







学习卡尔曼滤波不能一蹴而就,特别是对于基础薄弱者而言,需要一步一步来,在推导kalman滤波算法之前,需要学习一些基础知识作为铺垫。
1、递归算法
卡尔曼滤波,它本质上是一种最优的递归的数字处理算法。卡尔曼滤波器的应用非常广泛,这是因为在实际的系统当中,存在许多的不确定性,主要包含以下三个方面:
① 不存在完美的数学模型
② 系统的扰动不可控,也很难建模
③ 测量传感器存在误差
例子: 找不同的人测量一个硬币的直径(测量的人不同,尺子存在误差)
 | 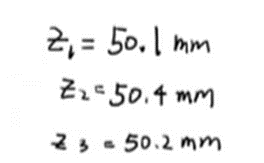 |
|---|
测量结果: z k {z_k} zk表示第k次的测量结果。
此时,如果我们要去估计真实数据 → 自然想到取平均值
数学表达如下:
x
^
k
=
1
k
(
z
1
+
z
2
+
⋯
+
z
k
)
,
x
^
k
表示第
k
次的估计值。
{\hat x_k} = {1 \over k}\left( {{z_1} + {z_2} + \cdots + {z_k}} \right),{\hat x_k}表示第k次的估计值。
x^k=k1(z1+z2+⋯+zk),x^k表示第k次的估计值。
将取平均推导成递归表达式:
x
^
k
=
1
k
(
z
1
+
z
2
+
⋯
+
z
k
−
1
)
+
1
k
z
k
=
1
k
⋅
k
−
1
k
−
1
(
z
1
+
z
2
+
⋯
+
z
k
−
1
)
+
1
k
z
k
=
k
−
1
k
⋅
1
k
−
1
(
z
1
+
z
2
+
⋯
+
z
k
−
1
)
+
1
k
z
k
=
k
−
1
k
⋅
x
^
k
−
1
+
1
k
z
k
=
x
^
k
−
1
−
1
k
x
^
k
−
1
+
1
k
z
k
\begin{aligned} {{\hat x}_k} &= \frac{1}{k}\left( {{z_1} + {z_2} + \cdots + {z_{k - 1}}} \right) + \frac{1}{k}{z_k}\\ &= \frac{1}{k} \cdot \frac{{k - 1}}{{k - 1}}\left( {{z_1} + {z_2} + \cdots + {z_{k - 1}}} \right) + \frac{1}{k}{z_k}\\ & = \frac{{k - 1}}{k} \cdot \frac{1}{{k - 1}}\left( {{z_1} + {z_2} + \cdots + {z_{k - 1}}} \right) + \frac{1}{k}{z_k}\\ & = \frac{{k - 1}}{k} \cdot {{\hat x}_{k - 1}} + \frac{1}{k}{z_k}\\ &= {{\hat x}_{k - 1}} - \frac{1}{k}{{\hat x}_{k - 1}} + \frac{1}{k}{z_k} \end{aligned}
x^k=k1(z1+z2+⋯+zk−1)+k1zk=k1⋅k−1k−1(z1+z2+⋯+zk−1)+k1zk=kk−1⋅k−11(z1+z2+⋯+zk−1)+k1zk=kk−1⋅x^k−1+k1zk=x^k−1−k1x^k−1+k1zk
整理可得:
x
^
k
=
x
^
k
−
1
+
1
k
(
z
k
−
x
^
k
−
1
)
{\hat x_k} = {\hat x_{k - 1}} + \frac{1}{k}\left( {{z_k} - {{\hat x}_{k - 1}}} \right)
x^k=x^k−1+k1(zk−x^k−1)
当k↑, 1 k → 0 \frac{1}{k} \to 0 k1→0, x ^ k → x ^ k − 1 {\hat x_k} \to {\hat x_{k - 1}} x^k→x^k−1 ,随着k增加,测量的结果 z k {z_k} zk就不重要了。
理解: 当你有了大量的数据之后,测量了很多次
对估计的结果很有信心了,所以以后的测量值就变得不那么重要了
相反,当k小, 1 k \frac{1}{k} k1大, z k {z_k} zk的作用较大。
当k↑, , ,随着k增加,测量的结果 就不重要了
理解: 当你有了大量的数据之后,测量了很多次
