







Fangcheng Fu, Jiawei Jiang, Yingxia Shao, Bin Cui
Peking University, Beijing University of Posts and Telecommunications, Tencent
VLDB 2019
https://arxiv.org/pdf/1907.01882.pdf
GBDT是一种广泛应用的机器学习算法,该算法不仅广泛应用于数据分析竞赛中,而且在工业界也广泛应用。由于数据量的快速增长,部分研究人员试图利用分布式来训练GBDT,进而支撑大规模工作负载。
然而,现有系统在管理训练数据方面方式各异,而且他们都未曾研究数据管理所带来的影响。这篇文章旨在研究多种数据管理方法的优劣,并对这些分布式GBDT的性能进行比较。
这篇文章基于数据分区和数据存储对数据管理策略进行了象限划分。然后进行深度系统分析,并对各个象限的适用场景进行总结。基于以上分析,这篇文章提出一种新的分布式GBDT系统,名曰Vero,该系统采用了纵向分区和行式存储,这种组合适用于很多大规模数据的情景。
为了验证本文的分析,作者们基于同样代码实现了多个象限,并且在大量工作负载下对比了这些象限,最终在多个数据集上将Vero跟其他STOA系统进行对比。
根据本文的理论分析和实验结果,在给定工作负载的前提下,可以对如何选择适当的数据管理方式进行指导。
上面所提到的纵向分区即为基于特征的类别对数据进行列式分区,而横向分区即为按样本进行分区。而所谓行式存储即为以(特征下标, 特征值)对的方式进行存储,即Compressed Sparse Row (CSR) 格式,而列式存储即为以(样本下标, 特征值)对的方式进行存储,即Compressed Sparse Column (CSC)格式。
几种方法对应的象限如下
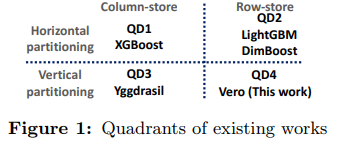
XGBoost是横向分区,列式存储的,即按样本进行分区,并且每个样本的所有特征存在一起; LightGBM和DimBoost是横向分区,行式存储的,即按样本进行分区,并且每个样本的特征是按(特征下标,特征值)对存储的,并不是一个样本的所有特征都在一个分区;Yggdrasil是纵向分区,列式存储的,即按特征进行分区,并且样本的同一个特征存在一起
GBDT结构图示如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









