数。
由上面介绍可以看出,AE的Encoder是将图片映射成“数值编码”,Decoder是将“数值编码”映射成图片。这样存在的问题是,在训练过程中,随着不断降低输入图片与输出图片之间的误差,模型会过拟合,泛化性能不好。也就是说对于一个训练好的AE,输入某个图片,就只会将其编码为某个确定的code,输入某个确定的code就只会输出某个确定的图片
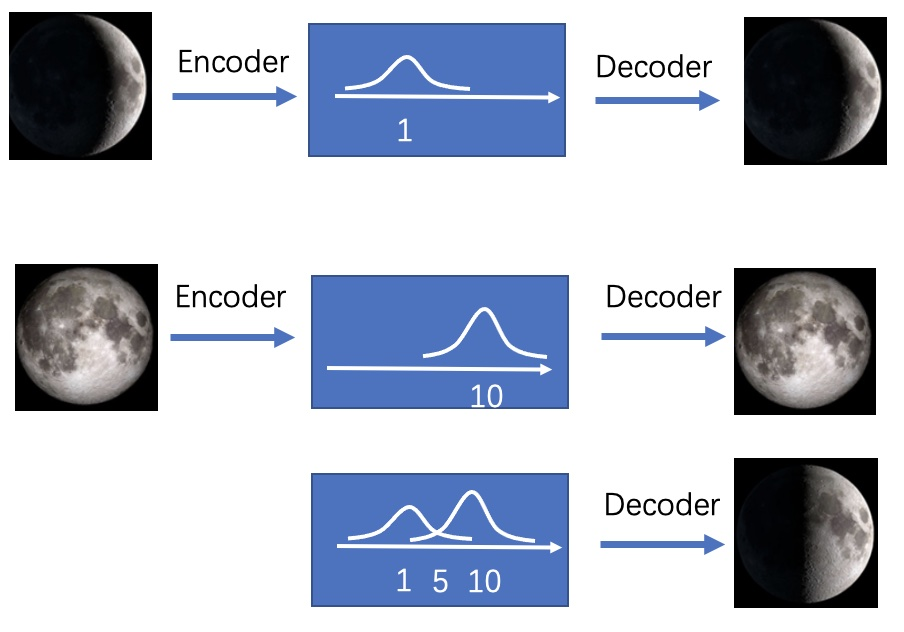
这时候我们转变思路,不将图片映射成“数值编码”,而将其映射成“分布”。这就是VAE的思想。
1.2 VAE(变分自动编码器)
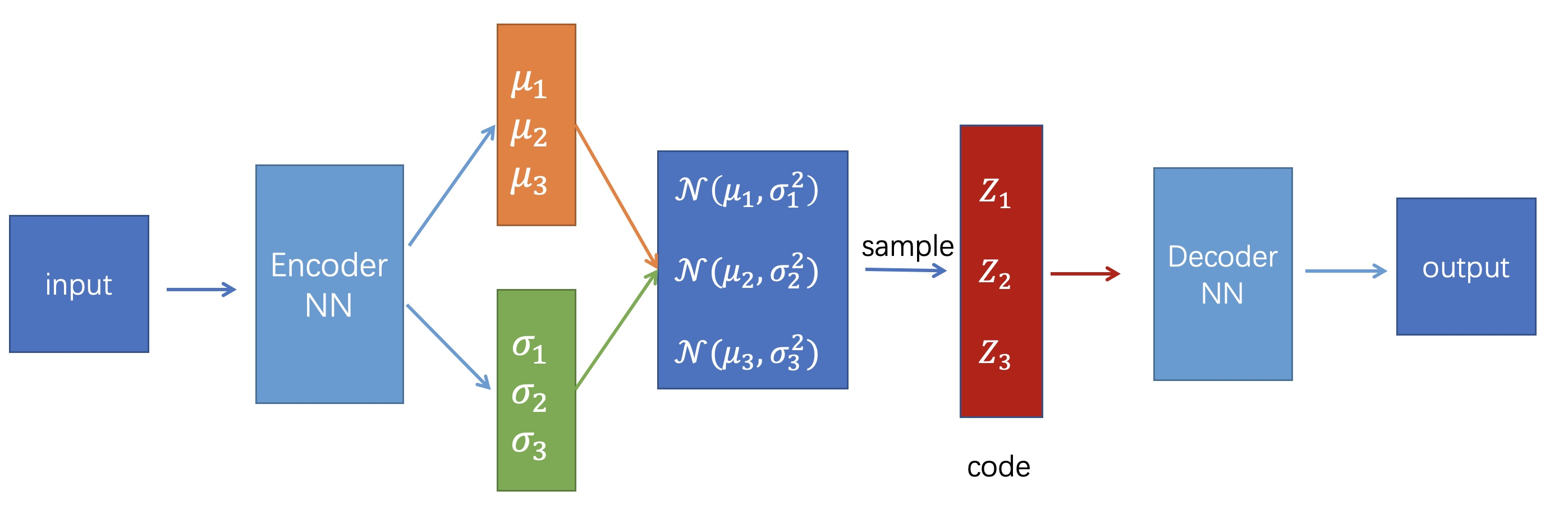
vae和常规自编码器不同的地方在于它的encoder的output不是一个latent vector让decoder去做decode,而是从某个连续的分布里(常见的是高斯分布)采样得到一个随机数or随机向量,然后decode再去针对这个scaler做解码。
常规的自动编码器的任务中没有任何东西被训练来强制获得这样的规律(但是vae就会假设latent vector服从高斯分布):自动编码器被训练成以尽可能少的损失进行编码和解码,压根就不care latent vector服从什么分布。那么自然,我们是不可能使用一个预定义的随机分布产生随机的input然后又期望decoder能够decode出有意义的东西的.

既然我们不知道latent vector服从什么分布,我们就直接人为对其进行约束满足某种预定义的分布,这个预定义的分布和我们产生随机数的分布保持一致,不就完美解决问题了吗?
