









2015ICCV会议最佳论文奖,即有着“计算机视觉界最高奖”之称的马尔奖(Marr Prize)授予了由微软剑桥研究院(Microsoft Research, Cambridge UK)、卡内基梅隆大学和意大利布鲁诺凯斯勒研究中心(Fondazione Bruno Kessler)合作的论文“深度神经决策森林(Deep Neural Decision Forests)”。论文提出将分类树模型和深度神经网络的特征学习相结合进行端到端训练的深度学习方法。该方法使用决策森林(decision forest)作为最终的预测模型,提出了一套完整的、联合的、全局的深度学习参数优化方法。在手写数据库MNIST和图像分类数据库ImageNet的实验中都取得了超越当前最好方法的结果。这是傅建龙老师、梅涛老师和罗杰波老师对本篇论文的简介。
本人最近要作这篇文章的组会报告,在以上三位老师介绍的基础上,有了大概的了解,对这篇论文进行了学习。我们做深度学习的同学都知道,怎么训练学习模型和测试是重点,即将深度学习框架和随机森林结合在一起,如何前向传播和反向传播呢?以及叶子节点预测分布的更新?本篇博客分为三个部分重点阐述这些问题。
一、前向传播
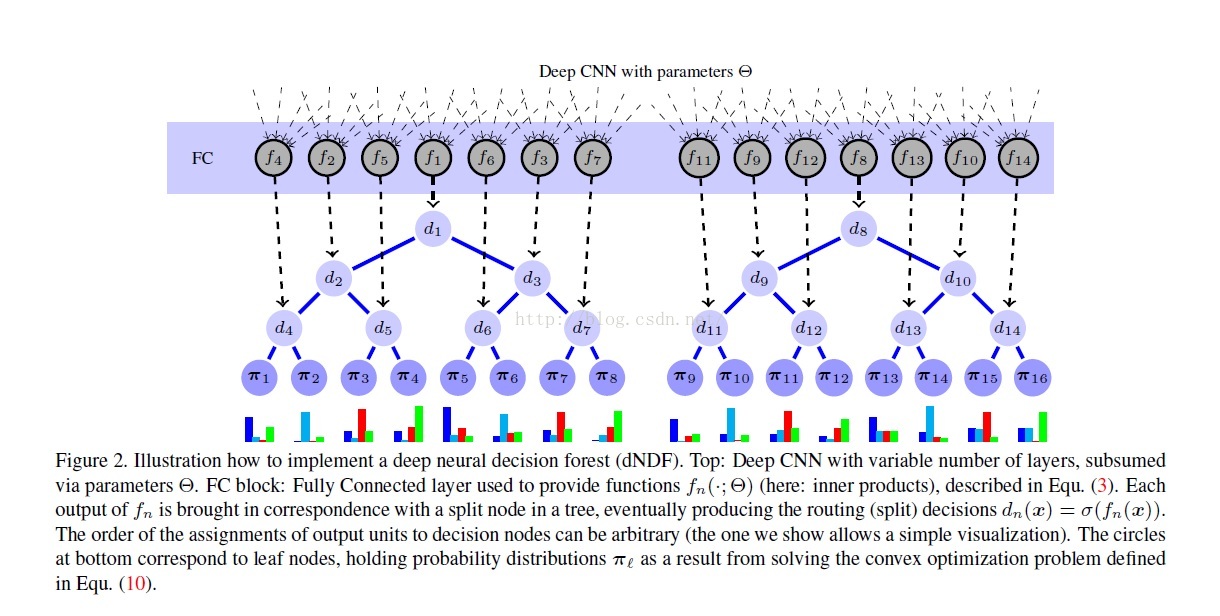
预备知识:由图可知,每个分离节点(split nodes)的参数由DNN来学习(representation learning),DNN最后一层是全连接层,每个节点单元的输出作为分离节点决策函数(d1,d2,...)的输入参数,本篇论文采用的决策函数是sigmoid函数。知道决策函数后,我们可以计算其路径函数(routing function),每棵树的根节点,其路径函数的值赋予1,然后乘以该节点的决策函数值d,得到左边子节点的路径函数1*d,右边子节点的路径函数值为1*(1-d),以此类推,可以计算出每颗决策树节点的路径函数。
首先,我们要初始化分离节点决策函数的参数(theta),以及对叶子节点分布参数(pai)初始化为均匀分布。然后根据上面内容计算各个节点的路径函数(routing function)。当数据集的标签确定时,叶子节点的预测类别也是确定的,初始化时是均匀分布,当训练完成时,其(prediction)满足一定的概率分布。
然后,当样本来时,通过DNN,得到分离节点决策函数的参数,从而计算出决策函数和路径函数(routing function),到叶子节点时,我们使用该节点的路径函数乘以该节点监督类别的概率,作为预测输出,并通过对每个节点的预测输出进行求和,得到这棵树的预测输出,这样,我们就可以得到各个类别的概率输出。
二、反向传播
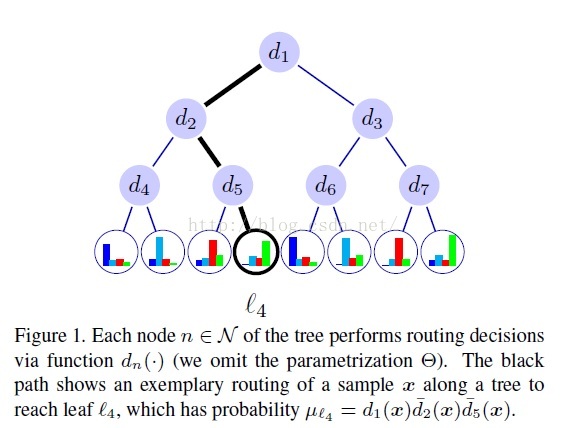
本篇论文的反向传播分为两个部分,第一部分是决策树的反向传播,第二部分是DNN的反向传播,紧跟在决策树后面,DNN的反向传播大家都很清楚。下面我们重点说一下本篇论文决策树如何反向传播?

由Decision tree决定的梯度部分,可以换算成如下公式:


即,由决策函数和A函数决定,在反向传播的过程中,首先达到的是叶子节点,通过以上公式,可以计算出叶子节点的决策函数和A函数,再往上,父节点的A函数由子节点的A函数相加得到,以此类推,只需一次反向遍历,就可以完成反向传播。
三、叶子节点分布函数
本篇论文采用交替迭代的方法,依次更新决策函数的参数和叶子节点分布函数,以上内容是对决策函数参数的迭代,对叶子节点分布函数的迭代如下:

为什么采用这个更新策略,文章作者在补充材料里进行了证明,即采用这种方式,目标函数是收敛的。本篇论文的迭代策略是:

以上是我对本文的理解,错误之处,烦请指出,谢谢!
关于2015 ICCV会议情况,推荐这篇文章:【CCCF动态】视觉的饕餮盛宴:第15届国际计算机视觉会议















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









