







Apache Flink–DataStream–Window
什么是Window?有哪些用途?
下面我们结合一个现实的例子来说明。
我们先提出一个问题:统计经过某红绿灯的汽车数量之和?
假设在一个红绿灯处,我们每隔15秒统计一次通过此红绿灯的汽车数量,如下图:
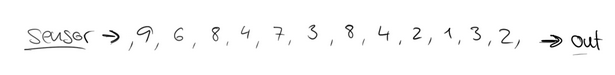
可以把汽车的经过看成一个流,无穷的流,不断有汽车经过此红绿灯,因此无法统计总共的汽车数量。但是,我们可以换一种思路,每隔15秒,我们都将与上一次的结果进行sum操作(滑动聚合),如下:
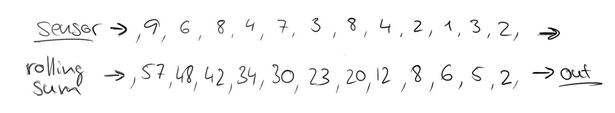
这个结果似乎还是无法回答我们的问题,根本原因在于流是无界的,我们不能限制流,但可以在有一个有界的范围内处理无界的流数据。
因此,我们需要换一个问题的提法:每分钟经过某红绿灯的汽车数量之和?
这个问题,就相当于一个定义了一个Window(窗口),window的界限是1分钟,且每分钟内的数据互不干扰,因此也可以称为翻滚(不重合)窗口,如下图:
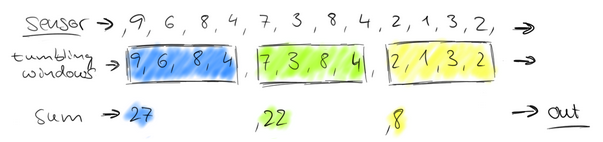
第一分钟的数量为8,第二分钟是22,第三分钟是27。。。这样,1个小时内会有60个window。
再考虑一种情况,每30秒统计一次过去1分钟的汽车数量之和:
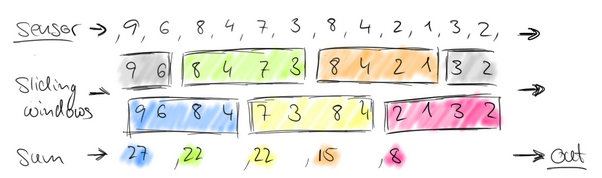
此时,window出现了重合。这样,1个小时内会有120个window。
扩展一下,我们可以在某个地区,收集每一个红绿灯处汽车经过的数量,然后每个红绿灯处都做一次基于1分钟的window统计,即并行处理:
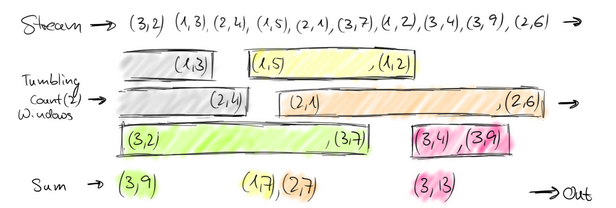
通常来讲,Window就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。window又可以分为基于时间(Time-based)的window以及基于数量(Count-based)的window。
Flink DataStream API提供了Time和Count的window,同时增加了基于Session的window。同时,由于某些特殊的需要,DataStream API也提供了定制化的window操作,供用户自定义window。
下面,主要介绍Time-Based window以及Count-Based window,以及自定义的window操作,Session-Based Window操作将会在后续的文章中讲到。
1、Time-Based Window
1.1、Tumbling window(翻滚)
此处的window要在keyed Stream上应用window操作,当输入1个参数时,代表Tumbling window操作,每分钟统计一次,此处用scala语言实现:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling time window of 1 minute length
.timeWindow(Time.minutes(1))
// compute sum over carCnt
.sum( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









