






LLM大行其道的时代,Transformer成为了当下最流行的模型结构,没有之一。为了达到加速或提效的目的,在vanilla Transformer的基础上,业界探索了针对不同组件的各种改进。
一、Self-Attention
1.1. Sparse Attention
标准的Attention,其计算复杂度和空间复杂度都是 �(�2) 级别的( � 是序列长度)。本质原因,在于序列中的任意两个token之间都要计算相关度,得到一个 �2 大小的Attention矩阵:

事实上,对于训练好的Transformer而言,其Attention矩阵经常是稀疏的。因此,若要降低复杂度,一种很直接的思路就是减少相关度的计算,即,认为每个token只跟序列内的一部分token相关(可以理解为特征选择),按某种预定义的pattern来进行token间的相关度计算,这便是Sparse Attention的基本原理。公式化如下:
�^�,�={������� ����� � ������ �� ����� �−∞�� ����� � ���� ��� ������ �� ����� �其中, −∞ 无需存储。
根据决定稀疏连接的不同方式,我们可以将Sparse Attention分为Position-based、Content-based。
Part I. Position-based Sparse Attention
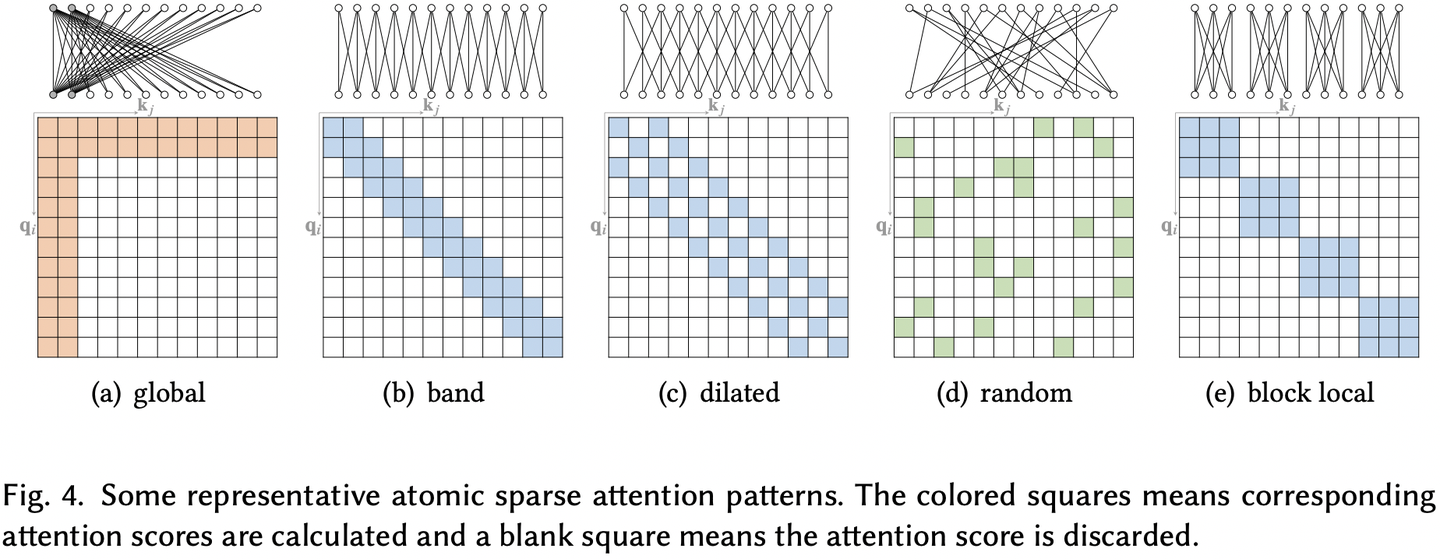
Attention矩阵按照某种预定义的稀疏pattern进行计算,这些pattern大都是基于一些原子pattern组合而来,我们把这些原子pattern分为5类:
- Global Attention:为了避免模型的长程依赖能力退化过多,增加一些全局token
- Band Attention(Sliding window Attention or Local Attention):大部分数据都带有局部性,因此限制token仅与相邻节点连接
- Dilated Attention:参考dilated CNNs做法,通过增加空隙以获得更大的感受野,而不增加复杂度
- Random Attention:通过随机采样,提升非局部的交互
- Block Local Attention:将输入序列划分为不重叠的block,仅在block内部进行连接
现有的Sparse Attention方法,基本都是通过对以上原子pattern进行组合来实现的:
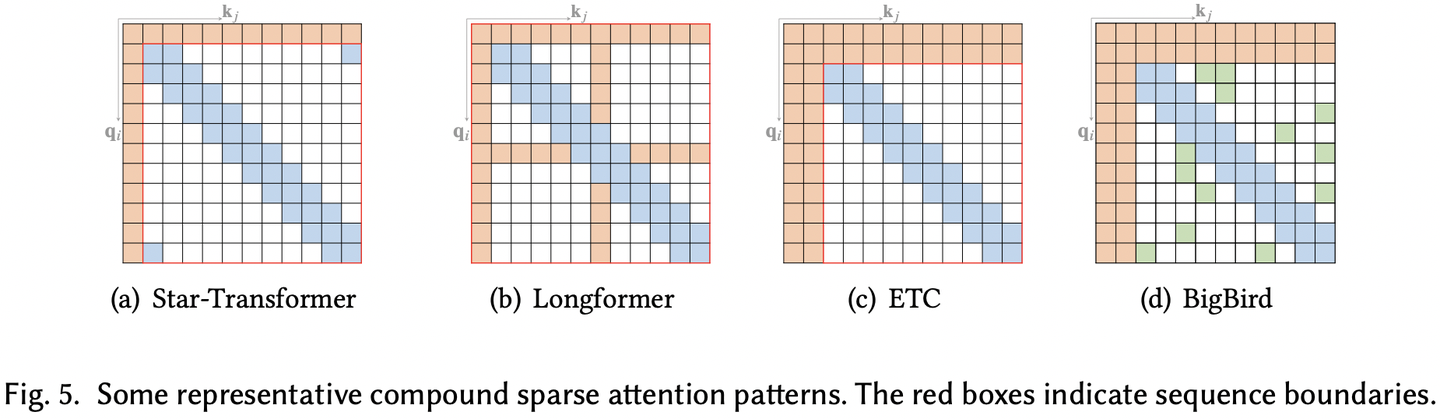
Part II. Content-based Attention
根据输入内容来确定稀疏连接,例如根据query和key的相似度进行K-means聚类,query仅与同cluster内的key进行连接;又或者,采用哈希方法对query和key进行分桶,query仅与同一个桶内的key进行连接。
Part III. 其它
Sparse Attention由于存在稀疏化,如何保证信息不丢失?主要有这么几种方式:
