






1. 前言
在机器人操作任务中,抓取是一项核心技能。无论是工业机器人、服务机器人还是医疗辅助机器人,可靠的抓取能力都至关重要。传统的抓取方法主要基于力控制、轨迹规划、启发式算法等,但这些方法通常需要高精度建模,泛化能力较差,难以适应复杂的环境变化。
近年来,强化学习(Reinforcement Learning, RL)在机器人控制领域取得了突破,DeepMimic 作为一种结合模仿学习(Imitation Learning, IL)*和*强化学习(RL)*的方法,被广泛应用于机器人运动控制。本研究基于 DeepMimic 训练机器人手爪的*最佳抓取策略,使其能够自适应学习最优抓取方式,并在现实环境中有效泛化。
2. 原理介绍
2.1 强化学习基础
强化学习的目标是找到最优策略,使得累积奖励最大化。强化学习任务通常由如下四元组表示:
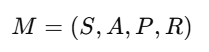
其中:
-
S 是状态空间,如机器人的关节角度、目标位置等。
-
A 是动作空间,如手爪的开合、旋转等控制信号。
-
P(s′∣s,a) 是状态转移概率,表示执行动作后进入下一个状态的概率分布。
-
R(s,a) 是奖励函数,衡量当前动作的优劣。
强化学习的目标是学习一个策略 π(a∣s),使得累积折扣奖励最大:
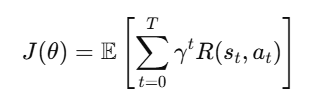
其中,γ 是折扣因子(通常取 0.9∼0.99),用于平衡短期和长期收益。
2.2 DeepMimic 介绍
DeepMimic 结合了强化学习和模仿学习,优化目标如下:
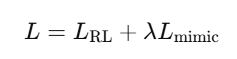
其中:
-
LRL 是标准强化学习损失,负责优化策略。
-
Lmimic 是模仿损失,引导机器人学习专家轨迹。
-
λ 控制两者的平衡。
核心思想:
-
先通过专家演示获取轨迹数据(如人类抓取示范)。
-
通过模仿损失约束机器人执行类似轨迹。
-
采用强化学习优化策略,使其适应不同环境。
2.3 奖励函数设计
为了优化抓取策略,我们定义了多目标奖励函数:
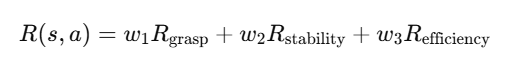
-
抓取成功奖励 Rgrasp:如果目标物体被成功抓住,奖励 +10。
-
抓取稳定性 Rstability:物体未掉落则奖励 +5,否则惩罚 -5。
-
效率奖励 Refficiency:如果机器人在 N 步内完成抓取,奖励与步数成反比:
-
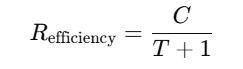
-
其中 C 是奖励系数,T 是步数。
这种设计能够鼓励机器人快速、稳定地完成抓取。
3. 部署环境介绍
本实验使用的软硬件环境如下:
-
系统:Ubuntu 20.04
-
仿真环境:MuJoCo 2.1
-
强化学习框架:Stable-Baselines3(PPO 算法)
-
编程语言:Python 3.8
-
硬件:NVIDIA RTX 3090 + 32GB RAM


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









