







 OWL-QN算法是解决L1正则化损失函数优化问题的一种方法,尤其适用于处理因L1正则化导致的不可导问题。在机器学习中,L1正则化不仅能防止过拟合,还能进行特征选择。微软研究团队在ICML2007提出的OWL-QN算法,是对L-BFGS的扩展,通过限制步长象限和梯度修正来应对不可导点。该算法通过泰特展开和一阶梯度、Hessian矩阵计算来找到最小值点,其中Hessian矩阵由L-BFGS的有限存储策略近似。代码实现可参考开源资源。
OWL-QN算法是解决L1正则化损失函数优化问题的一种方法,尤其适用于处理因L1正则化导致的不可导问题。在机器学习中,L1正则化不仅能防止过拟合,还能进行特征选择。微软研究团队在ICML2007提出的OWL-QN算法,是对L-BFGS的扩展,通过限制步长象限和梯度修正来应对不可导点。该算法通过泰特展开和一阶梯度、Hessian矩阵计算来找到最小值点,其中Hessian矩阵由L-BFGS的有限存储策略近似。代码实现可参考开源资源。
在机器学习模型中,比如监督学习中,我们设计模型,我们重要的的工作是如何求解这个模型的最优值,通常是如何求救损失函数的最小值。比如logistic regression 中我们求解的是的loss function就是负log 最大似然函数。logistic regression 被广泛应用与互联网应用中,比如反欺诈,广告ctr。logistic regression是广义线性模型,优点是简单,实现容易,线上能很快响应。当数据不是呈现线性关系的时候,如果我们想应用logistic regression就得扩大特征空间,比如做非线性变换,特征组合来达到非线性模型的效果。对于非线性模型比如GDBT, Random Forest,SVM的RBF核,相对就不需要做这些特征变换,因为模型本身已经已经做了非线性工作。我认为,GBDT, Randomn Forest 这种他的非线性方法一个重要的工作就是做特征的组合,而SVM的RBF核只是单一特征变换,做了升维工作,让数据在更高维空间能被划分。在lr模型中特征过多,或者非线性模型中,极容易出现过拟合,为了尽量避免过拟合,同样的做法就是加正则方法。通常的正则方法为L1和L2。L1相对L2有个好处就是,他不仅可以避免过拟合问题,还可以起到特征选择的作用。当loss function 加L1的正则的时候,最优解会使很多不重要的特征收敛到0值,而L2只会把这些特征收敛到一个很小的值,但不是0。 我们来看下一个通用的加上L1的损失函数:
f(x) = l(x) + c||x||, 其中l(x) 是原来的可导损失函数。
现在的问题是如何求解f(x) 的最小值点。从f(x) 上来看,应为加了L1,导致在x=0点不可导,所以以往直接算梯度的方法就不可取了。Microsoft Research的人员在ICML2007提出了一种基于L-BFGS的OWL_QN算法来求解因为L1加入带来的不可导问题,具体参考(Andrew G, Gao J. Scalable training of L 1-regularized log-linear models[C]//Proceedings of the 24th international conference on Machine learning. ACM, 2007: 33-40.)。
下面是文献中把求解函数进行泰特展开,如下:
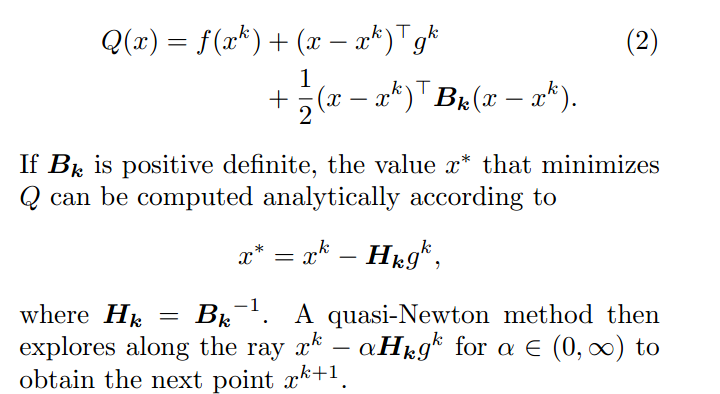
从上面看到,主要涉及到的就是一个一阶梯度,和一个Hessian矩阵。求解hessian矩阵就是这里的挑战。L-BFGS采用有限的空间,牺牲少许精度的方法来求救hession。主要涉及几个一维的向量,具体算法可参考wiki上的。
下面是wiki上关于L-BFGS的算法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