- 不同的head采用不同的原子pattern,组合使用
- 使用Global Attention,间接获得不相连节点的信息
- 使用Random Attention,可获得标准Attention的近似性能(随机图近似完全图)
1.2. Linearized Attention
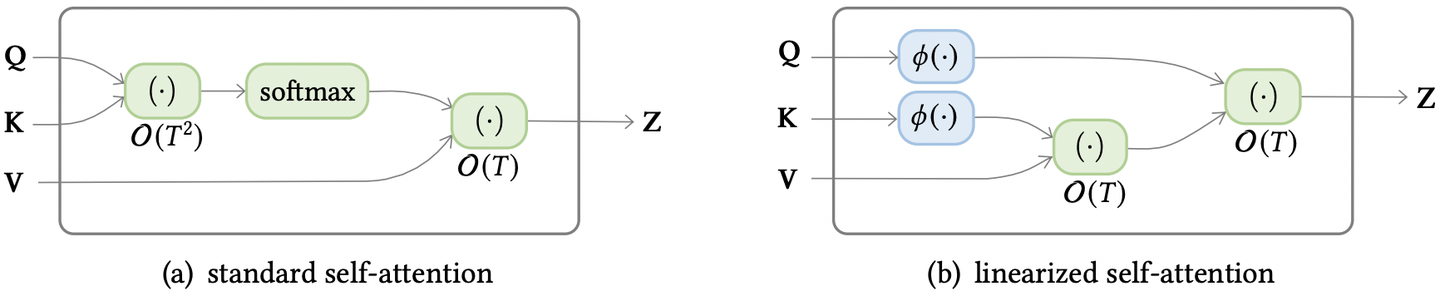
标准Attention可形式化如下:(简单起见,省略了缩放因子)���������(�,�,�)=�������(���)�其中, �∈��×��,�∈��×��,�∈��×�� 。不难推出,以上操作的计算复杂度为 �(�2) 。若去掉softmax操作,那么根据矩阵乘法的结合律,我们可以以 �(���) 的顺序完成计算,从而将复杂度降至 �(�) 。
进一步,我们将标准Attention等价为下式:���������(�,�,�)�=∑�=1����(��,��)��∑�=1����(��,��)若直接去掉softmax,则 ���(��,��)=����� ,但是内积无法保证非负性。因此,我们基于核函数的思想,采用以下替换: ���(��,��)=�(��)�(��)� ,当满足 �=� ,就相当于计算核函数定义下的内积,例如,有的论文选择 �(�)=�(�)=���(�)+1 。
1.3. Multi Query Attention & Grouped Query Attention
MQA和GQA都是加速推理的技巧,在此之前,我们先了解一下KV Cache。
Part I. KV Cache
KV Cache,说到底也是一种Cache,其核心思想依然是用空间换时间,可以在不影响计算精度的前提下,加速推理。目前,各大推理框架都已实现并将其进行了封装且默认开启。
Transformer的Decoder由于自回归式的结构,推理时的每个step,都需要用到之前step的所有token,为避免重复计算,我们考虑每个step缓存当前计算的key/value结果,这样之后的step便可直接读取缓存结果而免于计算。以上,便是KV Cache的原理。
然而,天下没有免费的午餐,KV Cache的使用受限于缓存大小。简单推导可得出Cache所需缓存为:2∗2∗�∗�∗������∗�������其中,b为batch_size,s为序列长度,假定参数用半精度存储。以GPT-3-175B为例,若batch_size=1,序列长度为100,则Cache需要缓存 2∗2∗100∗12288∗96=472�� 。目前最好的卡H100的SRAM缓存大概是50MB,A100则为40MB,因此,KV Cache只能进一步放到HBM中,而HBM的读写速度较之SRAM,差了一个数量级,继而导致推理速度降低。
于是,MQA和GQA便可派上用场了。
Part II. MQA & GQA
标准的Attention,我们称之为Multi-head——query、key、value均有相同数量的多个head。MQA与GQA的做法是,减少key、value对应的head数量——前者仅保留一个head,后者则将query分成多个group,同group内的key、value共享一个head。
