







 本文介绍了Kaggle上的一次贷款违约预测比赛,比赛目标是预测样本是否违约及其违约百分比。文章详细阐述了背景、评估指标(MAE)、数据分布、模型建立(分类和回归)及预测结果。模型使用了Logistic Regression和Gradient Boosting,通过特征选择和数据预处理提高预测精度。
本文介绍了Kaggle上的一次贷款违约预测比赛,比赛目标是预测样本是否违约及其违约百分比。文章详细阐述了背景、评估指标(MAE)、数据分布、模型建立(分类和回归)及预测结果。模型使用了Logistic Regression和Gradient Boosting,通过特征选择和数据预处理提高预测精度。
Loan default predictor
(贷款违约预测)
--- dylan at 2014-3-16
一:背景
Kaggle发布了一个涉及贷款违约预测的比赛,时间周期2个月(2014/01/17 -- 2014/03/14)。 其实,之前kaggle很久之前有过关于贷款相关信用预测的比赛。但是,这次和上次的情况很不同,挑战也更大。传统的金融相关的算法,其实是个典型二分类问题,或者说就是预测用户是否违约,在金融风险领域二分类挑战是正负样本极不平衡。本次的比赛的目标是要求参赛者预测样本是否违约以及如果违约,违约的百分比是多少。所以,本次比赛可能让参赛者能设计出色的分类模型,也要能很好设计回归模型。
二:评估指标
说到评估指标值得提一下,本次比赛的评估指标是MAE,不是以往的RMSE,金融界貌似挺喜欢MAE来作为评估指标,MAE貌似能很好评估长尾。我们知道现在很多的模型,比如linear model用的是最小二乘来优化,random forest优化的是mse等,所以,如何找到一个优化mae的模型是本次的挑战。
MAE 评估指标如下:

三:训练集和测试集数据分布
训练集大约有10w个样本,loss= 0 / loss !=0 约等于 9:1
测试集大约有20w样本。
有780个左右的特征,其实,真正有用的特征不到200个左右,很多特征之间具有很强的相关性,有些特征在所有的训练样本上值都一样,这样的特征是没有用的。
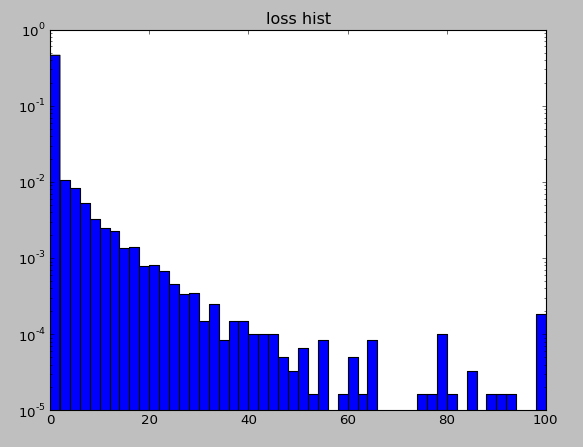
Loss值分布0-100,是数据集发布者对违约情况做了量化处理。
来看看loss分布,如Fig. 1,典型的长尾分布。如何预测长尾,同时不影响非长尾部门的预测精度是一直是学术界和工业界的难点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2460
2460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









