






0. 简介
对于具身智能来说,目前算是一个集大成的工作,虽然目前仍然处于持续发展的阶段,但是有一些比较基础的知识还是需要系统整理的。目前具身智能发展的非常快,几天就能看到一个让人眼前一亮的工作。
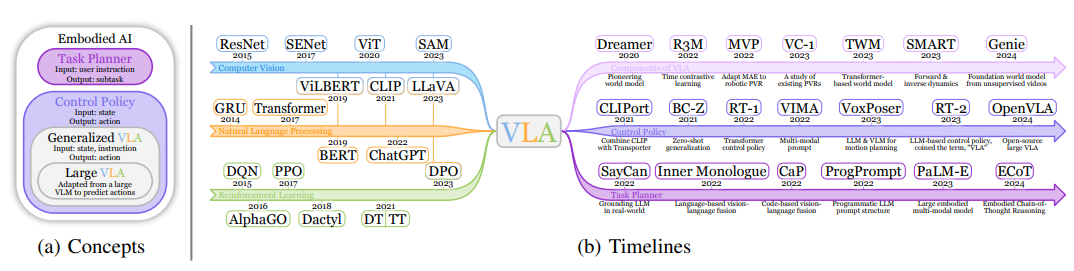
1. 视觉-语言-动作模型分类
1.1 非Transformer语言指令控制策略
在采用 Transformer 模型之前,早期的语言条件机器人任务控制策略在架构上差异显著。
- CLIPort 集成了 CLIP 的视觉和语言编码器与 Transporter 网络 ,创建了一个双流架构。在一个流中,CLIP 的视觉编码器从 RGB 图像中提取“语义”信息,而在另一个流中,Transporter 网络从 RGB-D 图像中提取“空间”信息。CLIP 句子编码器对语言指令进行编码并指导输出动作,这是一对末端效应器的姿态:拾取和放置姿态。CLIPort 展示了根据语言指令拾取和放置物体的能力。
- BC-Z [113] 处理两种类型的任务指令:语言指令或人类演示视频。环境以 RGB 图像的形式呈现给模型,然后通过 FiLM 层将指令嵌入和图像嵌入结合,最终生成动作。这种条件策略被认为在未见过的任务上展现了零样本任务泛化能力。
- MCIL [95] 是一种开创性的机器人策略,它集成了自由形式自然语言条件,与早期通常依赖于任务 ID 或目标图像的条件方法形成对比。MCIL 引入了利用无标签和非结构化演示数据的能力。通过训练策略跟随图像或语言目标,其中小部分训练数据集由配对的图像和语言目标组成。
- HULC [96] 引入了多种旨在增强机器人学习架构的技术,包括机器人的分层学习、一个多模态变换器和离散潜在计划。该变换器学习高层行为,将低层局部策略和全局计划进行分层划分。此外,HULC 还结合了一种基于对比学习的视听语义对齐损失,以对齐 VL 模态。HULC++ [97] 进一步整合了自监督可用性模型,该模型引导 HULC 到由语言指令指定的可操作区域,使其能够在此指定区域内完成任务。
- UniPi [128] 将决策问题视为文本条件的视频生成问题。为了预测动作,UniPi 根据给定的文本指令生成视频,并通过逆动力学从视频帧中提取动作。这种创新的政策作为视频的表述提供了几个优势,包括跨不同机器人任务的增强泛化能力以及从互联网视频到真实机器人的知识转移潜力。
1.2 基于Transformer的控制策略
自从引入 Transformers 后,控制策略趋向于类似的基于 Transformer 的架构。
- Interactive Language [100] 提出了一个机器人系统,其中低级控制策略可以实时受到通过语言传达的人类指令的指导,从而实现长期重排任务的完成。这种基于语言的指导的有效性主要归因于利用了一个精心收集的数据集,该数据集包含多样的语言指令,其规模超越了以前的数据集一个数量级。
- Hiveformer [101] 强调利用多视角场景观察和保持完整观察历史来支持语言条件策略。这种方法代表了相较于仅使用当前观察的 CLIPort 和 BC-Z 等先前系统的进步。值得注意的是,Hiveformer 是最早采用 Transformer 架构作为其策略骨干之一。
- Gato [36] 提出了一种模型,可以玩 Atari 游戏、描述图像和堆叠积木,所有这些都使用一组模型参数。这一成就得益于统一的标记方案,使输入和输出在不同任务和领域之间协调一致。因此,Gato 实现了不同任务的同时训练。作为一个重要的里程碑,Gato 体现了构建“多模态、多任务、多具身通用代理”的潜力。
- RoboCat [109] 提出了一个自我改进过程,旨在使代理能够快速适应新任务,仅需 100 个演示。这个自我改进过程迭代地微调模型,并使用微调后的模型自生成新数据。建立在 Gato 模型之上,RoboCat 融入了 VQ-GAN 图像编码器 [110]。在训练过程中,RoboCat 不仅预测下一个动作,还预测未来的观察。自我改进过程的有效性通过在多任务、多具身设置下进行的全面实验得到了验证。
- RT-1 [114] 由与 BC-Z 相同的团队开发,具有与 BC-Z 的相似性,但引入了一些关键区别。特别是,RT-1 使用基于更高效的 EfficientNet [115] 的视觉编码器,脱离了 BC-Z 使用 ResNet 的做法。然而,RT-1 并不使用视频作为任务指令。此外,RT-1 用 Transformer 解码器替换了 BC-Z 中的 MLP 动作解码器,产生离散化的动作。这一修改使 RT-1 能够关注过去的图像,提高了其性能。