对估计的结果很有信心了,所以以后的测量值就变得不那么重要了
相反,当k小, 大, 的作用较大。
我们用
K
k
{K_k}
Kk来代替
1
k
\frac{1}{k}
k1,就可以得到
x
^
k
=
x
^
k
−
1
+
K
k
(
z
k
−
x
^
k
−
1
)
{\hat x_k} = {\hat x_{k - 1}} + {K_k}\left( {{z_k} - {{\hat x}_{k - 1}}} \right)
x^k=x^k−1+Kk(zk−x^k−1)
当前的估计值 = 上一次的估计值 + 系数 × (当前的测量值 – 上一次的估计值)
在Kalman滤波器里面这个 K k {K_k} Kk叫作: Kalman Gain 卡尔曼增益/因数。
观察公式 x ^ k = x ^ k − 1 + K k ( z k − x ^ k − 1 ) {\hat x_k} = {\hat x_{k - 1}} + {K_k}\left( {{z_k} - {{\hat x}_{k - 1}}} \right) x^k=x^k−1+Kk(zk−x^k−1),估计值 x ^ k {\hat x_k} x^k和上一次的估计值 x ^ k − 1 {\hat x_{k - 1}} x^k−1有关,这就是递归的思想。
下面对
K
k
{K_k}
Kk做一个简单的讨论,做一个初步的认识。
引入两个概念。
估计误差,用
e
E
S
T
{e_{EST}}
eEST表示,(
e
e
e是error误差的缩写,
E
S
T
EST
EST是estimate估计的缩写)
测量误差,用
e
M
E
A
{e_{MEA}}
eMEA表示,(
M
E
A
MEA
MEA是measurement测量的缩写)
K
k
=
e
E
S
T
k
−
1
e
E
S
T
k
−
1
+
e
M
E
A
k
{K_k} = \frac{{{e_{ES{T_{k - 1}}}}}}{{{e_{ES{T_{k - 1}}}} + {e_{ME{A_k}}}}}
Kk=eESTk−1+eMEAkeESTk−1
讨论: 在k时刻
①
e
E
S
T
k
−
1
{e_{ES{T_{k - 1}}}}
eESTk−1 >>
e
M
E
A
k
{e_{ME{A_k}}}
eMEAk ,
K
k
→
1
{K_k} \to 1
Kk→1 ,
x
^
k
=
x
^
k
−
1
+
1
⋅
(
z
k
−
x
^
k
−
1
)
=
z
k
{\hat x_k} = {\hat x_{k - 1}} + 1 \cdot \left( {{z_k} - {{\hat x}_{k - 1}}} \right) = {z_k}
x^k=x^k−1+1⋅(zk−x^k−1)=zk 。当k-1的估计误差 远大于 k次的测量误差的时候,第k的估计就很趋近于测量值。
②
e
E
S
T
k
−
1
{e_{ES{T_{k - 1}}}}
eESTk−1 <<
e
M
E
A
k
{e_{ME{A_k}}}
eMEAk,
K
k
→
0
{K_k} \to 0
Kk→0 ,
x
^
k
=
x
^
k
−
1
+
0
⋅
(
z
k
−
x
^
k
−
1
)
=
x
^
k
−
1
{\hat x_k} = {\hat x_{k - 1}} + 0 \cdot \left( {{z_k} - {{\hat x}_{k - 1}}} \right) = {\hat x_{k - 1}}
x^k=x^k−1+0⋅(zk−x^k−1)=x^k−1。当测量误差很大的时候,我们去选择更多的相信估计值。
下面用一个例子来简单体会一下上面学到的知识。
Step1 计算Kalman Gain
K
k
=
e
E
S
T
k
−
1
e
E
S
T
k
−
1
+
e
M
E
A
k
{K_k} = \frac{{{e_{ES{T_{k - 1}}}}}}{{{e_{ES{T_{k - 1}}}} + {e_{ME{A_k}}}}}
Kk=eESTk−1+eMEAkeESTk−1
Step2 计算估计值
x
^
k
=
x
^
k
−
1
+
K
k
(
z
k
−
x
^
k
−
1
)
{\hat x_k} = {\hat x_{k - 1}} + {K_k}\left( {{z_k} - {{\hat x}_{k - 1}}} \right)
