






 本文介绍如何使用MATLAB的parfor循环进行并行处理,以加速慢速for循环的执行。通过实例展示了parfor循环在并行池中的workers上运行的过程,以及如何评估并行开销和数据传输的影响。
本文介绍如何使用MATLAB的parfor循环进行并行处理,以加速慢速for循环的执行。通过实例展示了parfor循环在并行池中的workers上运行的过程,以及如何评估并行开销和数据传输的影响。
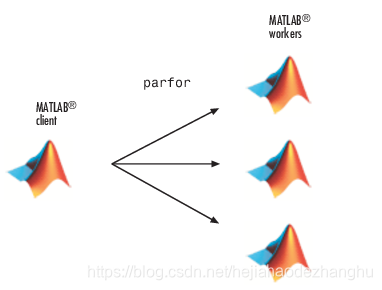
在并行池里的workers上运行parfor来使用并行处理
并行工具箱支持交互式并行计算,并且通过并行池中运行的多个workers上加速工作流。在并行池中的workers上使用parfor执行for-loop迭代。当你已经形成你的代码,并且定义慢的for-loop,尝试增加parfor进去。在桌面开发parfor-loops和放大到集群是不会改变代码。
函数和类
parfor | 在并行池中的workers上执行for循环迭代 |
parpool | 在集群上创建并行池 |
parfeval | 在并行池上的worker异步地执行函数 |
ticBytes | 开始计算在并行池中传输的字节数 |
tocBytes | 读取从ticbytes传输的字节 |
send | Send da使用数据队列从workers发送到客户端 |
afterEach | 当数据接收时定义一个函数来调用 |
parallel.Pool | 进入并行池 |
parallel.pool.DataQueue | 能发送和监听客户端和workers之间的数据 |
开始使用parfor
何时使用parfor?
如果有一个慢的for-loop,parfor-循环能变得有用。以下情况考虑parfor
1、一些迭代运算需要花费长时间来执行。在这种实例下,workers能同时地执行长迭代。确保迭代次数执行的workers的个数。否则不能使用全部的workers。
2、大多数循环迭代是简单的计算,列如蒙特卡洛仿真或者一个参数交换,parfor将循环分成组。每个workers执行总迭代中的一部分。
一个parfor循环在以下情况下也许无用
1、for循环已经向量化输出。通常地,如果你想让代码运行跟快,首先尽量去向量化它。详见Vectorization(向量化,matlab)向量化代码允许你从构建并行中获益,这些由许多matalb运行库多线程自然提供。然而,如果你已经向量化代码并且也已经值进入本地workers,parfor-loops也许运行更慢。向量化的代码不允许parfor循环,正常情况下这个方式也不会工作。
2、循环迭代在短时间内执行。这样计算就会产生并行开销域(浪费)
当循环里的迭代依赖于其他迭代的结果时,不能使用parfor-loop。每一个迭代必须独立于全部其他迭代。为了帮助处理独立循环,详见Ensure That parfor-Loop Iterations are Independent. 。可接受的规则是在循环里的累积值使用Reduction Variables.
为了决定什么时候使用parfor,考虑并行开销。并行开销包括的时间需求有通信,同步和数据传输-发送和接受数据-从客户端到workers并且返回。如果迭代更新很快,这些开销可能会使总时间中明显的一部分。考虑到两种不同类型的循环迭代:
1.for-loops有一个计算严苛的计算任务。这些循环通常很好适合转换为parfor-loop,因为需计算域的时间需求,满足数据传输时间。
2.for-loops有一个简单的计算任务。这些计算通常不利于转化到parfor-loops,因为传输的时间相比较计算时间来说需求明显。
使用实例,
在这个实例中需要内置for-loops。for-loops是慢的并且使用parfor-loops替代来加速。parfor分块执行for-loops迭代在并行池中的workers。
这个实例计算一个矩阵的频谱度,并且转换一个for-loops到一个parfor-loops。找出如何车辆加速结果和多少数据传输进和多少来自并行池中的workers。
1.在编辑器中输入以下代码加入tic和toc测量计算时间。
tic
n = 200;
A = 500;
a = zeros(n);
for i = 1:n
a(i) = max(abs(eig(rand(A))));
end
toc
2.运行脚本注意消耗时间
3、使用parfor-loop替代后
tic
ticBytes(gcp);
n = 200;
A = 500;
a = zeros(n);
parfor i = 1:n
a(i) = max(abs(eig(rand(A))));
end
tocBytes(gcp)
toc
运行后比较结果
这个例子具有低的并行开销和来自转换到parfor-loop后的益处。相比较之后看下一个实例。parfor-loops高并行开销实例。
===========================未完

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









