







 本文深入探讨了三篇经典图像分割论文:DeepLabV3、DeepLabV3+及DenseASPP。针对各算法面临的主要挑战,如细节信息损失、高分辨率图像处理等,详细介绍了其解决方案和技术革新。通过对比不同方法的特点,为读者提供了宝贵的启发。
本文深入探讨了三篇经典图像分割论文:DeepLabV3、DeepLabV3+及DenseASPP。针对各算法面临的主要挑战,如细节信息损失、高分辨率图像处理等,详细介绍了其解决方案和技术革新。通过对比不同方法的特点,为读者提供了宝贵的启发。
引言:本文选取了三篇图像分割初期的经典论文:DeepLabV3、DeepLabV3+、DenseASPP,重点关注每篇论文要解决什么问题、针对性提出什么方法、为什么这个方法能解决这个问题
DeepLabV3
文章名:《Rethinking Atrous Convolution for Semantic Image Segmentation》
论文下载:https://arxiv.org/abs/1706.05587v1
解决的问题
-
步距恒定不变的膨胀卷积会削减细节信息,导致网格化现象
-
采用大的膨胀系数时,输入图像不能过小,否则卷积后的特征图点与点之间无相关性,即3x3卷积的效果,逐渐和1x1卷积后的效果一样

思路和主要过程
-
对于第一个问题,参考HDC的做法,每一次卷积都采用不同倍率的膨胀系数,同时,每一个普通卷积都换成了膨胀卷积
例如:Block1,Block2,Block3,Block4是原始ResNet网络中的层结构,但在Block4中将第一个残差结构里的3x3卷积层以及捷径分支上的1x1卷积层步距stride由2改成了1(即不再进行下采样),并且所有残差结构里3x3的普通卷积层都换成了膨胀卷积层。Block5,Block6和Block7是额外新增的层结构,他们的结构和Block4是一模一样的,即由三个残差结构构成

-
对于第二个问题,改进ASPP模块,比如新增全局池化、双线性插值的方式进行上采样等,注意:每一个Conv和ReLu之间都有一个BN层
这里做个简单的对比:
DeepLabV2_ASPP: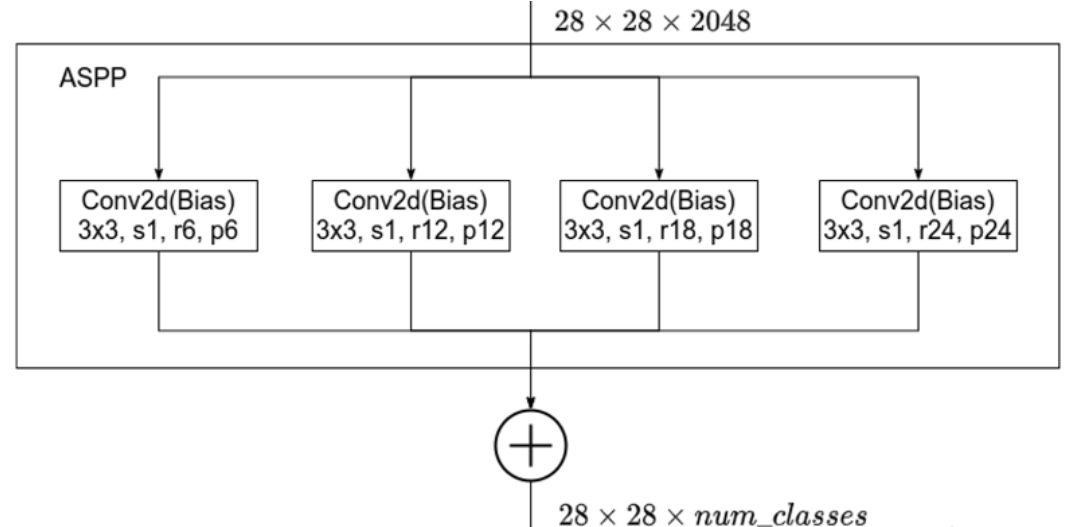
DeepLabV3_ASPP:
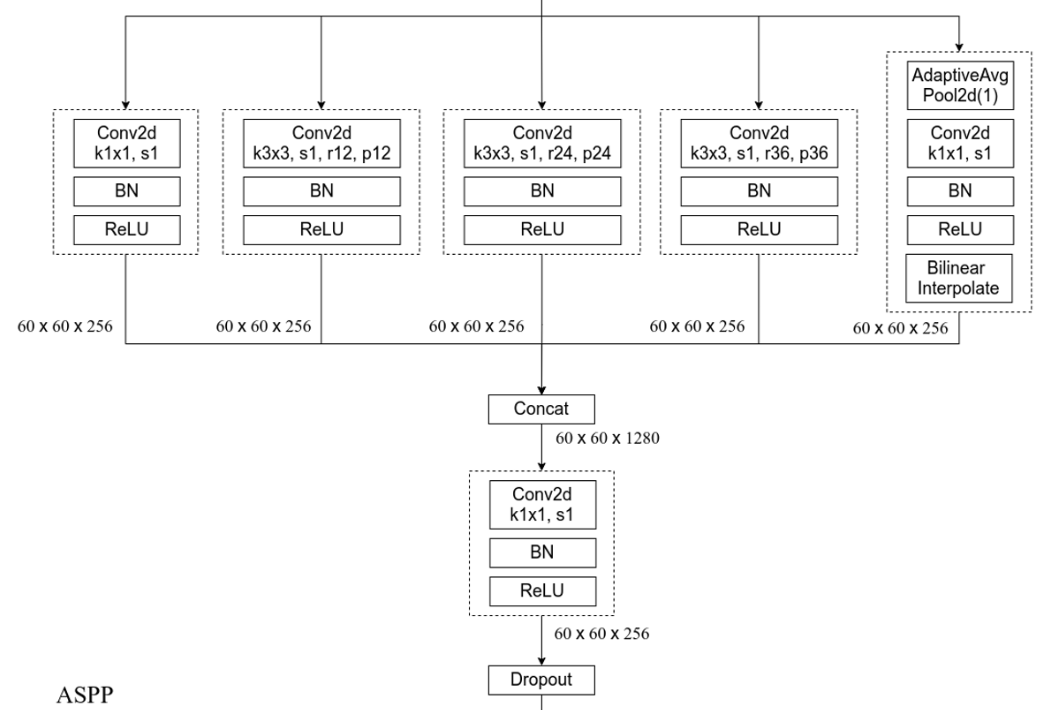

