






贝叶斯方法是一套基于与独立的每对特征之间的“天真”假设应用贝叶斯定理监督学习算法。给定类变量和和从属特征矢量X_1通过x_n,贝叶斯定理状态下列关系:
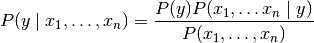
使用独立的天真假设
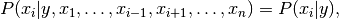
所有一世,这种关系简化为
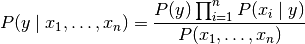
既然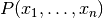
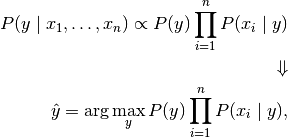
我们可以用最大后验(MAP)估计估计 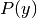
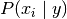
不同的朴素贝叶斯分类的主要区别由它们做出关于分布的假设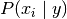
尽管他们显然过于简单的假设,朴素贝叶斯分类器已经在许多现实世界的情况下,著名的文档分类和垃圾邮件过滤相当奏效。它们需要训练数据的少量估算必要的参数。(理论上的原因朴素贝叶斯效果很好,和在其数据类型是的话,请参见下面的参考资料。)
相比于更复杂的方法朴素贝叶斯学习和分类可以非常快。类条件特征的分布的解耦意味着每个分布可以独立地估计为一维分布。这反过来有助于减轻来自维数灾难引起的问题。
在另一面,虽然朴素贝叶斯被称为一个体面的分类,它被称为是一个坏的估计,所以从概率输出 predict_proba不应太认真对待。
1、 高斯朴素贝叶斯
GaussianNB实现了高斯朴素贝叶斯算法进行分类的特征的可能性被假定为高斯:
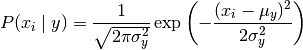
参数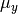
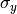
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> from sklearn.naive_bayes import GaussianNB
>>> gnb = GaussianNB()
>>> y_pred = gnb.fit(iris.data, iris.target).predict(iris.data)
>>> print("Number of mislabeled points out of a total %d points : %d"
... % (iris.data.shape[0],(iris.target != y_pred).sum()))
Number of mislabeled points out of a total 150 points : 62、多项朴素贝叶斯
MultinomialNB实现了朴素贝叶斯算法multinomially分布式数据,并且是在文本分类变体使用的两种经典朴素贝叶斯之一(其中,数据通常被表示为字矢量计数,尽管TF-IDF载体也是已知的实践中很好地工作) 。该分布通过矢量参数化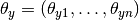
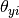
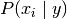
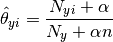
其中,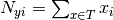
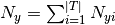
平滑先验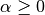
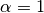
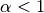















 7905
7905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









