







Deep Learning for Videos: A 2018 Guide to Action Recognition、
版权声明:本文为博主原创文章,未经博主允许不得转载 https://blog.csdn.net/heruili/article/details/89041841
视频深度学习:2018行动识别指南
医学图像,如核磁共振成像(MRIs), CTs (3D图像)非常类似于视频-他们都编码二维空间信息超过三维。就像从3D图像中诊断异常一样,从视频中进行动作识别需要从整个视频中捕捉上下文,而不仅仅是从每个帧中捕捉信息。

图1:左:头部CT扫描示例。右图:来自动作识别数据集的示例视频。CT体积中的Z维数与视频中的时间维数相似。
在这篇文章中,我总结了关于视频动作识别的文献。 该内容分为三个部分 -
1、什么是行动识别,为什么它很难
2、方法概述
3、论文摘要
Action recognition and why is it tough?
动作识别任务涉及从视频剪辑(一系列2D帧)中识别不同的动作,其中动作可以在视频的整个持续时间内执行或不执行。 这似乎是图像分类任务到多个帧的自然扩展,然后聚合来自每个帧的预测。 尽管图像分类(ImageNet)中深度学习架构的巨大成功,但视频分类和表示学习的架构进展缓慢。
What made this task tough?
1、**巨大的计算成本:**用于分类101类的简单卷积2D网络仅具有5M参数,而当膨胀到3D结构时相同的体系结构导致33M参数。 在UCF101上训练3DConvNet需要3到4天,在Sports-1M上训练大约需要两个月,这使得广泛的架构搜索变得困难并且过度拟合[1]。
2、捕获长上下文动作识别涉及捕获跨帧的时空上下文。 另外,捕获的空间信息必须补偿相机移动。 即使具有强大的空间物体检测也不够,因为运动信息也携带更精细的细节。 有一个本地和全球背景w.r.t. 需要捕获的运动信息以进行稳健的预测。 例如,考虑图2中所示的视频表示。强图像分类器可以识别两个视频中的人体,水体,但是时间周期性动作的性质区分自由泳和蛙泳。


图2:左:自由泳。 右:蛙泳。 捕捉时间运动对于区分这两个看似相似的案例至关重要。 另请注意,自由泳视频中间摄像机角度如何突然变化。
3、设计分类体系结构设计可以捕获时空信息的体系结构涉及多个选项,这些选项非常重要且评估成本高昂。 例如,一些可能的策略可能是
1、一个用于捕获时空信息的网络VS用于每个空间和时间的两个独立信息的网络
2、多个剪辑的融合预测
3、端到端训练VSseparately特征提取和分类
4、没有标准基准测试benchmark最流行和最基准的数据集长期以来一直是UCF101和Sports1M。 在Sports1M上寻找合理的架构可能非常昂贵。 对于UCF101,尽管帧数与ImageNet相当,但视频之间的高空间相关性使得训练中的实际多样性要小得多。 此外,鉴于两个数据集中的类似主题(体育),基准架构泛化到其他任务仍然是一个问题。 最近通过引入Kinetics数据集[2]解决了这个问题。

