









window API
window API
Window 概述
streaming流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限 数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据 为有限块进行处理的手段。Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大 小的”buckets”桶,我们可以在这些桶上做计算操作。
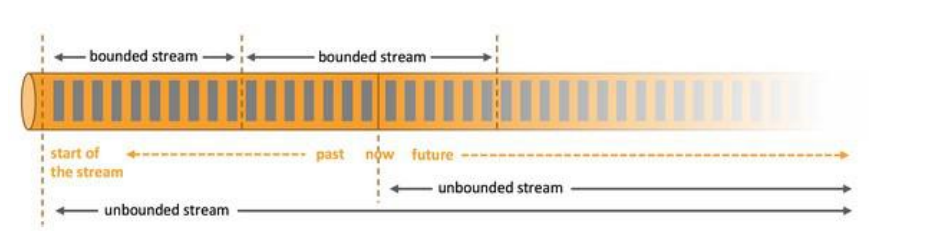
- 一般真实的流都是无界的,怎样处理无界的数据?
- 可以把无限的数据流进行切分,得到有限的数据集进行处理 —— 也就是得到有界流
- 窗口(
window)就是将无限流切割为有限流的一种方式,它会将流数据分发到有限大小的桶(bucket)中进行分析
window窗口的分类
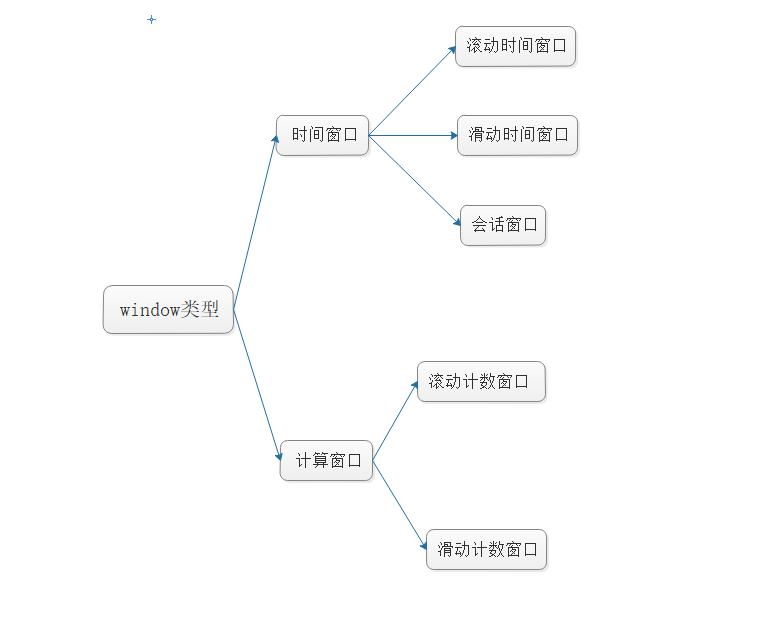
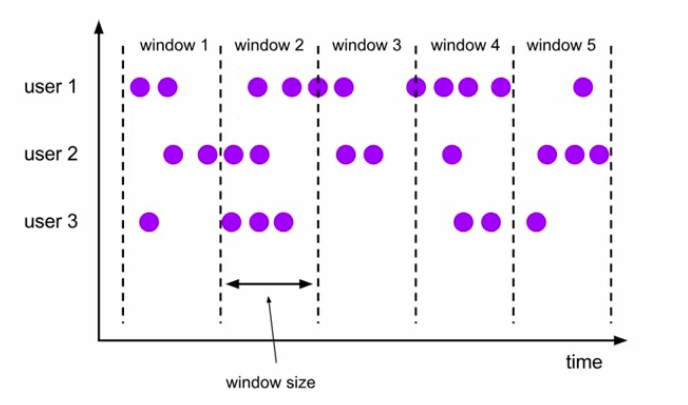
滚动窗口(Tumbling Windows)
-
将数据依据固定的窗口长度对数据进行切分