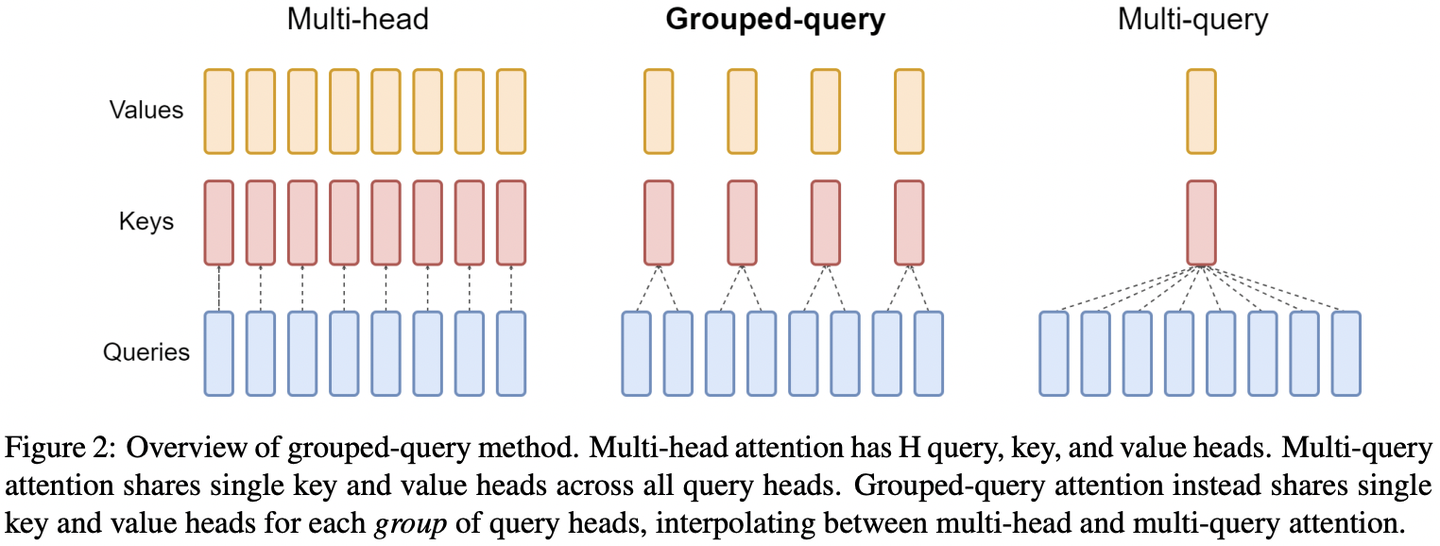
MQA和GQA的好处是显而易见的:减少head数量,KV Cache所需缓存也随之减少,SRAM因此满足需求,需要读取的key、value数量也减少,继而降低latency;另外,KV Cache减少,可以增大batch_size,从而增加吞吐量。(较之MHA,计算量变化不大)
要使用MQA和GQA,可以在预训练的时候就加上(from scratch,如PaLM),也可采用GQA论文中提出的Uptraining方式:在MHA的checkpoint基础上,将key、value的投影矩阵进行mean pool操作,转为MQA/GQA格式,再用少量预训练语料进行额外训练。
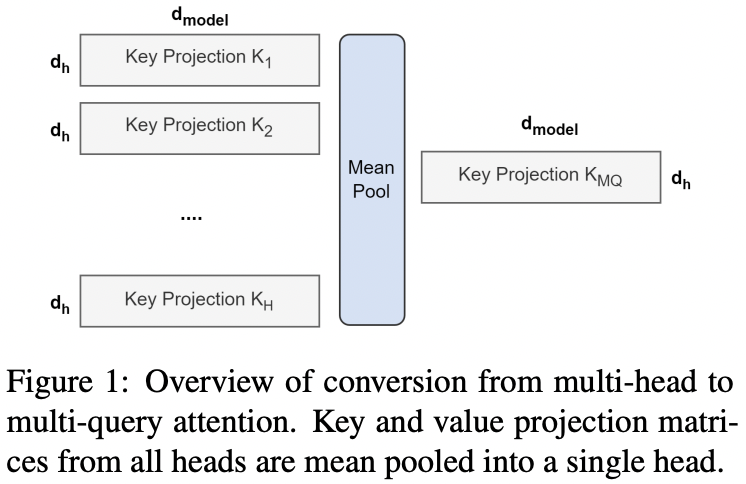
MQA与GQA,孰优孰劣呢?按照GQA论文中的说法,从头训练的MQA会带来训练的不稳定性,采用Uptraining方式会有所缓解,而采用Uptraining方式训练的GQA则未体现出该问题。另外,MQA虽然能够加速推理但是会带来效果的损失(尤其对于LLM而言,其head数量也在增长,MQA直接将head数量减少到1未免太过激进),而GQA则可看做是MHA与MQA之间的trade-off,实验表明,它可以达到近乎MHA的效果以及MQA的推理速度。尤其是,LLM由于参数量大幅增长,其内存带宽受限问题可能没有那么严重,因此无需过分减少head数量。因此,对于LLM而言,GQA或许是一个更好的选择。Meta开源的LLaMA2,采用的便是GQA。
1.4. Flash Attention
Part I. Flash Attention
Transformer之所以在扩充context window的路上充满挑战,很重要的原因在于其核心组件self-attention的计算复杂度和空间复杂度都是 �(�2) 级别的( � 是序列长度)。
有一些方法,采用了近似Attention的思路,如Sparse Attention、Low Rank Attention等,将Attention的计算复杂度降至线性或近线性,然后却并没有得到广泛的应用。主要原因在于,它们都聚焦于减少计算量(FLOP),而忽略了IO读写的内存访问开销。在现代GPU中,计算速度早已超越了内存访问速度,对于Attention而言,除了大矩阵乘法是计算带宽受限(compute-bound)的,其他操作(计算softmax,dropout,mask)都是内存带宽受限(memory-bound)的。因此,计算量的减少,并没有带来运行时间(wall-clock time)的减少。
首先解释一下GPU的内存分级。
