






作者简介:赵辉,区块链技术专家,精通各种联盟链、公链的底层原理,拥有丰富的区块链应用开发经验。
上一章我们介绍了《如何使用Transformers加载和运行预训练的模型》,实现了与GPT模型的对话和咨询功能。然而,这种原生模型的知识是有限的,它无法对一些未知内容做出准确的回答,比如最新的时事、小众的小说,以及法院档案中的案件等。通过使用Langchain,我们有可能使GPT模型能够理解文章内容并进行分析,从而弥补这一限制。
流程理解
通过阅读langchain-ChatGLM源码,知道了langchain实现本地知识库问答的大体框架,这里通过流程图进行解说:
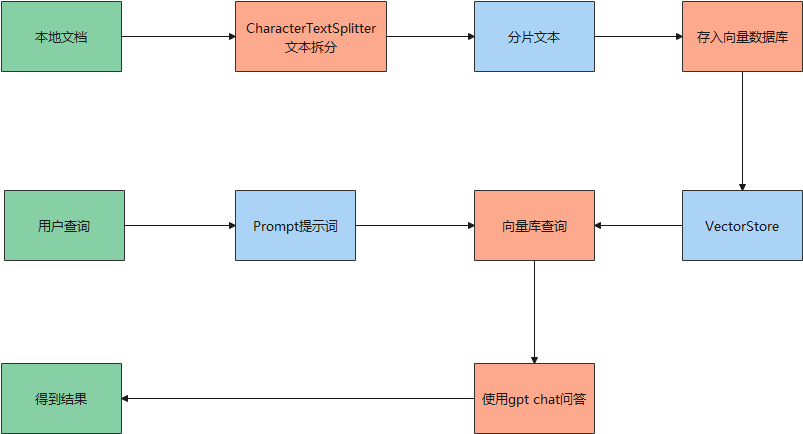
从上面的流程图可以看出,本地知识库问答实现流程如下:
通过langchain的CharacterTextSplitter对输入的文档进行拆分,得到文本分片;
将文本分片存入向量数据库VectorStore;
根据用户输入的自然语言在向量库中进行查询,得到相关分片文本;
结合预订的提示模板,以及用户查询,和文本分片,导入gpt中,进行问答;
将问答结果返回给用户。
代码实现
根据上面的流程,我对langchain-ChatGLM做了极简化,也实现了本地知识库的问答,这里输入天龙八部小说。可以对小说内容进行问答,代码(tlbb.py)如下:
from langchain.document_loaders import TextLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
import torch.cuda
import torch.backends
import torch
from transformers import AutoTokenizer, AutoModel
model_path = "/root/prj/ChatGLM-6B/THUDM/chatglm2-6b-32k"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model = model.eval()
def torch_gc():
if torch.cuda.is_available():
# with torch.cuda.device(DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
elif torch.backends.mps.is_available():
try:
from torch.mps import empty_cache
empty_cache()
except Exception as e:
print(e)
print("如果您使用的是 macOS 建议将 pytorch 版本升级至 2.0.0 或更高版本,以支持及时清理 torch 产生的内存占用。")
# 加载文档,将其分割成块,嵌入每个块并将其加载到向量存储中。
raw_documents = TextLoader('./tlbb.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=250, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
# 注意这里
embedding_device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
embeddings = HuggingFaceEmbeddings(model_name="/root/prj/ChatGLM-6B/THUDM/text2vec-large-chinese", model_kwargs={'device': embedding_device})
db = Chroma.from_documents(documents, embeddings)
history = []
while True:
query = input("question: ")
if test_text == "exit":
break;
embedding_vector = embeddings.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
#print(docs[0].page_content)
test_text = "用10个字回答" + query +":" + docs[0].page_content;
response, history = model.chat(tokenizer, test_text, history=history)
print("AI: " + response)
torch_gc()测试效果如下,可以看到还是能回答一些问题的:

代码解析
模型加载,在上一篇中就已经学习到,如何加载模型,代码如下:
model_path = "/root/prj/ChatGLM-6B/THUDM/chatglm2-6b-32k" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda() model = model.eval()文本分割,将天龙八部.txt的文本按指定长度(250)进行分割,得到分割文本集合:
raw_documents = TextLoader('./tlbb.txt').load() text_splitter = CharacterTextSplitter(chunk_size=250, chunk_overlap=0) documents = text_splitter.split_documents(raw_documents)文本嵌入向量化存储,这里使用embbedings加载text2vec-large-chinese模型执行向量化:
embedding_device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu" embeddings = HuggingFaceEmbeddings(model_name="/root/prj/ChatGLM-6B/THUDM/text2vec-large-chinese", model_kwargs={'device': embedding_device}) db = Chroma.from_documents(documents, embeddings)根据用户输入查询向量库分片数据:
embedding_vector = embeddings.embed_query(query) docs = db.similarity_search_by_vector(embedding_vector)组装prompt,像chatglm模型提问:
test_text = "用10个字回答" + query +":" + docs[0].page_content; response, history = model.chat(tokenizer, test_text, history=history) print("AI: " + response)
总结
使用Langchain-ChatGLM框架进行本地知识库问答的体验令人满意且有价值。通过该框架,GPT模型能更好地理解和回答与特定文章相关的问题,克服了原生模型在未知领域或主题上的限制。在实际测试中,我以天龙八部小说为例进行了尝试,效果尚可。
框架的流程清晰,通过分割和向量化嵌入文本,模型能理解并提取文章的关键信息。结合查询和分片文本,经过预训练模型处理后,可以获得相对准确的回答。需要注意的是,模型的回答在某些情况下可能稍有偏差,但总体而言,在理解和回答方面表现令人满意。
然而,框架的性能受实际文本质量和内容影响。对于更复杂的问题或更专业的领域,需要更精细的文本分割和知识库构建,以提升回答质量。总之,Langchain-ChatGLM为扩展GPT模型应用领域提供了一种有趣方式,使其能更好地处理不同领域和主题的问答需求。
公众号回复“Claude实战”,“ChatGPT实战”,“WPSAI实战”,获取相应的电子书。
—扩 展 阅 读—



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