主要贡献和启发
-
使用膨胀卷积时,要采用合适的步距以达到最好的效果
如下图,不同步距对应着不同的mIOU,可见stride=8的时候效果最好

- 池化操作能获取全局信息,但不易获取细节;卷积则反之
- 没有再使用包括 CRF 在内的其他后处理手段(因为精度已经够高了😂😂😂)
DeepLabV3+

文章名:《Rethinking Atrous Convolution for Semantic Image Segmentation》
论文下载:https://arxiv.org/abs/1802.02611
官方代码:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_segmentation/deeplab_v3
解决的问题
- DeepLabV3处理后的特征图分辨率仅是原始输入图像的1/4或者1/8,造成了很大的计算量
- DeepLabV3简单地双线性上采样16倍,无法成功恢复分割对象的细节
思路和主要过程
- 针对第一个问题:如何减少计算量?
- 作者依旧采用DeepLabV3的思想,用卷积中的rate代替stride,并把DeepLabV3的输出,作为编码器的输出
- 使用带步距(stride)的DW卷积,替代池化操作,这样子不仅能利用DW卷积来减少计算量(参考MobileNet),同时也能控制输出特征的分辨率
- 针对第二个问题,如何恢复细节?
- 在网络的开始,提取浅层特征,并输入到解码器中,与后来的深层语义信息共同发挥作用
- 采用了Xception模型,并在每个DW-Conv3*3的操作后面,依次新增BN、ReLu
在深层提取的特征具有更强的语义感知能力,但由于池化和步幅卷积,失去了空间细节。
来自浅层的特征更注重细节,如强边缘。在这种情况下,这两种类型的特征的适当合作有可能提高语义分割的性能。
主要贡献和启发
- 在网络浅层提取细节特征,和深层网络提取的上下文语义信息一起作为解码器输入,构建了一个更简单有效的的编码器-解码器模块
- 可以通过膨胀卷积控制特征图的分辨率,以控制计算量
- 采用了Xception模型和DW卷积
DenseASPP
文章名:《DenseASPP for Semantic Segmentation in Street Scenes》
论文下载:https://openaccess.thecvf.com/content_cvpr_2018/papers/Yang_DenseASPP_for_Semantic_CVPR_2018_paper.pdf
官方代码:https://gitcode.net/mirrors/DeepMotionAIResearch/DenseASPP?utm_source=csdn_github_accelerator
解决的问题
自动驾驶场景中输入的图像分辨率高,所以要求更大的感受野,但同时物体的尺度变化大,所以现有的ASPP结构无法解决这两个问题
思路和主要过程

设计了一种DASPP(空洞空间卷积池化金字塔)模块
- 首先经过一个基本主干网络,得到输出,如(1)的浅蓝色部分
- 将每一次膨胀卷积后的输出,输送到后面的卷积层前
- 设置合理的膨胀率,即d<=24
- 最后将(1)和(2)的输出堆叠,最终生成语义图
主要贡献和启发
- 设计了一个DAPP模块,该模块可以使用多种不同空洞率的膨胀卷积,使网络拥有较大范围的感受野,同时不丢失检测细节的能力

上图中的DenseASPP(粉红色部分)的膨胀率有3,6,12,18,每一层的数字分别表示由对应的膨胀率的卷积组成,长度表示每一层的卷积核尺寸,很明显,每一个堆叠层的空洞卷积的密集连接能够构成更密集的特征金字塔模型,所以DenseASPP的感受野比ASPP的更大



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