Sample illustration of UCF-101. Source.
这里必须注意的是,来自3D医学图像的异常检测不涉及这里提到的所有挑战。 医学图像的动作识别之间的主要差异如下所述
1、在医学成像的情况下,时间上下文可能不如动作识别那么重要。 例如,检测头部CT扫描中的出血可能涉及跨切片的更少的时间背景。 可以仅从单个切片检测颅内出血。 与此相反,从胸部CT扫描中检测肺结节将涉及捕获时间背景,因为结节以及支气管和血管在2D扫描中看起来都像圆形物体。 只有在捕获3D上下文时,结节才能被视为球形物体,而不是像船只这样的圆柱形物体
2、在动作识别的情况下,大多数研究思路都采用预训练的2D CNN作为获得极大更好收敛的起点。 在医学图像的情况下,这种预训练的网络将不可用。
Overview of approaches
在深度学习出现之前,大多数用于动作识别的传统CV算法变体可以分为以下3个大步骤:
1、描述视频区域的局部高维视觉特征被密集地提取[3]或在稀疏的兴趣点集[4,5]。
2、提取的特征被组合成固定大小的视频级描述。 该步骤的一个流行变体是用于在视频级编码特征的视觉单词包(bag of visual words )(使用分层或k均值聚类导出)。
3、分类器(如SVM或RF)在视觉词语包上进行训练以进行最终预测
在步骤1中使用浅手工制作特征的这些算法中,使用密集采样轨迹特征的改进密集轨迹[6](iDT)是最先进的。 同时,3D卷积被用作在2013年是动作识别没有太大的帮助[7]。 在2014年之后不久,发布了两篇突破性的研究论文,这些论文构成了我们将在本文中讨论的所有论文的支柱(backbone)。 它们之间的主要区别在于结合时空信息的设计选择。
Approach 1: Single Stream Network
在这项工作[2014年6月](Large-scale Video Classification with Convolutional Neural Networks),作者 - 卡尔帕西等人。 - 探索使用2D预训练卷积融合连续帧的时间信息的多种方法。

从图3中可以看出,视频的连续帧在所有设置中被表示为输入。 单帧使用单一架构,在最后阶段融合所有帧的信息。 后期融合(Late fusion )使用共享参数的两个网络,间隔15帧,并在最后融预测。 早期融合(Early fusion)通过卷积超过10帧在第一层中结合。 慢融合(Slow fusion)涉及多个阶段的融合,早期和晚期融合之间的平衡。 对于最终预测,从整个视频中采样多个剪辑,并且对它们的预测分数进行平均以进行最终预测。
尽管进行了大量实验,但作者发现,与最先进的手工制作的基于特征的算法相比,结果显着更差。 造成这种失败的原因有很多:
1、学习的时空特征没有捕捉运动特征
2、数据集不那么多样化,学习这些详细的功能很难
Approach 2: Two Stream Networks
在Simmoyan和Zisserman的这项开创性工作[2014年6月](Two-Stream Convolutional Networks for Action Recognition in Videos)中,作者以Karpathy等人之前的工作失败为基础。 鉴于深层架构学习运动特征的坚韧性,作者明确地以堆叠光流向量的形式建模运动特征。 因此,该架构不是用于空间上下文的单一网络,而是具有两个独立的网络 - 一个用于空间上下文(预训练),一个用于运动上下文。 空间网络的输入是视频的单个帧。 作者对时间网的输入进行了实验,发现在10个连续帧中堆叠的双向光流表现最佳。 分别训练两个流并使用SVM组合。 最终预测与先前的论文相同,即对采样帧进行平均。

虽然这种方法通过明确捕获局部时间运动来改善单流方法的性能,但仍存在一些缺点:
1、由于视频水平预测是通过对采样剪辑进行平均预测获得的,因此学习特征中仍然缺少长距离时间信息。
2、 由于训练片段是从视频中均匀地采样的,因此它们存在错误的标签分配问题。 假设每个剪辑的基本事实与视频的基本事实相同,如果该动作仅在整个视频中发生一小段时间,则可能不是这种情况。
3、该方法涉及预先计算光流向量并分别存储它们。 此外,对两个流的训练是分开的,这意味着移动中的端到端训练仍然是一条漫长的道路。
Summaries
以下文件是两篇论文(单流和两流)的演变,总结如下:

围绕这些论文的经常性主题可归纳如下。 所有论文都是基于这些基本思想的即兴创作。

对于每篇论文,我都列出了他们的主要贡献并对其进行了解释。 我还在UCF101-split1上展示了他们的基准分数。
LRCN
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
Donahue et al.
Submitted on 17 November 2014
Arxiv Link
Key Contributions:
1、以先前的工作为基础,使用RNN而不是基于流的设计
2、用于视频表示的编码器 - 解码器架构的扩展
3、提出用于动作识别的端到端可训练架构
Explanation:
在Ng等[9]的前期着作中。 作者探讨了在单独训练的特征图上使用LSTM的想法,看它是否可以从剪辑中捕获时间信息。 遗憾的是,他们得出的结论是,经过训练的特征映射后,卷积特征的时间池化证明比堆积的LSTM更有效。 在本文中,作者建立了在卷积块(编码器)之后使用LSTM块(解码器)但使用整个架构的端到端训练的相同想法。 他们还将RGB和光流作为输入选择进行比较,发现基于两种输入的预测加权评分最佳。