-
时间对齐,窗口长度固定,没有重叠
-
定义的时候只需要一个参数:
Window size即可
滑动窗口(Sliding Windows)
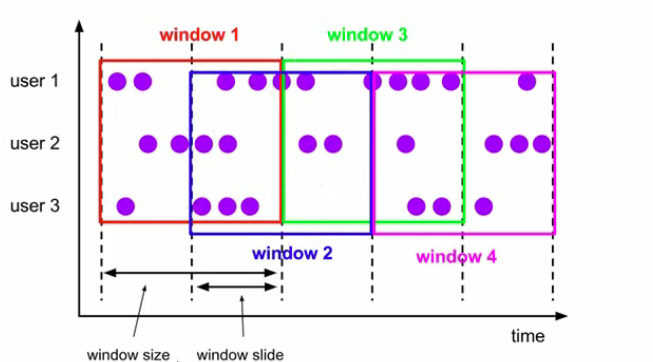
- 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
- 窗口长度固定,可以有重叠
- 需要两个参数,一个是窗口大小和滑动的大小
- 滑动窗口可以看作是一个特殊的滚动窗口(滑动间隔等于大小的)
会话窗口(Session Windows)
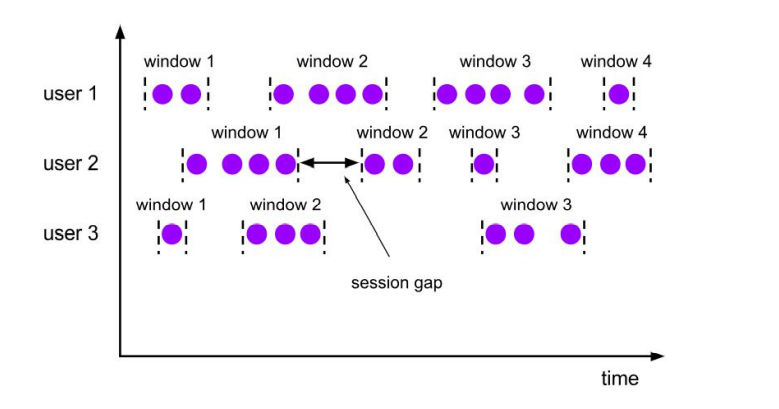
- 由一系列事件组合一个指定时间长度的 timeout 间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
- 特点:时间无对齐
Window的使用
窗口分配器–Window方法
我们一般使用.window来定义一个窗口,然后基于window去做一些聚合或者其他处理操作。window必须在keyBy之后
滚动时间窗口的定义
val resultStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(_._1) //按照二元组第一个元素id分组
