







门控循环单元(GRU)
重置门和更新门
重置门(Reset Gate)和更新门(Update Gate)是循环神经网络(Recurrent Neural Network, RNN)的变体之一,门控循环单元(Gated Recurrent Unit, GRU)中的两个关键概念。GRU被设计用来解决传统RNN在处理长序列数据时的梯度消失问题。这两个“门”的主要功能是控制信息的流动,即决定在序列数据处理中保留多少旧信息(如过去的状态)和接收多少新信息。
重置门(Reset Gate)
重置门负责决定多少过去的信息需要被遗忘。它是一个介于0到1之间的值,通过一个sigmoid激活函数来调节。当重置门接近0时,模型会“忘记”较多的过去信息;而当接近1时,则保留更多的过去信息。这有助于模型在处理序列数据时动态地保留重要的历史信息,同时忘记不重要的信息。
更新门(Update Gate)
更新门则用于控制模型应该多大程度上考虑当前单元的新信息(当前输入)与上一个单元的旧信息(过去的状态)。它同样是一个介于0到1之间的值,并通过sigmoid激活函数得出。更新门帮助模型决定在当前状态下应该保留多少之前的信息和引入多少新的信息,从而使模型在处理不同类型的序列数据时保持灵活性。
重置门和更新门的结合使得GRU在处理例如时间序列数据、自然语言处理等需要记忆长期依赖关系的任务时更加有效和强大。通过这两个门的协调工作,GRU能够更好地捕捉序列数据中的时间动态特征,并减轻梯度消失的问题。
门控循环单元具有下面两个显著特征:
重置门有助于捕获序列中的短期依赖关系。
更新门有助于捕获序列中的长期依赖关系。
门控循环单元代码:
这段代码是一个门控循环单元(GRU)的实现,用于处理序列数据。GRU是一种特殊类型的循环神经网络(RNN),用于处理例如时间序列数据或自然语言等序列化信息。以下是这段代码的逐行解读:
函数定义:
def gru(inputs, state, params):
这定义了一个名为 gru 的函数,接收三个参数:inputs(输入数据序列),state(初始状态),params(GRU层的参数)。
参数解包:
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