如下图左所示,GPU的内存由多个不同大小和不同读写速度的内存组成。内存越小,读写速度越快。以A100-40GB为例,SRAM分布在108个流式多处理器上,每个处理器的大小为192K,合计 192∗108��=20,736��=20��。HBM(High Bandwidth Memory),也就是我们常说的显存,大小为40GB。SRAM的读写速度为19TB/s,而HBM的读写速度只有1.5TB/s,不到SRAM的1/10。上面讲到Attention是内存受限的,因此,减少对HBM的读写次数,有效利用更高速的SRAM来进行计算,是非常重要的。
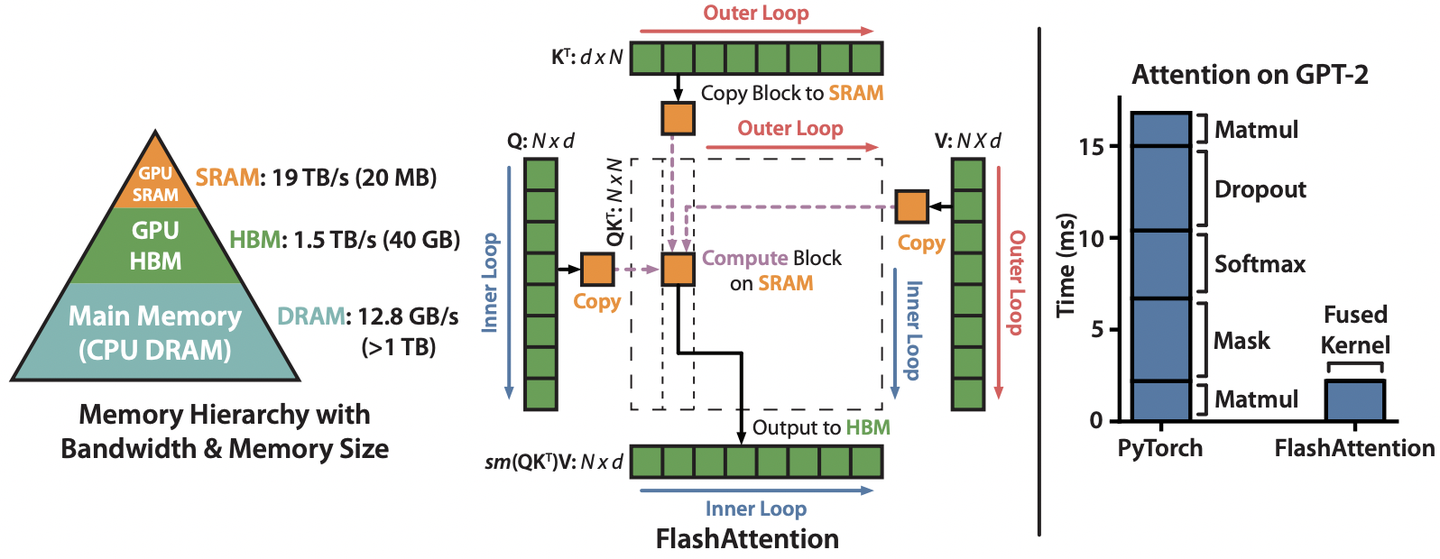
Flash Attention,可以加速训练并且有助于提升模型的long context能力。它基于tilling(分块计算)和重计算的方式,实现了“Fast and Memory-Efficient Exact Attention with IO-Awareness”:
- Fast(加快计算):Flash Attention并没有减少计算量,而是从IO感知出发,减少了HBM访问次数,从而实现wall-clock speedup(2-4x)
- Memory-Efficient(节省显存):Flash Attention通过引入统计量,改变注意力机制的计算顺序,避免了实例化注意力矩阵 �,�∈��×�,将空间复杂度从 �(�2) 降至 �(�)
- Exact Attention(精确注意力):与近似注意力方法不同,Flash Attention与标准Attention的结果完全等价
下面简要介绍Flash Attention的实现细节,主要参考自回旋托马斯x:FlashAttention:加速计算,节省显存, IO感知的精确注意力。
给定输入 �,�,�∈��×� ,计算得到注意力输出 �∈��×� ,过程如下:�=���⊤∈��×��������=����(�)∈��×��=�������(�������)∈��×���������=�������(�,�����)∈��×��=���������∈��×�其中, � 是softmax的缩放因子,典型的比如 1�� 。MASK操作将输入中的某些元素置为 −∞ ,计算softmax后就变成了0,其他元素保持不变;causal-lm结构和prefix-lm结构的主要差别就是MASK矩阵不同。�������(�,�)逐点作用在 � 的每个元素上,以 � 的概率将该元素置为0,以 1−� 的概率将元素置为 �1−� 。
GPU执行操作的典型方式分为三步:1. 每个kernel将输入数据从低速的HBM中加载到高速的SRAM中;2. 在SRAM中进行计算;3. 计算完毕后,将计算结果从SRAM中写入到HBM中。
为了降低对HBM的读写次数,可以通过kernel融合的方式,将多个操作融合为一个操作,在高速的SRAM中完成计算,避免反复读写HBM。但SRAM的大小有限,不可能一次性计算完整的Attention,因此必须进行分块计算,使得分块所需的内存不超过SRAM的大小。这便是tilling的思想。
矩阵乘法和逐点操作(scale,mask,dropout)的分块计算是容易实现的,难点在于softmax的分块计算,论文中对此有详细介绍,此处不赘述。