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
滑动时间窗口的定义
val resultStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(_._1) //按照二元组第一个元素id分组
.window(SlidingEventTimeWindows.of(Time.seconds(15), Time.seconds(3)))
会话窗口
val resultStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(_._1) //按照二元组第一个元素id分组
.window(EventTimeSessionWindows.withGap(Time.seconds(15)))//间隔时间大于15秒就新建会话
上述书写的方法虽然可行,但是由于方法名称很长,很难记忆,所以可以使用下面的方法来简写
val resultStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(_._1) //按照二元组第一个元素id分组
.timeWindow(Time.seconds(15), Time.seconds(3))
参数为一个的时候就是滚动,参数为两个就是滑动
滚动基数窗口
val resultStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(_._1) //按照二元组第一个元素id分组
.countWindow(10)
滑动计算窗口
val resultStream = dataStream
.map(data => (data.id, data.temperature))
.keyBy(_._1) //按照二元组第一个元素id分组
.countWindow(10,5)
window function定义了要对窗口中收集的数据做的计算操作 ,他可以分为两类
-
增量聚合函数(
incremental aggregation functions)- 每条数据到来就进行计算,保持一个简单的状态
ReduceFunction,AggregateFunction
-
全窗口函数(
full window functions)- 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
ProcessWindowFunction