这行代码将 params 中的参数解包到GRU的各个权重和偏置中。这些包括更新门(z)的权重和偏置 (W_xz, W_hz, b_z),重置门(r)的权重和偏置 (W_xr, W_hr, b_r),以及候选隐藏状态(h)的权重和偏置 (W_xh, W_hh, b_h)。
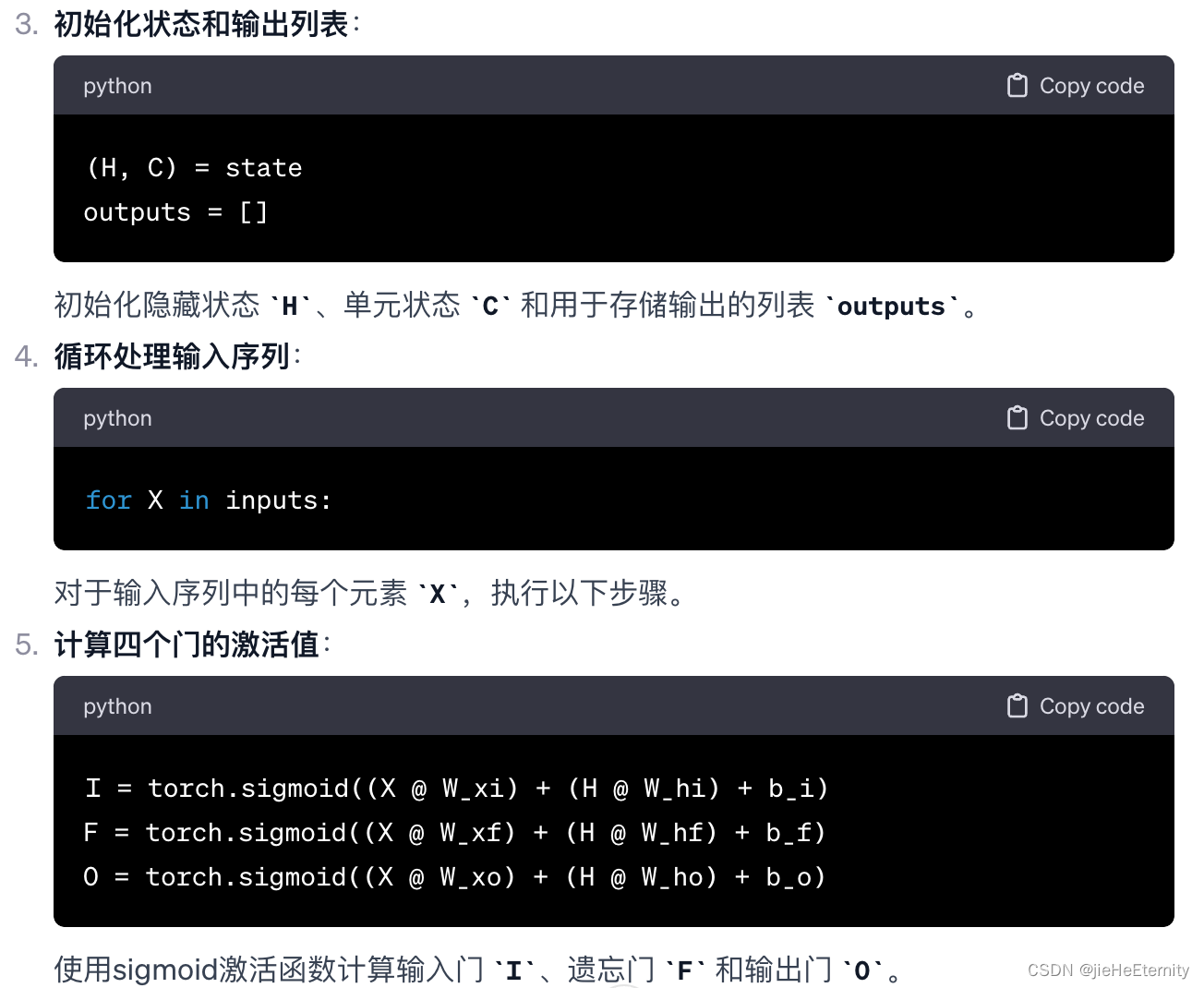
初始化隐藏状态和输出列表:
H, = state
outputs = []
这里初始化了隐藏状态 H 和用于存储输出的列表 outputs。
循环处理输入序列:
for X in inputs:
对于输入序列中的每个元素 X,执行以下步骤。
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
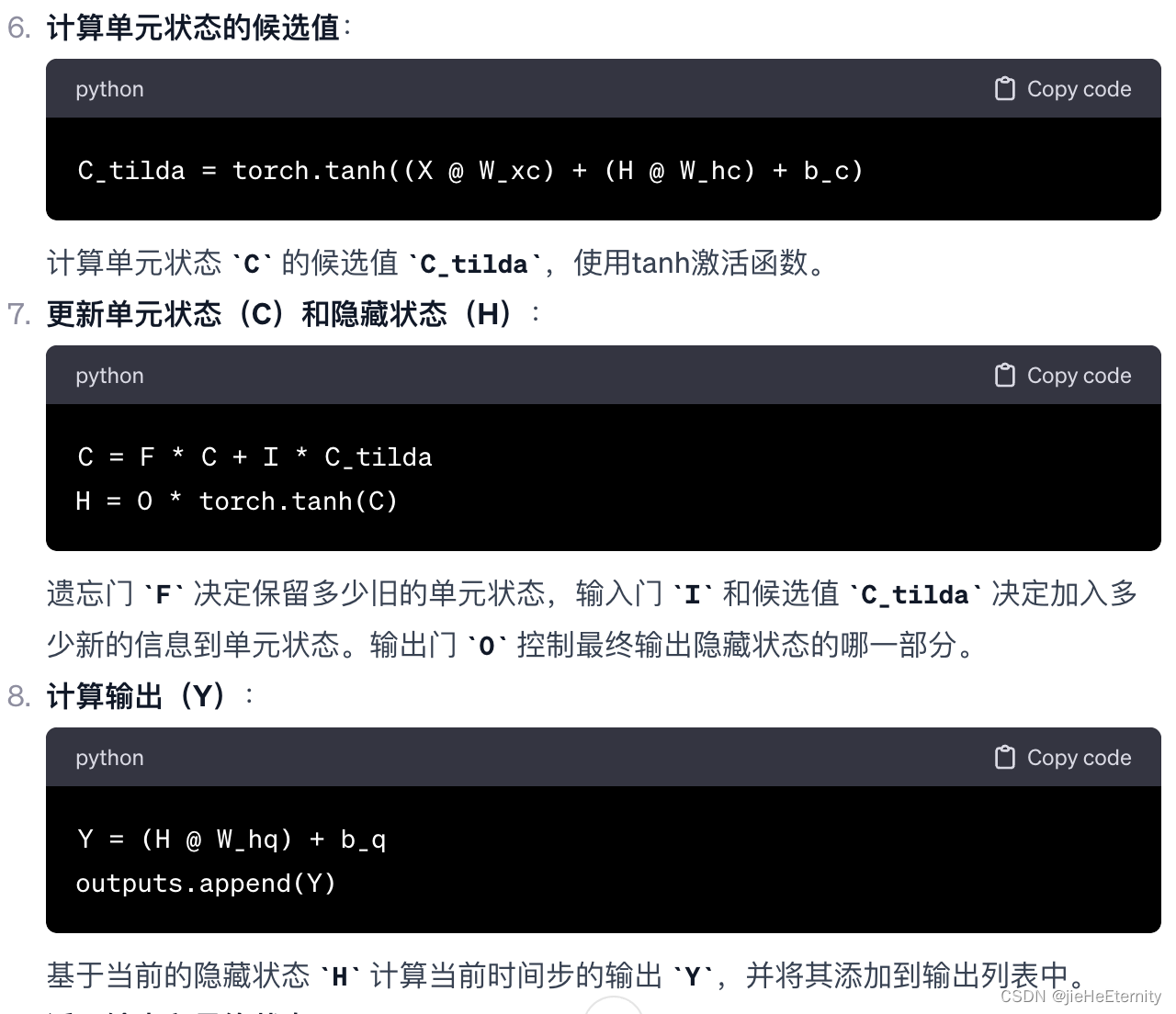
计算候选隐藏状态(H~)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
计算候选隐藏状态 H_tilda,使用tanh激活函数。
更新隐藏状态(H):
H = Z * H + (1 - Z) * H_tilda
使用更新门 Z 来融合旧的隐藏状态 H 和新的候选隐藏状态 H_tilda。
计算输出(Y):
Y = H @ W_hq + b_q
outputs.append(Y)
基于当前的隐藏状态 H 计算当前时间步的输出 Y,并将其添加到输出列表中。
长短期记忆网络(LSTM)
long short-term memory
长短期记忆网络设计的灵感来自于计算机的逻辑门。
长短期记忆中中引入了记忆元,为了控制记忆元,我们需要许多门:输入门,忘记门,输出门。

对上面代码的解读


在上面这段代码中,变量H和C分别表示隐状态和记忆元。

小结
长短期记忆网络有三种类型的门:输入门,遗忘门,和输出门。
长短期记忆网络的隐藏层输出包括“隐状态“和“记忆元“。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
长短期记忆网络可以缓解梯度消失和梯度爆炸。
深度循环神经网络
简介实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size,num_steps = 32 , 35
train_iter , vocab = d2l.load_data_time_machine(batch_size,num_steps)