Algorithm:
在训练期间,从视频中采样16个帧剪辑。 该架构以端到端的方式进行训练,输入为RGB或16帧剪辑的光流。 每个剪辑的最终预测是每个时间步长的预测平均值。 视频级别的最终预测是每个剪辑的预测平均值。
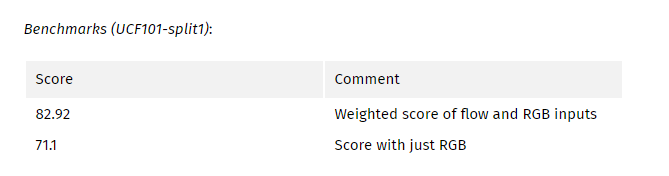
My comments:
尽管作者提出了端到端的训练框架,但仍存在一些缺点
1、错误标签分配当视频被分解为剪辑
2、无法捕获长距离时间信息
3、使用光流意味着单独预先计算流动特征
Varol等人。 他们的工作[10]试图通过使用较低的视频空间分辨率和较长的剪辑(60帧)来弥补迟缓的时间范围问题,从而显著提高性能。
C3D
Learning Spatiotemporal Features with 3D Convolutional Networks
Du Tran et al.
Submitted on 02 December 2014
Arxiv Link
Key Contributions:
1、将3D卷积网络重新用作特征提取器
2、广泛搜索最佳3D卷积内核和架构
3、使用反卷积层来解释模型决策
Explanation:
在这项工作中,作者以Karpathy等人的工作为基础。 然而,他们不是在帧上使用2D卷积,而是在视频卷上使用3D卷积。 我们的想法是在Sports1M上训练这些庞大的网络,然后将它们(或具有不同时间深度的网络集合)用作其他数据集的特征提取器。 他们的发现是一个简单的线性分类器,如SVM,在提取特征的集合之上比她最先进的(state of the art)算法更好。 如果另外使用像iDT这样的手工制作的功能,该模型的表现会更好。
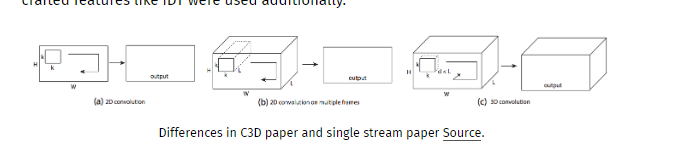
这项工作的另一个有趣的部分是使用解卷积层(deconvolutional)(在此解释)来解释决策。 他们的发现是,网络在前几帧主要集中于空间外观上,并在后续帧中跟踪运动。
Algorithm:
在训练期间,为每个视频提取五个随机的2秒剪辑,其中ground truth实况作为整个视频中报告的行为。 在测试时间中,随机采样10个剪辑,并对它们之间的预测进行平均以进行最终预测。

三维卷积,其中卷积应用于时空立方体。

My comments:
远程时间建模仍然是一个问题。 此外,训练如此庞大的网络在计算上是一个问题 - 特别是对于医学成像,其中自然图像的预训练没有太大帮助。
注意:大约在同一时间Sun等人[11] 介绍了分解三维卷积网络(FSTCN)的概念,作者探讨了将三维卷积分解为空间二维卷积,然后是时间一维卷积的想法。 放置在2D转换层之后的1D卷积被实现为时间和信道维度上的2D卷积。 分解的3D卷积(FSTCN)在UCF101分割上具有可比较的结果。

