







1. 双流网络
- idea:一个卷及网络无法很好地处理时序信息,再添加一个卷积网络专门处理时序信息
- 做法:一个CNN用于处理空间信息(RGB图像);另一个CNN用于处理光流信息(光流图像)
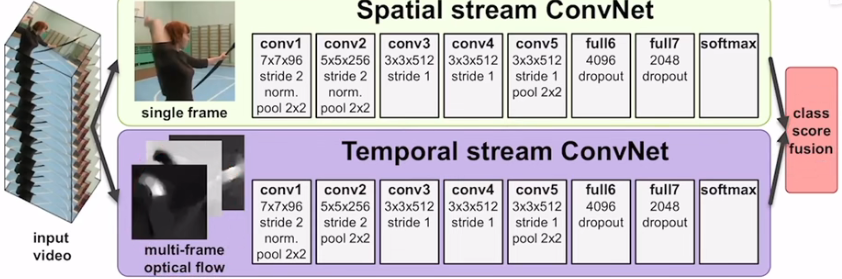
- 基于该想法的一些跟进和尝试:
(1)early fusion:在两个网络之间增加一些交互和融合:算是对网络的一种约束,使得模型在早期的训练中就能够在两个分支网路中进行相互学习(可能在一定程度上弥补了数据不足的问题)。
(3)用LSTM处理特征模拟时序信息增强特征:对于短视频,LSTM的提升效果有限。分析:LSTM是一种偏high-level的操作,更强调语义信息,因此输入需要有一定的变化才能够发挥LSTM的优势。
(4)对长时间的视频理解的处理,图像和光流可能无法捕捉到关键的信息。TSN:将视频分成几段,每一段都输入双流网络得到的空间特征和时间特征分别做融合(pooling或LSTM),然后再对两种特征做late fusion(平均)
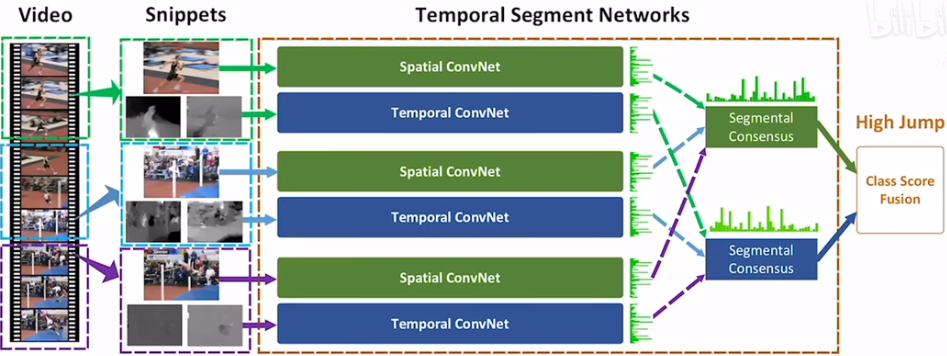
训练技巧: - Cross Modality Pretrain:RGB图像的预训练模型迁移到光流图像,通道数由原来的3变成了2K。通道参数初始化处理:将第一个conv层中的通道做mean pooling变成一个通道,然后复制2K次。(ps:在swin transformer中,将图像的模型应用到视频中初始化也是将通道的纬度进行复制)
- Regularization:partial BN:虽然BN能够让训练加速,但是也带来了严重的过拟合问题(数据集小的情况),将除了第一层的BN全部冻住,以适应新的输入
- Data Augmentation:corner cropping(随机裁剪一般都会在中心附近,难以照顾到边边角角的位置,这里corner cropping强制裁剪边角的位置)和scale jittering(改变长宽比增加数据的多样性):
2. 3D CNN
提取光流信息非常耗时且占空间,训练和测试的时候容易卡io
C3D
- 意义:用更深的3D卷积神经网络在大规模的数据集上训练并在一些任务上取得很好的表现。(但其实实验结果并不能达到最优,)
- 做法:将 3 ∗ 3 3*3 3∗3的二维卷积核替换成 3 ∗ 3 ∗ 3 3*3*3 3∗3∗3,其实就是3D版本的VGG
- 结论:3D网络相对2D网络更适合视频理解类任务。C3D的训练非常耗时(一个多月),普通实验室无法负担,所以如果想fine-tuning是难以实现的。因此作者提供了python和matlab的接口可以抽取输入视频的4096维特征。例如现在的video detection,video caption等任务都是使用这种提取好的特征进行训练,训练的代价要小很多也更容易。
I3D
- 意义:降低了网络训练的难度,证明了2D网络迁移到3D网络的可行性,提出了一个大数据集,在很多benchmark数据集上表现很好,奠定了3D网络的地位
- idea:作者认为C3D预训练之后效果不佳是由于没有一个好的初始化,从而让接下来的训练更简单。作者想用在imagenet上训练好的2D网络来初始化3D网络,即将2D网络膨胀(inflated)成3D网络,整体结构并不改变,知识卷积核从二维变成了三维,这样就能够将预训练的2D网络参数移植到3D网络中。
- 小结:通过膨胀操作可以使用在imagenet上训练好的2D网络结构和参数,能够利用更少的时间达到更好的效果。
Non-local Neural Networks
