







二分类问题特征选择的常用两个方法
by dylanfan at 2014-6-25
(1)互信息。值越大,相关性越强
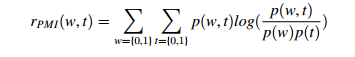
w是特征,t是目标。反应的是特征出现和不出现对目标值的影响。
(2) 卡方检验
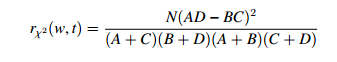
其中 A = N(w = 1, t = 1)、 B = N(w = 1, t = 0)、 C = N(w =
 本文介绍了二分类问题中常用的特征选择方法,包括互信息和卡方检验。互信息能衡量特征与目标值的相关性,值越大,相关性越强;卡方检验则用于检验特征与目标值的独立性,卡方值越大,说明特征与目标值的相关性越强,更有可能拒绝独立的原假设。
本文介绍了二分类问题中常用的特征选择方法,包括互信息和卡方检验。互信息能衡量特征与目标值的相关性,值越大,相关性越强;卡方检验则用于检验特征与目标值的独立性,卡方值越大,说明特征与目标值的相关性越强,更有可能拒绝独立的原假设。
二分类问题特征选择的常用两个方法
by dylanfan at 2014-6-25
(1)互信息。值越大,相关性越强
w是特征,t是目标。反应的是特征出现和不出现对目标值的影响。
(2) 卡方检验
其中 A = N(w = 1, t = 1)、 B = N(w = 1, t = 0)、 C = N(w =

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4196
4196