FSTCN论文和3D卷积源的分解。
Conv3D & Attention
Describing Videos by Exploiting Temporal Structure
Yao et al.
Submitted on 25 April 2015
Arxiv Link
Key Contributions:
1、新颖的3D CNN-RNN编码器 - 解码器架构,其捕获本地时空信息
2、在CNN-RNN编码器 - 解码器框架内使用注意机制来捕获全局上下文
Explanation:
虽然这项工作与行动识别没有直接关系,但在视频表现方面却是一项具有里程碑意义的工作。 在本文中,作者使用3D CNN + LSTM作为视频描述任务的基础架构。 在基础之上,作者使用预先训练的3D CNN来改善结果。
Algorithm:
该设置与LRCN中描述的编码器 - 解码器架构几乎相同,但有两个不同之处
1、不是将特征从3D CNN传递到LSTM,而是将剪辑的3D CNN特征映射与用于同一组帧的堆叠2D特征映射连接,以丰富每个帧i的表示{v1,v2,…,vn}。 注意:使用的2D和3D CNN是经过预先训练的,并且没有像LRCN那样经过端到端的培训
2、不是对所有帧中的时间向量求平均,而是使用加权平均来组合时间特征。 注意权重是根据每个时间步的LSTM输出决定的。

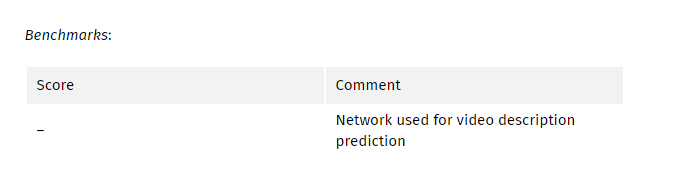
My comments:
这是2015年首次为视频表现引入关注机制的具有里程碑意义的工作之一。
TwoStreamFusion
Convolutional Two-Stream Network Fusion for Video Action Recognition
Feichtenhofer et al. Submitted on 22 April 2016 Arxiv Link
Key Contributions:
1、通过更好的远程损失进行长距离时间建模
2、新颖的多层融合架构
Explanation:
在这项工作中,作者使用基本两流结构和两种新方法,并演示了性能增量,而不会显着增加参数的大小。 作者探讨了两个主要观点的功效。
1、空间和时间流的融合(如何和何时) - 对于区分洗头和刷牙的任务 - 空间网可以捕捉视频中的空间依赖性(是否它是头发或牙齿),而时间网可以捕获周期性运动的存在 视频中的每个空间位置。 因此,将与特定面部区域有关的空间特征图映射到对应区域的时间特征图是重要的。 为了实现相同的目标,网络需要在早期级别融合,使得在相同像素位置处的响应被对应而不是在末端融合(如在基本双流体系结构中)。
2、在时间帧上组合时序网络输出,以便对长期依赖性进行建模。
Algorithm:
除了双流体系结构之外的所有东西都几乎相似
1、如下图所示,来自两个流的conv_5层的输出通过conv + pool融合。 最后一层还有另一种融合。 最终的融合输出用于时空损失评估。

2、对于时间融合,来自时间网络的输出,跨时间堆叠,通过conv +pooling 合并融合用于时间损失

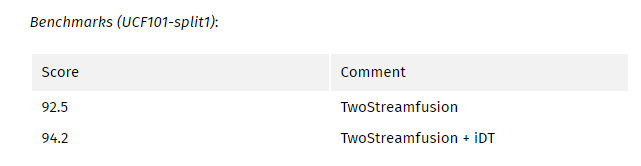
My comments:
作者建立了TwoStreamFusion方法的至高无上,因为它提高了C3D的性能,而没有C3D中使用的额外参数。
TSN
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
Wang et al.
Submitted on 02 August 2016
Arxiv Link
Key Contributions:
1、针对远程时间建模的有效解决方案
2、建立batch normalization, dropout 和预训练的使用是良好做法
Explanation:
在这项工作中,作者改进了双流体系结构,以产生最先进的结果。 与原始论文有两个主要差异
1、他们提议在视频中稀疏地对剪辑进行采样,以更好地模拟长距离时间信号,而不是整个视频的随机采样。
2、对于视频级别的最终预测,作者探索了多种策略。 最好的策略是
1、通过对片段进行平均,分别组合时间和空间流的分数(以及涉及其他输入模式的其他流)
2、使用加权平均值并在所有类别上应用softmax来融合最终时间和时间分数的得分。
这项工作的另一个重要部分是建立过拟合的问题(由于数据集规模较小),并展示了现在流行技术的使用,如batch normalization, dropout 和预训练,以对抗相同的问题。 作者还评估了两种新的输入模态,作为光流的替代 - 即warped光流和RGB差异。
Algorithm:
在训练和预测期间,视频被分成具有相等持续时间的K个片段。 此后,从每个K段中随机采样片段。 其余步骤仍然类似于双流体系结构,如上所述进行了更改。