- 发表:CVPR 2018
- idea:卷积和递归操作都是在局部区域里进行处理,视野有局限。如果能够看到更长的上下文信息应该会对任务有所帮助。作者提出non-local模块(即插即用,能够用到各种网络中)用于建模长距离信息。
- 方法:其实就是标准的自注意力操作的3D版本,(时空自注意力)
- 意义:将self-attention引入视觉领域,针对视频领域的问题,将space attention 扩展为space time attention。在这篇论文之后,更少有人使用LSTM。(nlp领域一般使用transformer,cv更多地使用non-locla算子)
R(2+1)D
- 发表:CVPR 2018
- idea:做了一个详尽的调查:对于时空卷积,究竟是用2D好还是3D好。作者发现,仅仅使用一帧一帧的2D特征在效果上也很好,因此作者想看看什么样的结构能够有更好的表现。最后通过实验发现将3D卷积拆分成空间上的2D+时间上的1D效果最好。(3D卷积很耗卡)
- 实验内容
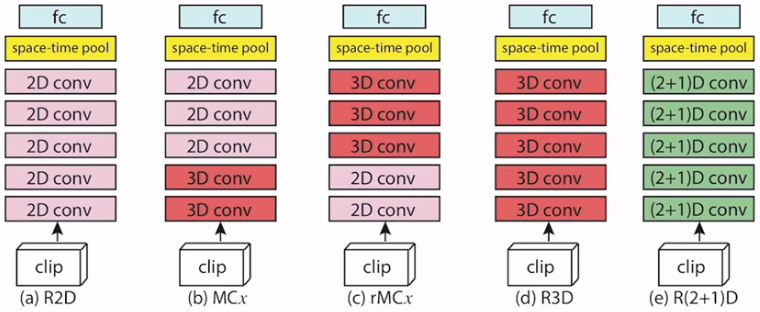
结论:2D+3D比纯2D或纯3D的网络要好,拆分网络(2+1D)最好 - 方法
将3D卷积拆分成先做空间上的卷积,再做时间上的卷积
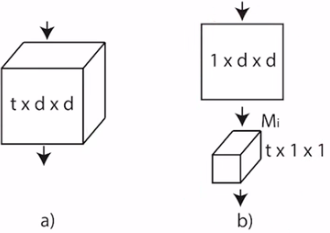
分析:1)拆分的方式增强了网络的非线性。纯3D卷积只有一次非线性,而拆分的方式有两次。因此模型的非线性能力有所增强,从而加强了学习能力。2)从优化的角度来看,2+1D的形式更容易优化和训练。
SlowFast Networks for Video Recognition
- idea:启发于人类的视觉系统中处理静态图像的p细胞占比80%,而处理高频运动信息的m细胞占比20%,与双流网络的设计类似(两个stream分别处理静态和动态信息)。作者考虑也用两个分支:慢分支(p细胞,占用大部分的模型参数。小输入大网络)以较低的帧率学习静态图像的特征,即场景信息。快分支以较高的频率采样(模拟m细胞,小模型。大输入小网络)学习运行信息。两个分支之间进行network connection进行交互学习。
- 方法:慢分支就是标准的I3D网络(采样4帧),快分支是小的I3D网络(通道数很小,采样32帧)。在时序上没有进行下采样
3. Video Transformer
Is Space-Time Attention All You Need for Video Understanding?
- idea:实验性论文。如何把vision transformer从图像迁移到视频领域。
- 比较方法
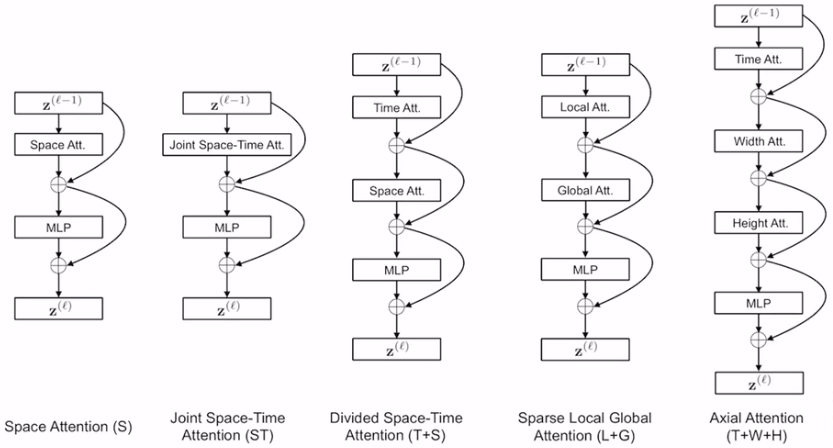
从左到右依次是
1)空间注意力,baseline,即图像上的vision transformer用的自注意力
2)暴力做法:在三个纬度上都做self-attention。(太大了,当帧数上升,无法训练)
3)参考2+1D网络架构,将时空分开来做。(大大降低了计算复杂度)
4)local-global方式,有些类似swin transformer。先算局部,在此基础上算全局(也能够降低复杂度)
5)只沿着特定的轴做attention,将三维问题拆分成三个一维的问题(降低复杂度)。
可视化5种方法能够关注到的区域(以frame t的蓝色区域为基准)

从结果中看,T+S的效果最好















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









