







 本文深入探讨了LDA(Latent Dirichlet Allocation)在工程化应用中的快速采样算法,详细阐述了主题采样的Proposal Distribution,揭示了其在文本挖掘中的关键作用。
本文深入探讨了LDA(Latent Dirichlet Allocation)在工程化应用中的快速采样算法,详细阐述了主题采样的Proposal Distribution,揭示了其在文本挖掘中的关键作用。
范涛
发表于2017-04-14
LDA 是一种topic model,相信对大多数工业界研发人员来说,LDA是一种让人望而却步的东西。LDA背后的数学理论是相对复杂的,但是LDA的最终计算公式却很简单,物理意义也很好理解。在互联网行业,主题模型经常用于query语义分析,广告query-bid触发匹配等各种文本挖掘场景。现在主流搜索公司,querylog日志数量是惊人的。海量文本中如何快速进行主题模型学习,至关重要,直接影响到主题模型是否可以在工业界中应用。这里重点介绍下目前业界用的比较多的几种快速采样算法,包括Sparse LDA,Alias LDA,Light LDA(做个知识的搬运工和解说家)。
介绍快速采样算法前,先简单回顾下标准的Gibbs 采样LDA相关介绍, 采样时间复杂度是O(K),K表示主题数(不同主题有不同命中概率,需要计算累计概率归一化项):

一 Sparse LDA
主要利用LDA的稀疏特性。现实中一般文档只会包含少数若干个主题,一个词也是参与到少数几个主题中。基于这种假设,把采样概率公式进行如下分解,分成3部分(r, s, t)。其中 “r”称为 “smothing only”桶 (与文档无关) ,“s”称为“doc-topic”桶(包含文档关联主题的非0项),“t”称为“topic-word”桶(包含主题-词的非0项)。
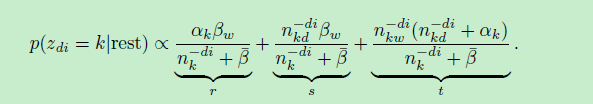
采样的时候就在r, s,t 各个桶中进行采样,采样机制如下:
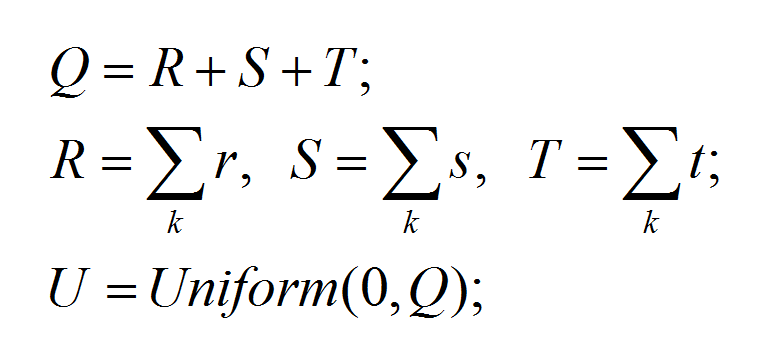
(1) 若U< T, 则在“topic-word”桶采样;(2) 若 T<=U < T+S, 则在“doc-topic”桶采样;
(3) 若U>=T+S, 则在“smothing only”桶采样;
Sparse LDA 的时间复杂度是O(Kd + Kw), 其中Kd是表示文档的主题数(稀疏),Kw表示词的主题数 (稀疏)。
二 Alias LDA
Sparse LDA利用稀疏性的特征,相对标准Gibbs LDA 提升了几十倍速度,那是否还能继续提升? 答案是肯定的。Alias LDA通过引入Alias Table 和Metropolis-Hastings 方法来进一步加快采样速度。
Alias LDA把采样概率公式进行如下分解(相对上面公式,改下公式变量名,主要是为了和论文一致):
标准Gibbs采样概率公式:
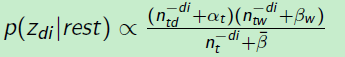
分解如下:
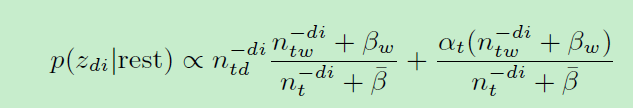
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3732
3732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