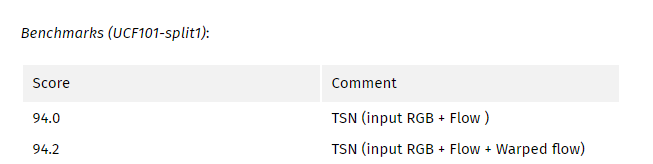
My comments:
这项工作试图解决行动识别中的两大挑战 - 由于尺寸小而过度拟合以及和长距离建模,结果非常强大。 然而,预先计算光流和相关输入模态的问题仍然是一个大问题。
ActionVLAD
ActionVLAD: Learning spatio-temporal aggregation for action
classification Girdhar et al. Submitted on 10 April 2017 Arxiv Link
Key Contributions:
在这项工作中,作者最显着的贡献是使用可学习特征聚合(VLAD)与使用maxpool或avgpool的正常聚合相比。 聚合技术类似于视觉词汇bag。 存在多个学习的锚点(例如c1,… ck)基于表示k个典型动作(或子动作)相关的时空特征的词汇表。 来自两个流体系结构中的每个流的输出根据k空间“动作词”特征进行编码 - 对于任何给定的空间或时间位置,每个特征是对应锚点的输出的差异。

平均或最大池化表示点的整个分布,因为只有单个描述符,其对于表示由多个子动作组成的整个视频而言可能是次优的。 相反,所提出的视频聚合通过将描述符空间划分为k个单元并在每个单元内汇集来表示具有多个子动作的描述符的整个分布。

虽然最大或平均池对于类似的功能是好的,但它们并不能充分捕获功能的完整分布。 ActionVlAD对外观和运动特征进行聚类,并从最近的聚类中心聚合其残差。
Algorithm:
除了使用ActionVLAD层之外,双流体系结构中的所有内容都几乎相似。 作者试验多层以将ActionVLAD层与后期融合放置在conv层之后作为最佳策略。
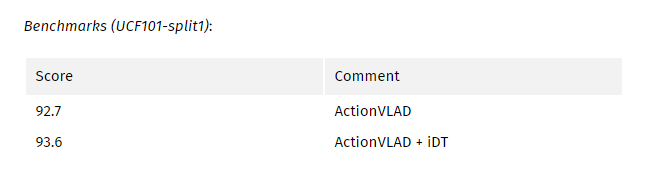
My comments:
使用VLAD作为一种有效的pooling方式已经证明很久以前了。 在端到端的可训练框架中对其进行扩展,使得该技术在2017年初的大多数动作识别任务中具有极强的性能和最先进的技术。
HiddenTwoStream
Hidden Two-Stream Convolutional Networks for Action Recognition
Zhu et al.
Submitted on 2 April 2017
Arxiv Link
Key Contributions:
用于使用单独网络即时生成光流输入的新型架构
Explanation:
在双流体系结构中使用光流使得必须预先计算每个采样帧之前的光流,从而不利地影响存储和速度。 本文提倡使用无监督架构来为一堆帧生成光流。
光流可以被视为图像重建问题。 给定一对相邻的帧I1和I2作为输入,我们的CNN生成流场V.然后使用预测的流场V和I2,I1可以使用逆扭曲重建为I1’,使得I1与其重建之间的差异最小化。
Algorithm:
作者探索了多种策略和体系结构,以生成具有最大fps和最小参数的光流,而不会对精度造成太大影响。 最终的体系结构与双流体系结构相同,如上所述进行了更改:
1、 时间流现在具有堆叠在一般时间流架构顶部的光流生成网(MotionNet)。 对时间流的输入现在是后续帧而不是预处理光流。
2、对于无监督的MotionNet培训,还有一个额外的多级损失
作者还证明了使用基于TSN的融合而不是传统架构的双流方法的性能改进。