vocab_size , num_hiddens , num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inpyts, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer,len(vocab))
model = model.to(device)
小结
在深度循环神经网络中,隐状态的信息被传递到当前层的下一时间步和下一层的当前时间步。
有许多不同风格的深度循环神经网络,如长短期记忆网络,门控循环单元,或经典循环神经网络。这些模型在深度学习框架的高级api中都有涵盖。
双向循环神经网络
双向循环神经网络(Bidirectional Recurrent Neural Network, BiRNN)是循环神经网络(RNN)的一种变体,它的核心思想是在处理序列数据时,网络不仅从前到后(正向)处理信息,同时也从后到前(反向)处理信息。这种结构使得双向RNN能够在每个时间点上同时获得过去和未来的信息。
基本概念
双向处理:在双向RNN中,序列数据被两个独立的RNN同时处理。一个RNN沿着时间正向传播,另一个沿着时间反向传播。
信息合并:每个时间点上,两个方向的RNN的输出被结合起来,以便于捕捉序列中的前后依赖关系。
工作原理
在每个时间步,正向RNN处理当前元素及之前的历史信息,而反向RNN处理当前元素及之后的未来信息。
然后,这两个方向的信息被结合起来,形成该时间步的最终输出。
优点
更丰富的信息:由于能够同时考虑到序列中的前文和后文信息,双向RNN在很多任务中比单向RNN表现得更好。
适用于各类序列数据:特别适合于需要同时考虑上下文信息的任务,如文本分类、语言建模、语音识别等。
挑战
计算成本更高:双向RNN需要更多的计算资源,因为它实际上是同时训练两个RNN。
训练数据要求:双向RNN在计算每个时间步的输出时需要整个序列的信息,这意味着它不能像单向RNN那样适用于实时或在线处理任务。
双向循环神经网络不适合做推理,适合对句子做特征提取。
隐马尔可夫模型中的动态规划
在马尔可夫模型中引入动态规划主要是让模型避免对所有可能状态的穷举搜索,使得计算变得可行和高效。
双向循环神经网络利用过去的信息和未来的信息来预测当前的信息。
小结