tiling分块计算使得我们可以用一个CUDA kernel来执行Attention的所有操作:从HBM中加载输入数据,在SRAM中执行所有的计算操作(矩阵乘法,mask,softmax,dropout,矩阵乘法),再将计算结果写回到HBM中。避免了反复地从HBM中读写数据。
为了后向传递计算梯度,前向计算时通常需要将某些中间结果写回到HBM中,这会产生额外的HBM读写次数,减慢运行时间。因此,Flash Attention没有为后向传递保存很大的中间结果矩阵。
在标准的Attention实现中,后向传递计算 �,�,� 的梯度时,需要用到 �×� 的中间矩阵 �,� ,但这两个矩阵并没有保存下来。这里便用到了重计算——基于保存的两个统计量,后向传递时在高速的SRAM上快速地重新计算重新计算注意力矩阵 �,� 。较之标准Attention从HBM读取很大的中间注意力矩阵的方法,尽管重计算增加了额外的计算量,却依然要快得多。
Part II. Flash Attention-2
在Flash Attention的基础上,作者提出了优化后的v2版本,速度进一步提升2倍。优化点包括:
- tweak the algorithm to reduce the number of non-matmul FLOPs
- parallelize the attention computation, even for a single head, across different thread blocks to increase occupancy
- within each thread block, distribute the work between warps to reduce communication through shared memory
1.5. Paged Attention
来自UC Berkeley的团队开源了一个项目vLLM,该项目主要用于加速LLM推理和服务。vLLM的核心,便是PagedAttention,作为一种新颖的Attention算法,它可以高效管理Attention中的key、value。无需更改任何模型架构,以PagedAttention加持的vLLM,其吞吐量比原生HF Transformers高出24倍。
如之前所述,KV Cache是加速推理的常用做法,但它存在以下问题:
- Large:对于LLaMA-13B的单个序列,它占用高达1.7GB的内存
- Dynamic:它的大小取决于序列长度,而序列长度具有高度可变和不可预测的特点;也因此,对KC Cache的高效管理面临巨大挑战,我们发现,现有系统由于碎片化和过度预留而浪费了60% - 80%的内存。
为了解决上述问题,引入了PagedAttention,这是一种受到操作系统中经典的虚拟内存和分页思想启发的Attention算法。与传统的Attention不同,PagedAttention允许将连续的key、value存储在非连续的内存空间中。具体而言,PagedAttention将每个序列的KV Cache分成多个块,每个块包含固定数量的token的key、value。在Attention计算过程中,PagedAttention Kernel高效地识别和获取这些块,采用并行的方式加速计算。