- Q-Transformer [117] 扩展了 RT-1,引入了自回归 Q 函数。与通过模仿学习学习专家轨迹的 RT-1 相比,Q-Transformer 采用 Q 学习方法。除了 Q 学习的 TD 误差目标外,还加入了保守正则化器,以确保最大值动作保持在分布内。这种方法允许 Q-Transformer 利用成功的演示和失败的轨迹进行学习。
- RT-Trajectory [118] 采用轨迹草图作为策略条件,而不是依赖语言条件或目标条件。这些轨迹草图由曲线组成,描绘了机器人末端执行器要遵循的预期轨迹。它们可以通过图形用户界面手动指定、从人类演示视频中提取或由基础模型生成。RT-Trajectory 的策略建立在 RT-1 的基础上,经过训练以控制机器人臂准确跟随轨迹草图。这种方法促进了对新对象、任务和技能的泛化,因为来自各种任务的轨迹是可迁移的。
- ACT [119] 构建了一个带有动作分块的条件 VAE 策略,要求策略预测一系列动作而不是单个动作。在推理期间,使用称为时间集成的方法对动作序列进行平均。RoboAgent [120] 通过其 MT-ACT 模型扩展了这一方法,证明动作分块改善了时间一致性。此外,RoboAgent 引入了一种语义增强方法,利用修复技术来增强现有演示。
- RoboFlamingo [121] 通过将基于 LSTM 的策略头附加到 VLM,调整了现有的 VLM Flamingo [32], [149],这表明预训练的 VLM 可以有效地转移到语言条件的机器人操控任务。
1.3 多模态指令的控制策略
多模态指令启用了新的任务指定方式,例如通过演示、命名新对象或用手指指向。
- VIMA [150] 强调多模态提示和模型的泛化能力。通过结合多模态提示,可以制定比传统纯文本提示更具体和复杂的任务。VIMA 引入了四种主要类型的任务:物体操控、视觉目标达到、新概念定位、一键视频模仿、视觉约束满足、视觉推理。这些任务往往难以甚至无法仅用语言提示表达。VIMA-Bench 已经开发出来,用于评估四个泛化水平:放置、组合、新对象、新任务。
- MOO [111] 扩展了 RT-1 以处理多模态提示。利用 RT-1 的骨干,MOO 结合 OWLViT 来编码提示中的图像。通过用新对象和额外提示图像扩展 RT-1 数据集,MOO 增强了 RT-1 的泛化能力。这一扩展也促进了指定目标对象的新方法,例如用手指指向或点击图形用户界面。
1.4 具有 3D 视觉的控制策略
我们生活在一个三维世界中,直观上使用 3D 表示作为视觉输入应该提供比 2D 图像更丰富的信息。点云由于其直接来源于 RGBD 输入而成为表示 3D 输入的热门选择,如 DP3 和 3D Diffuser Actor 所示。然而,体素也在各种工作中进行了探索。RoboUniView [124] 通过一种新颖的 UVFormer 模块将 3D 信息注入 RoboFlamingo,从而显示出改进的性能,该模块作为其视觉编码器,提供来自多视角图像的 3D 占用信息。VER [151] 还提出将多视角图像粗到细地体素化为 3D 单元格,从而提高视觉-语言导航任务的性能。
- PerAct [103] 通过利用 3D 体素表示,在观察和动作空间方面取得了进展。这种方法为动作学习提供了稳健的结构先验,使多视角观察的自然处理成为可能,并促进了 6-DoF 中的数据增强。在该框架中,模型的输入包括从 RGBD 图像重建的体素地图,而输出对应于引导夹爪运动的最佳体素。通过采用这种表述,PerAct 即使在少量演示的情况下也能促进高效的任务学习。
- Act3D [104] 引入了一种连续分辨率的 3D 特征场,根据当前任务的需要进行自适应分辨率,解决了体素化的计算成本。
- RVT, RVT-2 [105], [106] 提出了从场景点云的虚拟视图重新渲染图像,并使用这些图像作为输入,而不是直接依赖 3D 输入。
1.5 基于扩散的控制策略
基于扩散的动作生成利用了扩散模型在计算机视觉领域的成功。
- Diffusion Policy [130] 将机器人策略公式化为 DDPM [131]。该方法结合了多种技术,包括后退地平线控制、视觉条件和时间序列扩散变换器。这种基于扩散的视动政策的有效性突显了其在多模态动作分布、高维动作空间和训练稳定性方面的熟练程度。