x^k=x^k−1+Kk(zk−x^k−1)
Step3 更新估计误差 ,
e
E
S
T
k
=
(
1
−
K
k
)
e
E
S
T
k
−
1
{e_{ES{T_k}}} = \left( {1 - {K_k}} \right){e_{ES{T_{k - 1}}}}
eESTk=(1−Kk)eESTk−1,此部分会在后面详细推导。
有了这三步以后,开始可以应用了。
比如一个物体他实际的长度是
x
=
50
m
m
x = 50mm
x=50mm,我们第一次的估计值随便估计一个
x
^
0
=
40
m
m
{\hat x_0} = 40mm
x^0=40mm,第一次的估计误差随便给一个数字
e
E
S
T
0
=
5
m
m
{e_{ES{T_0}}} = 5mm
eEST0=5mm,假设我们的测量误差都是
e
M
E
A
=
3
m
m
{e_{MEA}} = 3mm
eMEA=3mm。
下面给出Excel的计算结果

根据上面的内容,有没有体会到递归的味道呢?
2、数据融合
假设我们用两个称去称一个东西,得到了两个结果分别是
|
z
1
=
30
g
{z_1} = 30g
z1=30g,
δ
1
=
2
g
{\delta _1} = 2g
δ1=2g标准差 z 2 = 32 g {z_2} = 32g z2=32g, δ 1 = 4 g {\delta _1} = 4g δ1=4g标准差 假设它们都不准,符合正态分布 如果我们现在需要去估算真实值 z ^ = ? \hat z = ? z^=? |  |
|---|
利用上小节学到的内容,我们进行如下估计:
z
^
=
z
1
+
k
(
z
2
−
z
1
)
\hat z = {z_1} + k\left( {{z_2} - {z_1}} \right)
z^=z1+k(z2−z1)
k
k
k为kalman gain,
k
∈
[
0
,
1
]
k \in \left[ {0,1} \right]
k∈[0,1],当
k
=
0
k = 0
k=0时,
z
^
=
z
1
\hat z = {z_1}
z^=z1,我们更相信称1的结果,当
k
=
1
k = 1
k=1时,
z
^
=
z
2
\hat z = {z_2}
z^=z2,我们更相信称2的结果。
下面来求解最优的
k
k
k,使得估计值
z
^
\hat z
z^的标准差
δ
z
^
\delta \hat z
δz^最小,标准差最小,即方差
v
a
r
(
z
^
)
{\mathop{\rm var}} \left( {\hat z} \right)
var(z^)最小(方差是标准差的平方)。
δ
z
^
2
=
v
a
r
(
z
^
)
=
v
a
r
[
z
1
+
k
(
z
2
−
z
1
)
]
=
v
a
r
[
(
1
−
k
)
z
1
+
k
z
2
]
,
两个称是相互独立的,互不影响
=
(
1
−
k
)
2
v
a
r
(
z
1
)
+
k
2
v
a
r
(
z
2
)
=
(
1
−
k
)
2
δ
1
2
+
k
2
δ
2
2
\begin{aligned} \delta _{\hat z}^2 &= {\mathop{\rm var}} \left( {\hat z} \right) = {\mathop{\rm var}} \left[ {{z_1} + k\left( {{z_2} - {z_1}} \right)} \right]\\\\ & = {\mathop{\rm var}} \left[ {\left( {1 - k} \right){z_1} + k{z_2}} \right],两个称是相互独立的,互不影响\\\\ & = {\left( {1 - k} \right)^2}{\mathop{\rm var}} \left( {{z_1}} \right) + {k^2}{\mathop{\rm var}} \left( {{z_2}} \right)\\\\ &= {\left( {1 - k} \right)^2}\delta _1^2 + {k^2}\delta _2^2 \end{aligned}
δz^2=var(z^)=var[z1+k(z2−z1)]=var[(1−k)z1+kz2],两个称是相互独立的,互不影响=(1−k)2var(z1)+k2var(z2)=(1−k)2δ12+k2δ22