PagedAttention还有另一个关键优势:高效的内存共享。例如,在并行采样中,需要由同一Prompt生成多个输出序列,因此,Promp的计算和内存可以在输出序列之间共享。
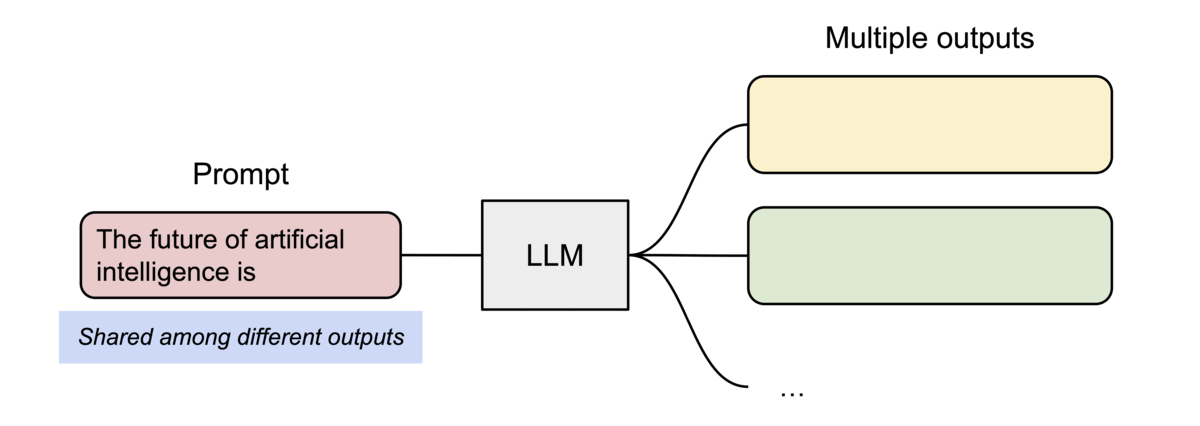
推理时,PagedAttention基于分块内存和共享内存的方式,做到了高效的内存管理,减少了内存占用,因此可以增大batch_size,提升吞吐量。
当然,除了PagedAttention外,vLLM还用了continuous batching技术,进一步提升吞吐量。
二、Norm
vanilla Transformer中用到了Layer Normalization,准确来说是Post-LN。LN的使用,是为了降低对模型初始化的要求,使得训练更加稳定。此处的改进,一类是针对“Post”,另一类是针对“LN”。
2.1. Pre-Norm
“Pre”和“Post”指的是Norm所处的位置,二者的区别如下图:(Nrom以LN为例)
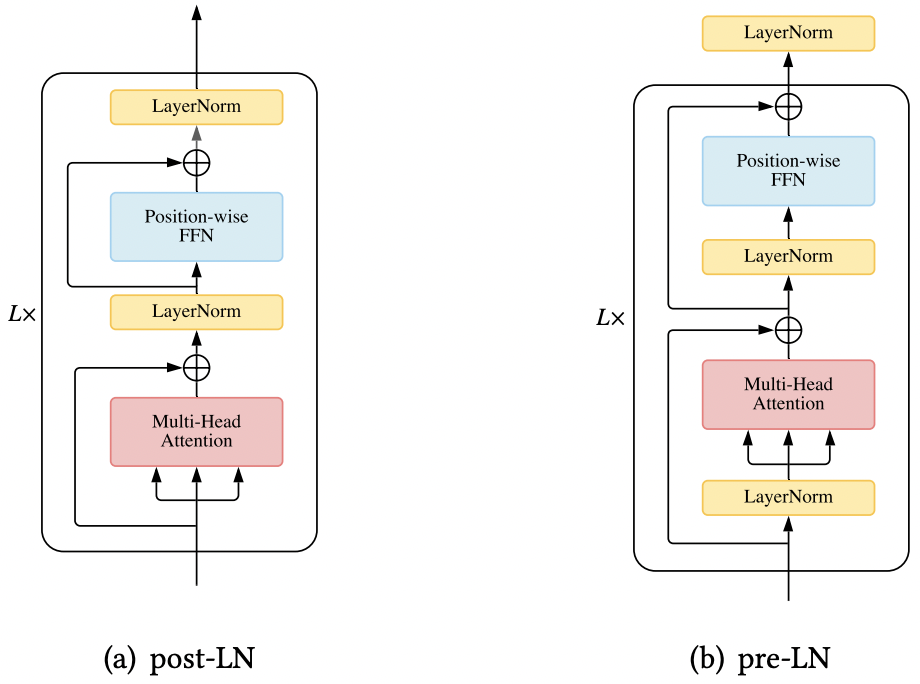
公式化如下:
���−����:��+1=��+��(����(��))����−����:��+1=����(��+��(��))有研究成果表明,Pre-Norm较之Post-Norm,更加易于训练,但在训练充分的情况下,Post-Norm能达到更好的效果。LLM由于训练难度大,因而使用Pre-Norm的较多。
2.2. RMS Norm
与一般的LN对比,RMS Norm(Root Mean Square Layer Normalization)的主要区别在于,去除了减掉均值的部分。
LN的计算公式如下:
�¯�=��−����,�=1�∑�=1���,�=1�∑�=1�(��−�)2
RMS Norm的计算公式如下:�¯�=�����(�)��,���(�)=1�∑�=1���2
按论文中的描述,RMS Norm效果可与LN等价,且计算简单速度更快。
2.3. Deep Norm
Deep Norm在Post-LN的基础上做了以下改进:
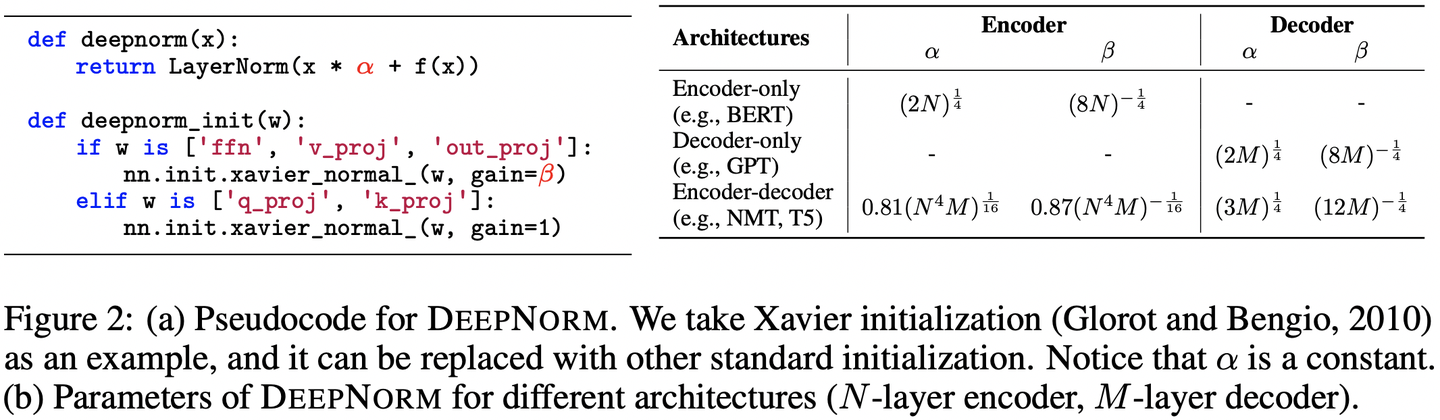
- 在进行LN之前,以参数 � 增大输入
- 在Xavier初始化过程中,以参数 � 减小部分参数的初始化范围
按论文中的描述,Deep Norm兼具Post-LN的良好性能及Pre-LN的训练稳定性,作者借此将Transformer的深度扩充到了1000层。
GLM-130B采用的便是Deep Norm。
三、Activation
激活函数用于FFN模块,vanilla Transformer采用的是ReLU,GPT采用了GeLU(关于GeLU,可参考Pikachu5808:深度学习最佳实践)。