其他函数
-
**
.trigger()—— 触发器 ,定义 window 什么时候关闭,触发计算并输出结果 ** -
.evictor()—— 移除器 ,定义移除某些数据的逻辑 -
.allowedLateness()—— 允许处理迟到的数据 -
.sideOutputLateData()—— 将迟到的数据放入侧输出流 -
.getSideOutput()—— 获取侧输出流
测试
每五秒统计窗口内个传感器的温度最小值,以及最新的时间戳
package WindowAndWatermark
import Source.SensorReading
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WindowTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
val inputStream = env.socketTextStream("localhost", 7777)
//转换成样例类
val dataStream = inputStream
.map(data => {
val arr = data
.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
})
//每十五秒统计窗口内个传感器的温度最小值,以及最新的时间戳
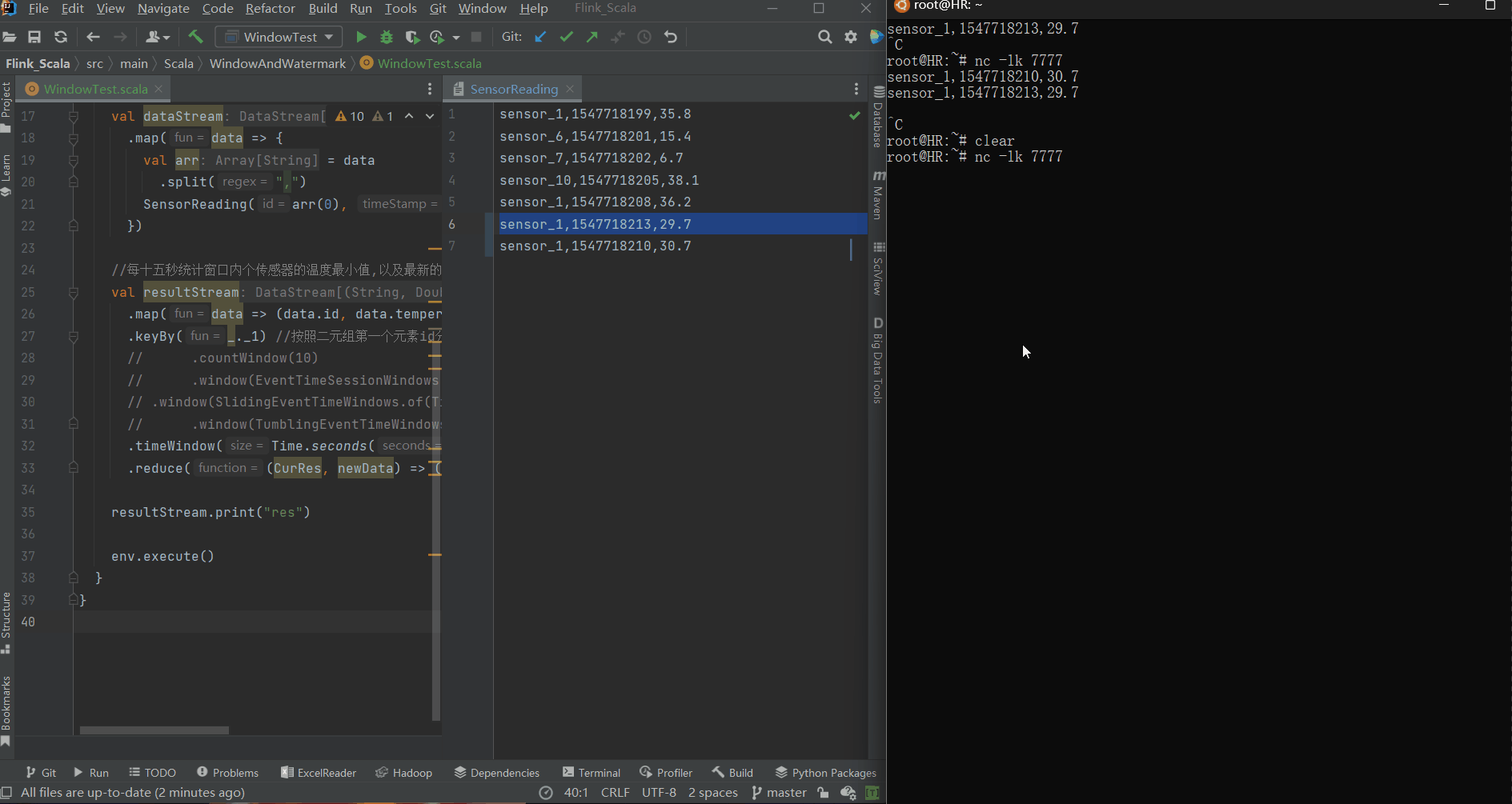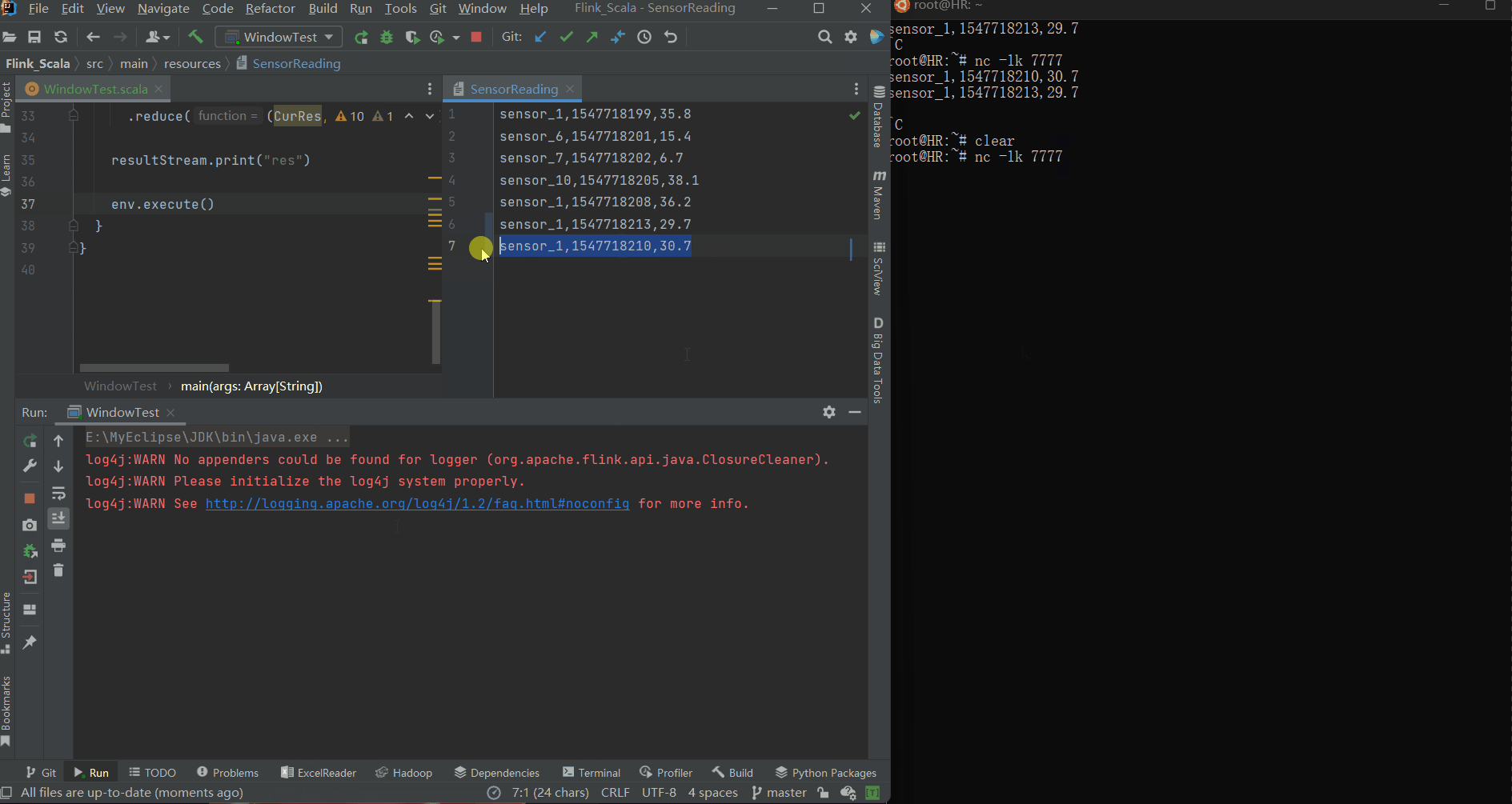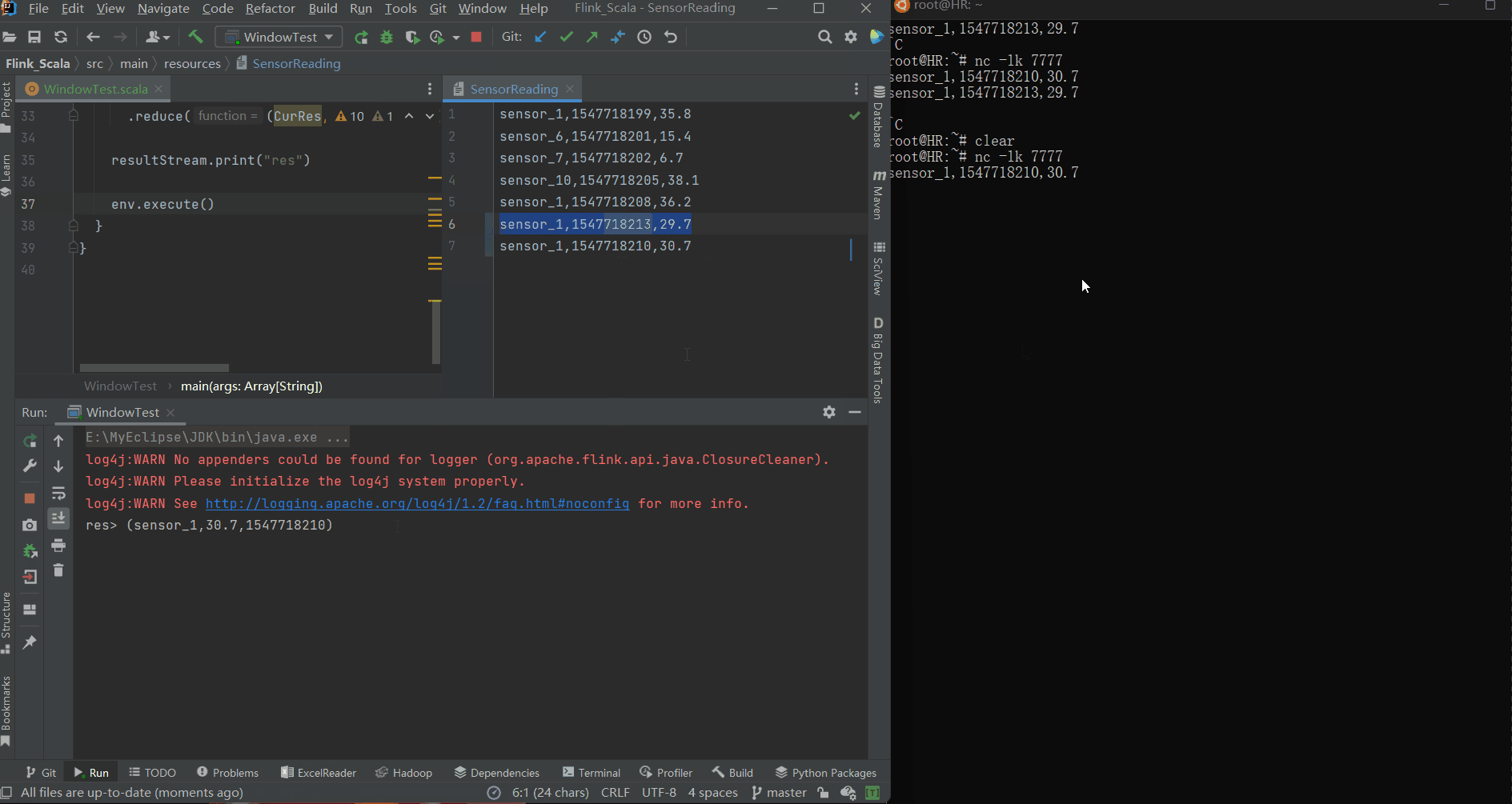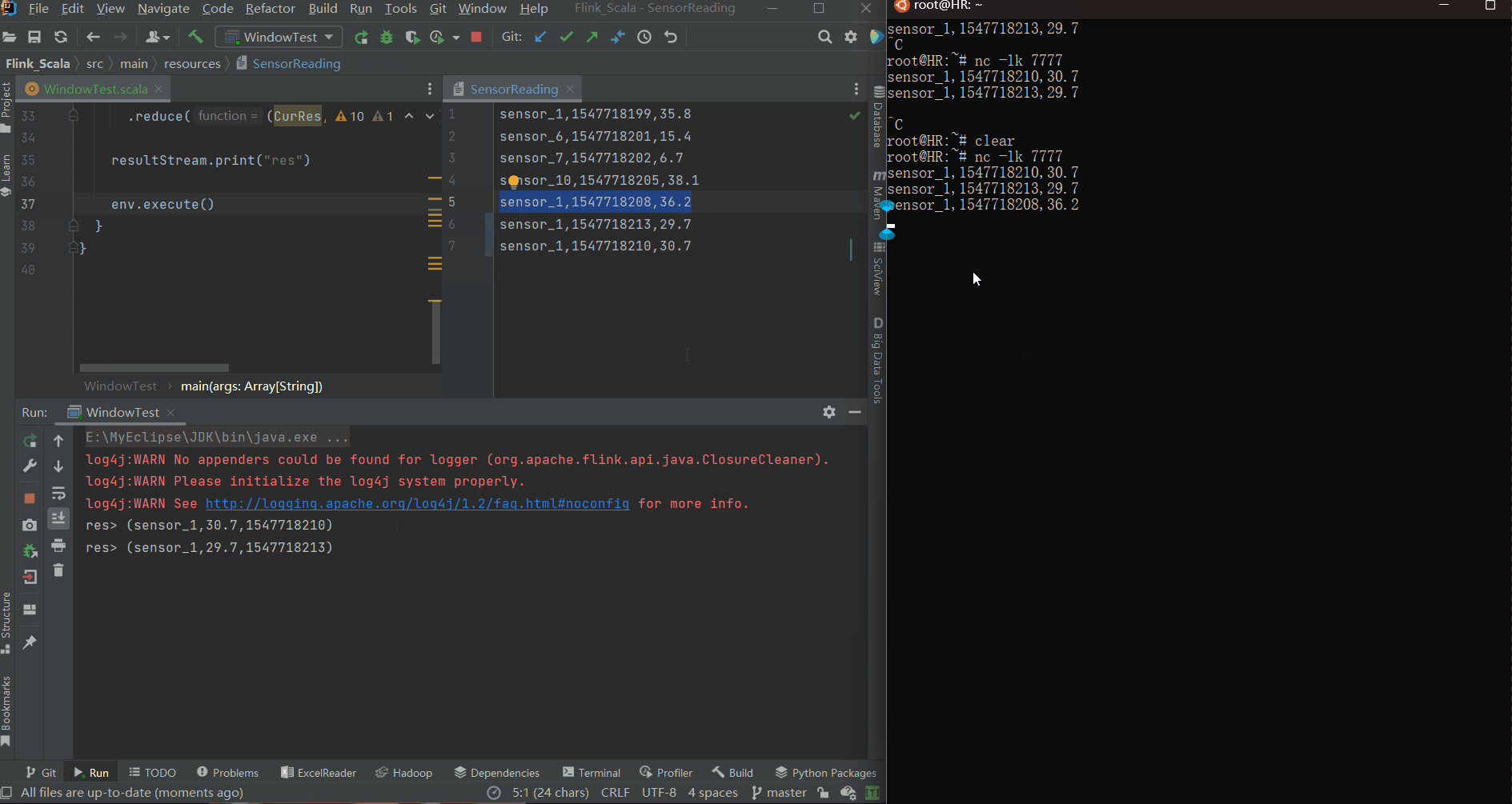
val resultStream = dataStream
.map(data => (data.id, data.temperature, data.timeStamp))
.keyBy(_._1) //按照二元组第一个元素id分组
.timeWindow(Time.seconds(5))
.reduce((CurRes, newData) => (CurRes._1, CurRes._2.min(newData._2), newData._3))
resultStream.print("res")
env.execute()
}
}














 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









