







 本文深入探讨了CNN在无人驾驶技术中的应用,包括3D感知(如MC-CNN和FlowNet)和物体检测(如Faster R-CNN、MS-CNN和SSD)。这些网络在提高无人驾驶感知的准确性和效率方面发挥了重要作用。
本文深入探讨了CNN在无人驾驶技术中的应用,包括3D感知(如MC-CNN和FlowNet)和物体检测(如Faster R-CNN、MS-CNN和SSD)。这些网络在提高无人驾驶感知的准确性和效率方面发挥了重要作用。
作者:吴双,王江,刘少山
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
无人驾驶的感知部分作为计算机视觉的领域范围,也不可避免地成为CNN发挥作用的舞台。本文是无人驾驶技术系列的第八篇,深入介绍CNN(卷积神经网络)在无人驾驶3D感知与物体检测中的应用。
CNN简介
卷积神经网络(Convolutional Neural Network,CNN)是一种适合使用在连续值输入信号上的深度神经网络,比如声音、图像和视频。它的历史可以回溯到1968年,Hubel和Wiesel在动物视觉皮层细胞中发现的对输入图案的方向选择性和平移不变性,这个工作为他们赢得了诺贝尔奖。时间推进到上世纪80年代,随着神经网络研究的深入,研究人员发现对图片输入做卷积操作和生物视觉中的神经元接受局部receptive field内的输入有相似性,那么在神经网络中加上卷积操作也就成了自然的事情。当前的CNN相比通常的深度神经网络(DNN),特点主要包括:
- 一个高层的神经元只接受某些低层神经元的输入,这些低层神经元处于二维空间中的一个邻域,通常是一个矩形。这个特点受到生物神经网络中receptive field的概念启发。
- 同一层中不同神经元的输入权重共享,这个特点可以认为是利用了视觉输入中的平移不变性,不光大幅度减少了CNN模型的参数数量,还加快了训练速度。
由于CNN在神经网络的结构上针对视觉输入本身特点做的特定设计,所以它是计算机视觉领域使用深度神经网络的不二选择。在2012年,CNN一举打破了ImageNet这个图像识别竞赛的世界纪录之后,计算机视觉领域发生了天翻地覆的变化,各种视觉任务都放弃了传统方法,启用了CNN来构建新的模型。无人驾驶的感知部分作为计算机视觉的领域范围,也不可避免地成为CNN发挥作用的舞台。
无人驾驶双目3D感知
在无人车感知中,对周围环境的3D建模是重中之重。激光雷达能提供高精度的3D点云,但密集的3D信息就需要摄像头的帮助了。人类用两只眼睛获得立体的视觉感受,同样的道理能让双目摄像头提供3D信息。假设两个摄像头间距为B,空间中一点P到两个摄像头所成图像上的偏移(disparity)为d,摄像头的焦距为f,那么我们可以计算P点到摄像头的距离为:
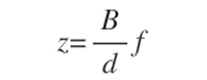
所以为了感知3D环境得到z,需要通过双目摄像头的两张图像I_l和I_r得到d,通常的做法都是基于局部的图片匹配:
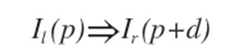
由于单个像素的值可能不稳定,所以需要利用周围的像素和平滑性假设d(x,y)≈d(x+α,y+β)(假设α和β都较小),所以求解d变成了一个最小化问题:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