最近的LLM,大多采用GLU(Gated Linear Units)的变体,尤其是GeGLU和SwiGLU,它们的形式如下:
���(�,�,�,�,�)=�(��+�)⊗(��+�)�����(�,�,�,�,�)=����(��+�)⊗(��+�)������(�,�,�,�,�,�)=����ℎ�(��+�)⊗(��+�)其中, ����ℎ�(�)=��(��) 。
GLU的效果更好,但是增加了额外的权重矩阵,为了保证模型整体参数量不变,一般会将FFN的中间维度降至 23⋅4�=8�3 。
四、Position Embedding
不同于CNN、RNN等模型,Self-Attention和FFN均无法捕捉token间的位置关系(permutation equivariant),因此Transformer需要位置编码。
当然,由于Decoder的Self-Attention存在mask操作,因此Decoder-only结构的Transformer是可以感知位置信息的,近来也有研究表明,移除位置编码后,语言模型任务的性能有所提升。
4.1. 绝对位置编码
vanilla Transformer采用的是sinusoidal位置编码——基于定义好的三角函数来计算编码向量:
��(���,2�)=���(���/100002�/������)��(���,2�+1)=���(���/100002�/������)
在原论文中,作者还实验了另一种可学习的位置编码:将位置编码作为可训练参数,随训练过程更新。不过,结果表明,较之sinusoidal位置编码,这种编码方式并没有带来效果的提升,而且不具备外推性,因此作者最终选定了sinusoidal位置编码。
以上两种绝对位置编码,最开始提出的使用方式都是加在token embedding上,不过,随着输入信号逐层传递,位置信息可能会在偏上层的layer中损失掉。近来有成果表示,将位置编码加在每个Transformer Layer的输入中,效果更好。
4.2. 相对位置编码
绝对位置编码,考虑的是各个独立token的位置信息;相对位置编码,考虑的则是进行Attention计算时的query、key之间的相对位置信息。由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。
相对位置编码的引入,一般会从query、key之间的向量内积展开式出发,典型的如XLNET、T5、DeBERTa都采用了各自的相对位置编码方式。
关于相对位置编码,读者可以参考让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces。
4.3. RoPE
RoPE给每个token乘上一个表达绝对位置信息的旋转矩阵,经过Attention计算后,query和key之间attention score将只与二者的相对位置有关,因此,这是一种同时融合绝对位置与相对位置的编码方式。具体细节,读者可以参考Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces。