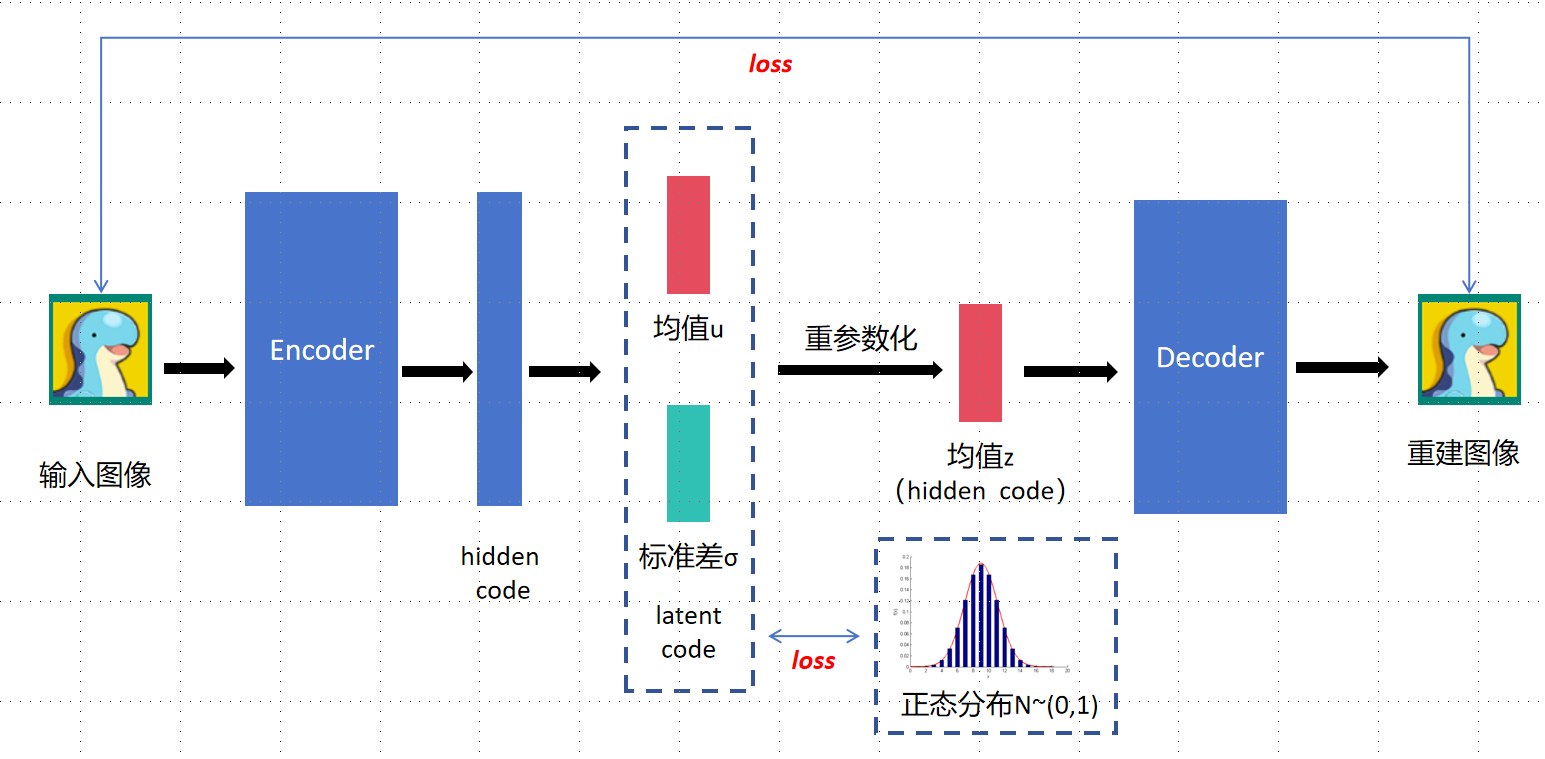
整体架构,就是输入图像会解析成均值和标准差两个部分,然后通过正态分布来重参数化获得均值Z,VAE计算以下两方面之间的损失:
-
重构损失(Reconstruction Loss):这一部分的损失计算的是输入数据与重构数据之间的差异。(输入和输出贴近)
-
KL散度(Kullback-Leibler Divergence Loss):这一部分的损失衡量的是学习到的潜在表示的分布与先验分布(通常假设为标准正态分布)之间的差异。KL散度是一种衡量两个概率分布相似度的指标,VAE通过最小化KL散度来确保学习到的潜在表示的分布尽可能接近先验分布。这有助于模型生成性能的提升,因为它约束了潜在空间的结构,使其更加规整,便于采样和推断。(符合正态分布,来提供随机性)
对于VAE来说,为什么使用重参数化?具体来说,在不使用重参数化的情况下,模型会直接从参数化的分布(例如,正态分布,由均值 μ 和方差 σ2 参数化)中采样,这使得梯度无法回传。
重参数化技巧通过引入一个不依赖于模型参数的外部噪声源(通常是标准正态分布中抽取的),并对这个噪声与模型的均值和方差进行变换,来生成符合目标分布的样本。这样,模型的随机输出就可以表示为模型参数的确定性函数和一个随机噪声的组合。便可以完成梯度回传。详细可以看看这篇文章《【扩散模型基础知识】Diffusion Model中的重参数化和VAE中的重参数化的区别》

代码中的 eps.mul(std).add_(mu) 实现了上述公式的计算,即首先将随机噪声 ϵ 与标准差 σ 相乘,然后将结果加上均值 μ。这样,得到的 z 既包含了模型学习到的分布的特征(通过 μ 和 σ),同时也引入了必要的随机性(通过 ϵ),允许模型通过采样生成多样化的数据。
# VAE class definition
# Encode the input --> reparameterize --> decode
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def reparameterize(self, mu, logvar):
# Reparameterization trick to sample from the distribution represented by the mean and log variance
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu)
def forward(self, x):
mu, logvar = self.encoder(x.view(-1, input_dim))
z = self.reparameterize(mu, logvar)
return self.decoder(z), mu, logvar
1.3 CVAE(条件变分自编码器)
点击ACT----斯坦福具身智能入门梳理查看全文。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









