







 An Embedding Learning Framework for Numerical Features inCTR PredictionHuifeng Guo, Bo Chen, ...
An Embedding Learning Framework for Numerical Features inCTR PredictionHuifeng Guo, Bo Chen, ...
An Embedding Learning Framework for Numerical Features in CTR Prediction
Huifeng Guo, Bo Chen, Ruiming Tang, Weinan Zhang, Zhenguo Li, Xiuqiang He
Huawei Noah’s Ark Lab, Shanghai Jiao Tong University
https://arxiv.org/pdf/2012.08986.pdf
工业界推荐系统中,CTR预估非常重要,很多深层CTR模型都遵循embedding和特征交互的范式。但是,大多数模型都集中在设计网络结构来更好的对特征交互进行建模。而对于特征embedding模块,尤其是数值型特征,被忽略了。
现有针对数值特征的处理方法很难捕获有效信息,这是因为现有方法信息容量比较小,基于离线专家特征工程很难离散化。这篇文章针对CTR预估,提出一种新的针对数值特征的embedding学习框架,AutoDis,该框架模型容量更大,而且可以以端到端的形式训练,同时还可以保留唯一的表示属性。
AutoDis包含三个核心部分,元embedding,自动离散化以及聚合算法。具体而言,针对每一个数值域提出元embedding,可以利用可控范围的参数来学习域的全局知识。然后,可微分自动离散算法可以对数值特征软离散化,并且可以捕获数值特征和元embedding的相关性。最后,通过聚合函数,可以学到特有并且富含信息的embedding。
两个公开数据集和一个工业界数据集上的大量实验表明了AutoDis的有效性。AutoDis已经部署到主广告平台,在线A/B测试结果相对基准模型CTR提升2.1%,eCPM提升2.7%。此外,该框架已经在MindSpore开源。
目前工业界主流CTR预估模型,主要有以下几个

主流CTR预估框架图示如下
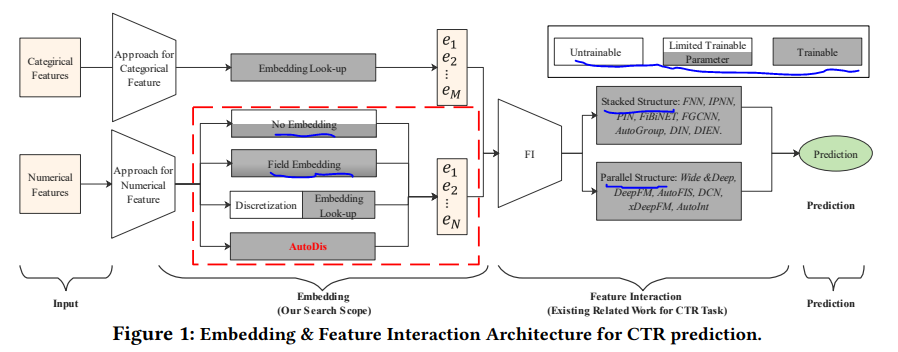
大部分类别型特征可以直接embedding,但是数值型特征进行embedding时比较麻烦


现有针对数值型特征的处理办法,可以分为以下三类,各类方法简介及对比如下

作者们所提出的AutoDis简介及优势如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