- 双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
- 双向循环神经网络与概率图模型中的“前向-后向“算法具有相似性。
- 双向循环神经网络重要用于序列编码和给定双向上下文的观测预计。
- 由于梯度链更长,因此双向循环神经网络的训练代价很高。
机器翻译与数据集
在机器翻译中,一般使用单词级词元化。
- 机器翻译指的是将文本序列从一种语言自动翻译成另一种语言。
- 使用单词级词元化时的词表大小,将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,我们可以将低频词元视为相同的未知词元。
- 通过截断和填充文本序列,可以保证所有的文本序列都具有相同的长度,以便以小批量的方式加载。
编码器-解码器架构
- "编码器-解码器"架构可以将长度可变的序列作为输入和输出,因此适用于机器翻译等序列转换问题。
- 编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
- 解码器将具有固定形状的编码状态映射为长度可变的序列。
序列到序列学习(seq2seq)
使用两个循环神经网络的编码器和解码器,将其应用于序列到序列类的学习任务。
- 根据“编码器-解码器“架构的设计,我们可以使用两个循环神经网络来设计一个序列到序列学习的模型。
- 在实现编码器和解码器时,我们可以使用多层循环神经网路。
- 我们可以使用遮蔽来过滤不相关的计算,例如在计算损失时。
- 在"编码器-解码器"训练中,强制教学方法将原始输出序列(而非预测结果)输入解码器。
- BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的元语法的匹配度来评估预测。
束搜索
- 序列搜索策略包括贪心搜索,穷举搜索和束搜索。
- 贪心搜索所选取序列的计算量最小,但精度相对较低。
- 穷举搜索所选取序列的精度最高,但计算量最大。
- 束搜索通过灵活选择束款。在正确率和计算代价之间进行权衡。
束搜索每一步都有一个束宽,就是候选状态的数量,每次计算出一个值(可能是概率或者其他值)。
选取这个值的前几名作为候选状态。

















 4485
4485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