- SUDD [133] 提出了一个框架,其中 LLM 指导数据生成,随后将过滤后的数据集蒸馏为视听语言运动政策。该框架通过将 LLM 与一套原始机器人工具(如抓取采样器和运动规划器)组合,实现了基于语言的数据显示生成。然后,它通过结合语言条件用于多任务学习,扩展了 Diffusion Policy,并促进了过滤数据集的蒸馏。
- Octo [134] 引入了一种基于变换器的扩散政策,其特征在于模块化开放框架设计,允许从不同任务定义编码器、观察编码器和动作解码器灵活连接到 Octo 变换器。作为首批利用 Open XEmbodiment 数据集 [143] 的模型之一,Octo 显示出积极的迁移和跨多种机器人及任务的泛化能力。
- MDT [136] 将新近推出的 DiT 模型 [137] 从计算机视觉适应到动作预测头。DiT 最初被提出作为一种基于变换器的扩散模型,替代了经典的 U-Net 架构用于视频生成。结合两个辅助目标——掩蔽生成前瞻和对比潜在对齐——MDT 显示出优于基于 U-Net 的扩散模型 SUDD 的表现。
- RDT-1B [139] 是一个基于扩散的双手操控基础模型,同样建立在 DiT 上。它通过在各种机器人间引入统一的动作格式来解决数据稀缺问题,使其能够在超过 6000 条轨迹的异质多机器人数据集上进行预训练。因此,RDT 的参数规模扩大至 12 亿,并展示出零-shot 泛化能力。
1.6 具有 3D 视觉的基于扩散的控制策略
一些工作提出将 3D 视觉与基于扩散的策略相结合。DP3 [132] 将 3D 输入引入扩散政策,从而提高了性能。同样,3D Diffuser Actor [135] 共享 DP3 的核心思想,但在模型架构上有所不同,将 Act3D 与 Diffusion Policy 结合起来。
1.7 运动规划的控制策略
运动规划涉及将移动任务分解为离散的路径点,同时满足障碍物避免和运动限制等约束。
- Language costs [98] 提出了一种新颖的机器人纠正方法,使用自然语言用于人机协作的机器人控制系统。该方法利用人类指令生成的预测成本图,由运动规划器利用这些成本图计算最佳动作。该框架使用户能够通过直观的语言命令纠正目标、指定偏好或从错误中恢复。
- VoxPoser [125] 利用 LLM 和 VLM 创建两个 3D 体素地图,分别表示可用性和约束。它利用 LLM 的编程能力和 VLM 的感知能力。LLM 将语言指令翻译为可执行代码,调用 VLM 获取对象坐标。基于组合的可用性和约束地图,VoxPoser 采用模型预测控制生成机器人臂末端执行器的可行轨迹。值得注意的是,VoxPoser 不需要任何训练,因为它直接连接 LLM 和 VLM 进行运动规划。
- RoboTAP [152] 将演示分解为阶段,每个阶段由夹爪的打开和关闭标记。在每个阶段,RoboTAP 使用 TAPIR 算法检测活动点,跟踪相关对象从源位置到目标位置的路径。然后可以通过视觉伺服控制机器人。通过将这些阶段串联在一起,创建了一个运动计划,从而实现少量镜头的视觉模仿。
1.8 基于点的动作控制策略
最近的研究探讨了利用 VLM 的能力选择或预测基于点的动作,这是构建完整 VLAs 的一种经济有效的替代方案。
- PIVOT [153] 将机器人任务视为视觉问答,利用 VLM 从一组视觉建议中选择最佳机器人动作。视觉建议以图像上的关键点形式进行注释。VLM 被反复提示以进行细化,直到识别出最佳选项。
- RoboPoint [107] 使用空间可用性预测的任务微调 VLM,即指出在图像上采取行动的位置。这些 2D 图像上的可用性点随后通过深度图投影到 3D 空间中,形成预测的机器人动作。
- ReKep [51] 是一个约束函数,将场景中的 3D 关键点映射到数值成本。机器人操控任务可以表示为 ReKep 约束的序列,这些约束由大型视觉模型和 VLM 生成。因此,可以通过求解约束优化问题获得机器人动作。
1.9 大规模 VLA
大规模 VLA 等同于 RT-2 [2] 提出的原始 VLA 定义,如图 2a 所示。这一术语类似于 LLM 和一般语言模型之间的区分,或者大规模 VLM 和一般 VLM 之间的区分。
点击具身智能操作知识梳理与拓展查看全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









