







 本文详细介绍了细粒度图像分析,包括细粒度图像分类和检索的经典问题。作者探讨了强监督信息和弱监督信息在细粒度图像分类中的应用,如Part-based R-CNN、Pose Normalized CNN和Mask-CNN模型。此外,还讨论了弱监督的Two Level Attention Model、Constellations和Bilinear CNN模型。在细粒度图像检索方面,提出了SCDA方法,该方法在无监督条件下进行物体定位和卷积特征选择。文章最后展望了细粒度图像分析领域的未来方向。
本文详细介绍了细粒度图像分析,包括细粒度图像分类和检索的经典问题。作者探讨了强监督信息和弱监督信息在细粒度图像分类中的应用,如Part-based R-CNN、Pose Normalized CNN和Mask-CNN模型。此外,还讨论了弱监督的Two Level Attention Model、Constellations和Bilinear CNN模型。在细粒度图像检索方面,提出了SCDA方法,该方法在无监督条件下进行物体定位和卷积特征选择。文章最后展望了细粒度图像分析领域的未来方向。
作者简介:魏秀参,南京大学计算机系机器学习与数据挖掘所(LAMDA)博士生,专攻计算机视觉和机器学习。曾在国际顶级期刊和会议发表多篇学术论文,并两次获得国际计算机视觉相关竞赛冠亚军。
责编:何永灿,欢迎人工智能领域技术投稿、约稿、给文章纠错,请发送邮件至heyc@csdn.net
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
有别于通用图像分析任务,细粒度图像分析的所属类别和粒度更为精细,它不仅能在更细分的类别下对物体进行识别,就连相似度极高的同一物种也能区别开来。本文将分别围绕“细粒度图像分类”和“细粒度图像检索”两大经典图像问题来展开,从而使读者对细粒度图像分析领域有全面的理解。
大家应该都会有这样的经历:逛街时看到路人的萌犬可爱至极,可仅知是“犬”殊不知其具体品种;初春踏青,见那姹紫嫣红丛中笑,却桃杏李傻傻分不清……实际上,类似的问题在实际生活中屡见不鲜。如此问题为何难?究其原因,是普通人未受过针对此类任务的专门训练。倘若踏青时有位资深植物学家相随,不要说桃杏李花,就连差别甚微的青青河边草想必都能分得清白。为了让普通人也能轻松达到“专家水平”,人工智能的研究者们希望借助计算机视觉技术(Computer Vision,CV)来解决这一问题。如上所述的这类任务在CV研究中有个专门的研究方向,即“细粒度图像分析”(Fine-Grained Image Analysis)。
细粒度图像分析任务相对通用图像(General/Generic Images)任务的区别和难点在于其图像所属类别的粒度更为精细。以图1为例,通用图像分类其任务诉求是将“袋鼠”和“狗”这两个物体大类(蓝色框和红色框中物体)分开,可见无论从样貌、形态等方面,二者还是很容易被区分的;而细粒度图像的分类任务则要求对“狗”该类类别下细粒度的子类,即分别为“哈士奇”和“爱斯基摩犬”的图像分辨开来。正因同类别物种的不同子类往往仅在耳朵形状、毛色等细微处存在差异,可谓“差之毫厘,谬以千里”。不止对计算机,对普通人来说,细粒度图像任务的难度和挑战无疑也更为巨大。

在此,本文针对近年来深度学习方面的细粒度图像分析任务,分别从“细粒度图像分类”(Fine-Grained Image Classification)和“细粒度图像检索”(Fine-Grained Image Retrieval)两大经典图像问题进行进展综述,以期读者可以对细粒度图像分析领域提纲挈领地窥得全貌。
细粒度图像分类
诚如刚才提到,细粒度物体的差异仅体现在细微之处。如何有效地对前景对象进行检测,并从中发现重要的局部区域信息,成为了细粒度图像分类算法要解决的关键问题。对细粒度分类模型,可以按照其使用的监督信息的强弱,分为“基于强监督信息的分类模型”和“基于弱监督信息的分类模型”两大类。
基于强监督信息的细粒度图像分类模型
所谓“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(Object Bounding Box)和部位标注点(Part Annotation)等额外的人工标注信息,如图2所示。
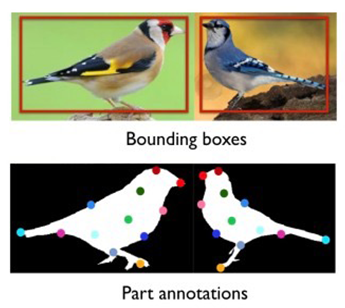
下面介绍基于强监督信息细粒度分类的几个经典模型。
Part-based R-CNN
相信大家一定对R-CNN不陌生,顾名思义,Part-based R-CNN就是利用R-CNN算法对细粒度图像进行物体级别(例如鸟类)与其局部区域(头、身体等部位)的检测,其总体流程如图3所示。
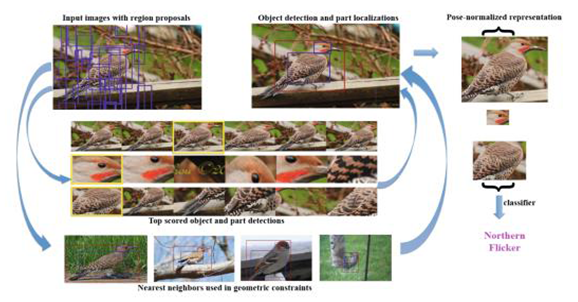
首先利用Selective Search等算法在细粒度图像中产生物体或物体部位可能出现的候选框(Object Proposal)。之后用类似于R-CNN做物体检测的流程,借助细粒度图像中的Object Bounding Box和Part Annotation可以训练出三个检测模型(Detection Model):一个对应细粒度物体级别检测;一个对应物体头部检测;另一个则对应躯干部位检测。然后,对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位,以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果(如图3右上)。接下来将得到的图像块(Image Patch)作为输入,分别训练一个CNN,则该CNN可以学习到针对该物体/部位的特征。最终将三者的全连接层特征级联(Concatenate)作为整张细粒度图像的特征表示。显然,这样的特征表示既包含全部特征(即物体
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