要寻找一个合适的
k
k
k,使得
δ
z
^
2
\delta _{\hat z}^2
δz^2最小,那么就对
δ
z
^
2
\delta _{\hat z}^2
δz^2求
k
k
k的导数,并令其
=
0
=0
=0。
d δ z ^ 2 d k = 2 ⋅ ( − 1 ) ⋅ ( 1 − k ) δ 1 2 + 2 k δ 2 2 = 0 ⇒ k ( δ 1 2 + δ 2 2 ) = δ 1 2 ⇒ k = δ 1 2 δ 1 2 + δ 2 2 \begin{aligned} \frac{{d\delta _{\hat z}^2}}{{dk}} &= 2 \cdot \left( { - 1} \right) \cdot \left( {1 - k} \right)\delta _1^2 + 2k\delta _2^2 = 0\\\\ & \Rightarrow k\left( {\delta _1^2 + \delta _2^2} \right) = \delta _1^2 \Rightarrow k = \frac{{\delta _1^2}}{{\delta _1^2 + \delta _2^2}} \end{aligned} dkdδz^2=2⋅(−1)⋅(1−k)δ12+2kδ22=0⇒k(δ12+δ22)=δ12⇒k=δ12+δ22δ12
把实际的参数代入可得:
k
=
δ
1
2
δ
1
2
+
δ
2
2
=
2
2
2
2
+
4
2
=
0.2
,
z
^
=
z
1
+
k
(
z
2
−
z
1
)
=
30
+
0.2
(
32
−
30
)
=
30.4
g
k = \frac{{\delta _1^2}}{{\delta _1^2 + \delta _2^2}} = \frac{{{2^2}}}{{{2^2} + {4^2}}} = 0.2, \hat z = {z_1} + k\left( {{z_2} - {z_1}} \right) = 30 + 0.2\left( {32 - 30} \right) = 30.4g
k=δ12+δ22δ12=22+4222=0.2,z^=z1+k(z2−z1)=30+0.2(32−30)=30.4g
另外,估计值的标准差也可以代入计算。
δ
z
^
2
=
(
1
−
k
)
2
δ
1
2
+
k
2
δ
2
2
=
(
1
−
0.2
)
2
2
2
+
0.
2
2
4
2
=
3.2
⇒
δ
z
^
=
δ
z
^
2
=
1.79
g
\delta _{\hat z}^2 = {\left( {1 - k} \right)^2}\delta _1^2 + {k^2}\delta _2^2 = {\left( {1 - 0.2} \right)^2}{2^2} + {0.2^2}{4^2} = 3.2 \Rightarrow \delta \hat z = \sqrt[{}]{{\delta _{\hat z}^2}} = 1.79g
δz^2=(1−k)2δ12+k2δ22=(1−0.2)222+0.2242=3.2⇒δz^=δz^2=1.79g
下面分析一下上述的推导结果
δ
z
^
<
δ
z
1
\delta \hat z < \delta z_1
δz^<δz1 且
δ
z
^
<
δ
z
2
\delta \hat z < \delta z_2
δz^<δz2,说明什么? 说明利用两个不太准确的称的测量值对真实值进行估计计算,能够得到一个比两个称都更准确的结果。这个过程,就叫做数据融合。
夹带点私货: 那么如果我有三个称呢? 我先两个称融合,用结果再和第三称再融合。
在卡尔曼滤波的时候,是用模型估计 和 测量估计进行数据融合, 如果我的系统存在多个同类型传感器可以得到测量值呢,那是否可以先多个传感器先进行数据融合,然后再进行 模型估计和测量估计的数据融合呢? 如果我的系统存在多个同类型传感器和多个不同类型的传感器可得到与状态向量相关的测量值呢? 那这时候应该如何利用这些去得到一个更准确的状态估计呢? 这是后续值得进一步学习的方向。
感谢您的阅读,欢迎留言讨论、收藏、点赞、分享。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