PaLM、LLaMA采用的都是RoPE。
4.4. ALiBi
ALiBi的提出是为了提升Transformer的外推性,做到所谓的“Train Shot, Test Long”。与相对位置编码类似,ALiBi的做法是在attention score中减去一个偏置项,该偏置项与query、key之间的距离相关。与T5中采用的相对位置编码不同,ALiBi中的偏置项是预定义的,无需可训练参数。原论文显示,ALiBi比sinusoidal位置编码、RoPE、T5 bias具备更优的外推性。
BLOOM采用的便是ALiBi,并且因此提升了训练稳定性。
参考文献
[1] 为节约而生:从标准Attention到稀疏Attention - 科学空间|Scientific Spaces
[2] https://arxiv.org/pdf/2106.04554.pdf
[4] Transformer综述 - GiantPandaCV
[5] 线性Attention的探索:Attention必须有个Softmax吗? - 科学空间|Scientific Spaces
[6] https://arxiv.org/pdf/2305.13245.pdf
[7] Young:大模型推理性能优化之KV Cache解读
[9] 回旋托马斯x:FlashAttention:加速计算,节省显存, IO感知的精确注意力
[10] https://arxiv.org/pdf/2205.14135.pdf
[11] https://arxiv.org/pdf/2307.08691.pdf
[12] heyguy:记录Flash Attention2-对1在GPU并行性和计算量上的一些小优化
[13] https://vllm.ai/
[14] PagedAttention(vLLM):更快地推理你的GPT - 掘金
[15] https://arxiv.org/pdf/1910.07467.pdf
[16] 冯良骏:昇腾大模型|结构组件-1——Layer Norm、RMS Norm、Deep Norm
[17] https://arxiv.org/pdf/2203.00555.pdf
[18] 人工智能:大模型中常见的3种Norm
[19] https://arxiv.org/pdf/2002.05202.pdf
[20] 让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
[21] Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
[22] https://arxiv.org/pdf/2303.18223.pdf
[23] 让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
以上为本文的全部参考文献,对原作者表示感谢。

















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









