







 本文详细解析了Hadoop和Spark的Shuffle过程,包括Hadoop的Map-Shuffle和Reduce-Shuffle阶段,以及Spark的Sort-Based Shuffle。文章讨论了Shuffle的必要性、HashShuffle的缺点和优化,以及如何通过参数调整改善性能。同时,提到了数据倾斜、网络传输效率和负载均衡等关键问题,以及相应的调优策略。
本文详细解析了Hadoop和Spark的Shuffle过程,包括Hadoop的Map-Shuffle和Reduce-Shuffle阶段,以及Spark的Sort-Based Shuffle。文章讨论了Shuffle的必要性、HashShuffle的缺点和优化,以及如何通过参数调整改善性能。同时,提到了数据倾斜、网络传输效率和负载均衡等关键问题,以及相应的调优策略。
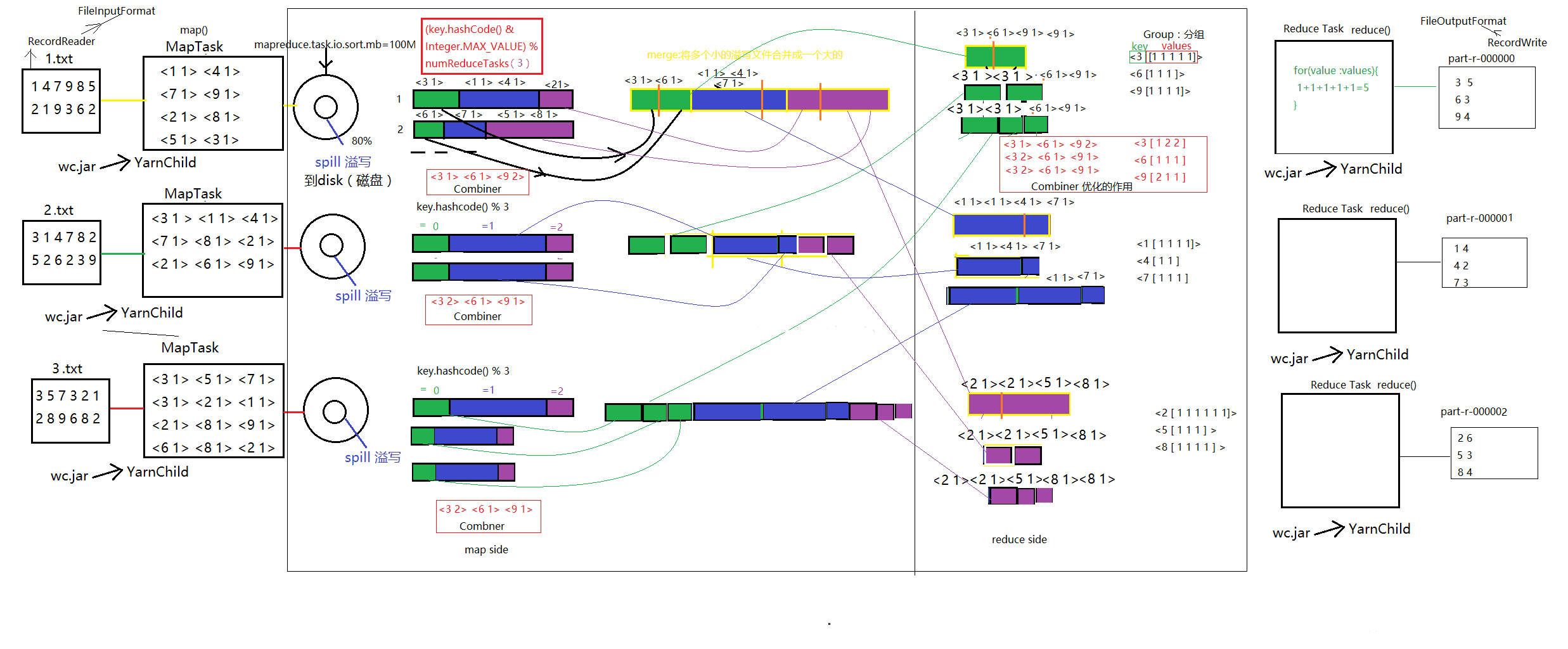
Hadoop Shuffer#
Hadoop 的shuffer主要分为两个阶段:Map、Reduce。
Map-Shuffer:#
这个阶段发生在map阶段之后,数据写入内存之前,在数据写入内存的过程就已经开始shuffer,通过设置mapreduce.task.io.sort.mb的参数,可改变内存的大小,默认为100M。数据在写入内存大于80%时,会发生溢写spill)过程,将数据整体落地到磁盘,这个过程中默认调用快速排序算法进行排序,否则调用用户自定义的 combiner()方法,将数据按照排序的规则分布在分区。然后进入mapshuffer最后一个阶段merge,当磁盘中某一个分区的文件数量>=3个,自动触发文件合并合并程序,这个过程将一个分区的所有数据进行排序合并成一个文件目录(归并算法),以供reduce抓取。
(k,v,p) :一条数据,其中p是分区号。
Reduce-Shuffer:#
通过拷贝线程copy merge中的数据到reduce端,调用归并算法,生成一个个Iterator,再通过分组程序,将同一个key的分组放在一起,聚合为一个Iterator。
Spark-Shuffer#
Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-Based Shuffle。有分布式就一定会有 Shuffle,而且 HashShuffle 是 Spark以前的版本,亦即是 Sort-Based Shuffle 的前身,因为有 HashShuffle 的不足,才会有后续的 Sorted-Based Shuffle,以及现在的 Tungsten-Sort Shuffle。
Spark可以基于内存、也可以基于磁盘或者是第三方的储存空间进行计算:
第一、Spark框架的架构设计和设计模式上是倾向于在内存中计算数据的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