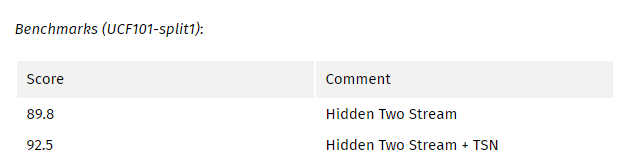
My comments:
该论文的主要贡献是提高速度和相关的预测成本。 通过自动生成流,作者减轻了对较慢的传统方法的依赖,以产生光流。
I3D
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Carreira et al.
Submitted on 22 May 2017
Arxiv Link
Key Contributions:
1、将基于3D的模型结合到利用预训练的双流体系结构中
2、用于未来基准测试和改进动作数据集多样性的Kinetics数据集
Explanation:
本文从C3D离开的地方开始。 作者不是使用单个3D网络,而是在双流体系结构中为两个流使用两个不同的3D网络。 此外,为了利用预训练的2D模型,作者在第三维中重复2D预训练的权重。 现在,空间流输入包括按时间维度堆叠的帧,而不是基本的双流体系结构中的单帧。
Algorithm:
与基本的两个流体系结构相同,但每个流都有3D网络
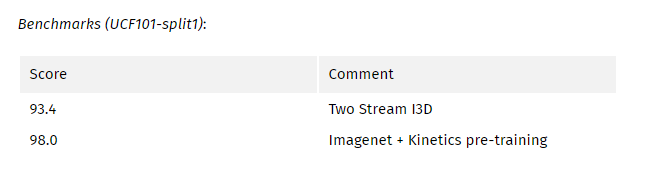
My comments:
该论文的主要贡献在于证明了使用预训练的2D网络带来的好处。 Kinetic数据集是本文开源的,是本文的另一个重要贡献。
T3D
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
Diba et al.
Submitted on 22 Nov 2017
Arxiv Link
Key Contributions:
1、用于跨越可变深度的结合时间信息的架构
2、新型培训架构和技术,用于监督2D预训网与3D网之间的转移学习
Explanation:
作者扩展了在I3D上完成的工作,但建议使用基于3D DenseNet的单流体系结构,在密集块之后堆叠多深度时间池化层(时间过渡层)以捕获不同的时间深度。多深度池化是通过池化不同的时间尺寸的内核来实现的。

除此之外,作者还设计了一种新的技术,用于监督预训练的2D卷积网和T3D之间的转移学习。 2D预训练网和T3D都是来自视频的帧和剪辑,其中剪辑和视频可以来自相同的视频。 该架构被训练基于相同的预测0/1,并且来自预测的误差通过T3D网络反向传播,以便有效地传递知识。

Algorithm:
该架构基本上是对DenseNet [12]的3D修改,增加了可变时间池化。

My comments:
尽管结果并未改善I3D结果,但与I3D相比,这主要归因于更低的模型占地面积。 本文最新颖的贡献是有监督的转移学习技术。
References
1、ConvNet Architecture Search for Spatiotemporal Feature Learning by Du Tran et al.
2、Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
3、Action recognition by dense trajectories by Wang et. al.
4、On space-time interest points by Laptev
5、Behavior recognition via sparse spatio-temporal features by Dollar et al
6、Action Recognition with Improved Trajectories by Wang et al.
7、3D Convolutional Neural Networks for Human Action Recognition by Ji et al.
8、Large-scale Video Classification with Convolutional Neural Networks by Karpathy et al.
9、Beyond Short Snippets: Deep Networks for Video Classification by Ng et al.
10、Long-term Temporal Convolutions for Action Recognition by Varol et al.
11、Human Action Recognition using Factorized Spatio-Temporal Convolutional Networks by Sun et al.
12、Densely Connected Convolutional Networks by Huang et al.















 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









