







Transformer自2017年由Vaswani等人提出以来,已成为深度学习领域中最重要的模型之一。它凭借其优越的并行计算能力和捕捉长程依赖的特性,广泛应用于自然语言处理(NLP)、计算机视觉(CV)、语音处理等领域。尽管Transformer表现优异,但其原始模型仍存在一些局限性,例如计算复杂度较高、对长序列的处理存在瓶颈等。为了克服这些问题,学术界和工业界提出了多种Transformer的变种和优化方法。
本文将深入探讨Transformer模型的原理及其变种与优化,分析各种优化方案的优劣,提供详细的案例,并给出实现代码,帮助读者深入理解这些变种和优化技术。
一、Transformer原理概述
1.1 Transformer的基本架构
Transformer的核心思想是自注意力机制(Self-Attention),它通过计算输入序列各个位置之间的关系来捕捉全局信息,克服了传统RNN和LSTM模型只能处理局部信息的局限。Transformer模型包括以下几个核心模块:
自注意力机制(Self-Attention):用来衡量序列中每个词与其他词之间的关系,并通过加权平均的方式产生新的表示。
多头注意力机制(Multi-Head Attention):通过并行计算多个注意力头,使模型能够在不同子空间内捕捉信息。
前馈神经网络(Feed Forward Neural Network):用于进一步处理注意力机制的输出。
位置编码(Positional Encoding):由于Transformer不依赖于循环结构,因此需要通过位置编码来引入序列的顺序信息。
自注意力机制
自注意力机制通过计算输入序列每个位置的Query(Q)、Key(K)和Value(V),来实现信息的加权求和。具体公式如下:
计算注意力权重:

计算加权平均:
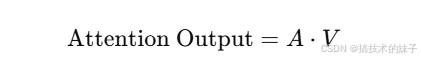
其中,V是值向量,最终输出是对各个位置的信息加权求和后的结果。
多头注意力
多头注意力机制将自注意力机制并行计算多个头,每个头关注输入序列的不同部分,最终将所有头的输出拼接起来,得到更丰富的表示。
二、Transformer的变种与优化
随着Transformer在各类任务中的应用,研究者提出了多种变种和优化方案,以提高模型的效率、表达能力和可扩展性。以下是一些重要的变种和优化方法:
2.1 Transformer的变种
2.1.1 自注意力的稀疏化:Reformer
Reformer是一种对自注意力机制进行了稀疏化的变种,它通过减少计算量来提高效率。Reformer主要的优化点包括:
局部敏感哈希(LSH):将相似的查询、键对映射到相同的桶中,从而减少计算量。
可逆层(Reversible Layers):通过使用可逆神经网络减少内存开销,不需要保存中间激活值。
Reformer的核心优势是显著减少了计算复杂度,尤其在处理长序列时效果尤为突出。
2.1.2 长序列建模:Linformer
Linformer提出了一种针对长序列的优化方法。它通过假设自注意力矩阵具有低秩结构,使用低秩近似方法来简化计算,从而减少了时间复杂度。
具体来说,Linformer通过将原始的全连接注意力矩阵转换为低秩矩阵来减少计算量,从而提高效率,尤其适用于长文本和长序列的任务。
2.1.3 结构化稀疏自注意力:Sparse Transformer
Sparse Transformer通过引入稀疏结构来优化自注意力机制,减少计算量。与Reformer类似,Sparse Transformer对自注意力机制进行了稀疏化,但采用的是不同的稀疏模式。
通过稀疏化,Sparse Transformer在处理大规模数据时,比标准的Transformer更加高效。
2.1.4 Transformer-XL
Transformer-XL(Transformer with Extra Long Context)旨在解决传统Transformer在处理长序列时出现的短期记忆问题。Transformer-XL通过引入记忆机制,使得模型能够“记住”之前的历史信息,从而增强其对长序列的建模能力。
Transformer-XL的关键在于段级递归(Segment-level Recurrence),即通过将前一段的隐藏状态作为当前段的输入,解决了传统Transformer无法处理长序列的问题。
2.2 Transformer的优化方法
2.2.1 自适应优化:AdamW
传统的Adam优化器在训练Transformer时可能会面临学习率衰减和正则化问题。AdamW是Adam的一个变种,它通过权重衰减(Weight Decay)来改进优化过程,从而减少过拟合并提高训练效率。
2.2.2 训练技巧:学习率调度与预热
Transformer模型的训练通常需要使用**学习率预热(Learning Rate Warmup)**技术。在训练初期使用较小的学习率,然后逐步增加,最后再逐步衰减。这可以帮助模型更好地收敛,避免在训练初期由于学习率过大而导致的不稳定。
2.2.3 知识蒸馏(Knowledge Distillation)
在一些应用场景中,我们可能会面临模型过大、计算开销过大的问题。此时,使用知识蒸馏技术将一个大模型的知识迁移到小模型上,可以显著减少模型大小,同时保留原模型的性能。
三、案例:优化后的Transformer在图像分类中的应用
为了展示这些变种和优化方法的实际效果,本文通过实现一个优化后的Transformer模型来解决图像分类任务。我们将使用Transformer-XL和AdamW优化器,并采用学习率调度与预热技术。
3.1 数据集准备
我们使用标准的CIFAR-10数据集,这个数据集包含10类不同的图像,每类有6000张图片,总共60000张图像。我们将其分为训练集和测试集,使用数据增强技术来提高模型的泛化能力。
3.2 模型实现
以下是优化后的Transformer模型的实现代码:
python
import torch
import torch.nn as nn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











