







An Image Is Worth 16*16 Words:Transformers For Image Recognition at scale
- 发表:ICLR 2021
- idea:直接将transformer应用于图像,若以像素为transformer中的token计算复杂度过大( O ( n 2 ) O(n^2) O(n2)级别),且像素不同于nlp中的token,像素无法代表一定的语义信息。因此作者考虑将图像中的一小块(patch)作为一个token,然后类似地为每个token添加一定的位置信息。
- 代码:VIT
- 视频讲解:VIT论文+源码
详细设计
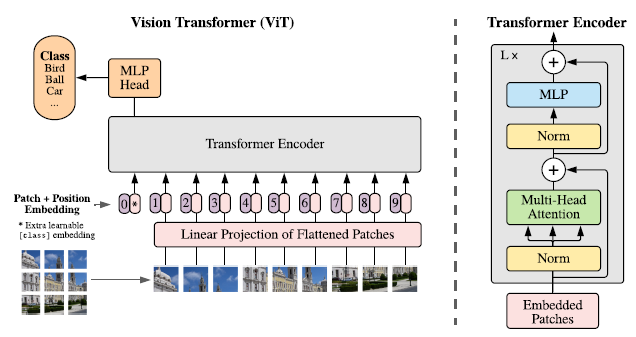
可以大致分为5个步骤,分别是:
- 将image划分为patch并转化为embedding
- 添加位置信息
- 输入到trm(transformer)中
- CLS输出用于多分类任务
(1) patch划分及映射
- 即将一张图像( W ∗ H ∗ C W*H*C W∗H∗C)划分为若干个patch( n ∗ p a t c h _ s i z e ∗ p a t c h _ s i z e ∗ C n*patch\_size*patch\_size*C n∗patch_size∗patch_size∗C),然后将patch映射到dim纬度( n ∗ d i m n*dim n∗dim)。
- 具体做法:首先划分,然后将patch沿通道方向拉直,再经过Linear层进行映射。在实现的时候可以借助Conv2d函数,将kernal_size和stride设置为patch_size,卷积核个数设置为dim
- 这时就将一张图像转换为一个token序列
(2)添加位置信息
- 首先在每个序列前生成CLS的token embedding,用于后续的分类任务(具体的设计可以追溯到bert)。这时一个序列的长度为n+1
- 生成所有位置的位置编码(是参数,通过模型学习)
- 将各个token的token embedding和位置编码相加作为融合了位置信息的新的embedding
(3)trm模型
- 与原始的transformer差别不大,主要是norm的位置,还有在vit中不需要进行zero padding操作,因为每个序列的长度都是一致的。
(4)输出
对于不同的任务,可以使用CLS用于预测或者将所有token取平均














 1799
1799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









