








目录标题
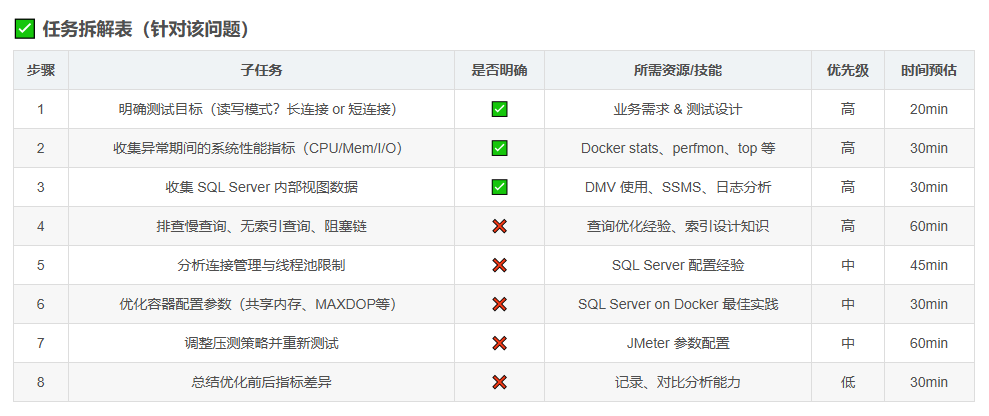
下面是 ** 任务的详细命令与说明**,参考上文中标准化的模板格式,确保在进行 MSSQL 性能测试问题排查 时,具备清晰、可操作的标准流程:
✅ 第 1 步:明确测试目标
| 子任务 | 是否明确 | 所需资源/技能 | 优先级 | 时间预估 |
|---|---|---|---|---|
| 明确压测场景(长连接 or 短连接) | ✅ | 测试工具参数理解(如 HammerDB、BenchmarkSQL) | 高 | 10min |
| 明确读写比例(只读?写多读少?) | ✅ | 业务需求文档,或 DBA/研发访谈 | 高 | 10min |
🔧 示例问题引导:
- 是模拟线上真实负载,还是测试极限写入能力?
- 单连接稳定性,还是并发下瓶颈分析?
- 是否要求事务隔离级别保持一致?
🧠 输出建议文档:
- 测试类型:如 TPS 压力测试、查询稳定性测试、性能容量测试
- 参数配置:并发连接数、事务模式、SQL 模板集、测试时间
✅ 第 2 步:收集异常期间的系统性能指标(CPU/Mem/I/O)
| 子任务 | 是否明确 | 所需资源/技能 | 优先级 | 时间预估 |
|---|---|---|---|---|
| 宿主机层资源采集 | ✅ | top、iostat、vmstat | 高 | 10min |
| 容器资源采集 | ✅ | docker stats 或 kubectl top pod | 高 | 10min |
| SQLServer 进程独立采集 | ✅ | pidstat、perfmon、ps -eo | 高 | 10min |
🔍 常用命令汇总:
1️⃣ 容器或 Pod 层级资源监控(适用于 Docker/K8s)
docker stats --no-stream
# 或 Kubernetes
kubectl top pod -n <namespace>
2️⃣ 宿主机 CPU、内存、IO 实时快照
top -b -n 1 # CPU/内存/进程负载快照
iostat -x 1 3 # IO 使用率采样
vmstat 1 5 # 内存、上下文切换、等待情况
3️⃣ 查看 SQL Server 容器进程的资源情况(找出瓶颈线程)
ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%cpu | grep sqlservr
若你用的是 systemd 架构的容器,也可尝试:
systemd-cgtop
✅ 第 3 步:收集 SQL Server 内部 DMV 数据(视图)
| 子任务 | 是否明确 | 所需资源/技能 | 优先级 | 时间预估 |
|---|---|---|---|---|
| 分析慢 SQL 和资源热点 | ✅ | DMV 查询、SSMS 工具 | 高 | 15min |
| 查看当前活跃请求 | ✅ | SSMS / SQLCMD + DMV | 高 | 5min |
| 阻塞链与事务冲突检测 | ✅ | DMV + SQL 脚本 | 高 | 10min |
🧩 具体 SQL 命令如下:
3.1️⃣ 慢 SQL 排查(执行时间 / 次数 / 消耗)
SELECT TOP 10
qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time,
qs.execution_count,
qs.total_worker_time,
qs.total_logical_reads,
st.text AS query_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
ORDER BY avg_elapsed_time DESC;
3.2️⃣ 当前活动会话和 SQL 语句
SELECT
s.session_id,
s.login_name,
r.status,
r.cpu_time,
r.total_elapsed_time,
t.text AS query_text
FROM sys.dm_exec_requests r
JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) t
WHERE s.is_user_process = 1;
3.3️⃣ 阻塞链分析(谁阻塞了谁)
SELECT
r.session_id,
r.status,
r.blocking_session_id,
r.wait_type,
t.text AS query_text
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) t
WHERE r.blocking_session_id != 0;
3.4️⃣ 缺失索引建议(是否有明显性能可提升空间)
SELECT
mid.statement AS table_name,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
migs.avg_total_user_cost,
migs.user_seeks,
migs.user_scans
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost DESC;
📌 附加建议:数据采集导出
- 使用 SSMS 可导出结果为 CSV / Excel
- 可以设置定时任务每分钟写入日志表(用于持续压测期间跟踪)
- 配合 [SQL Server Agent Job] 定时执行上述 SQL,落盘分析趋势
✅ 第 4 步:排查慢查询、无索引查询、阻塞链
🎯 目标:
找出系统瓶颈是否由 SQL 执行效率低、无索引、阻塞等问题引起。
📊 推荐使用的 DMV(动态管理视图)
| 场景 | 视图或组合 | 用途说明 |
|---|---|---|
| 慢 SQL 排查 | sys.dm_exec_query_stats + sys.dm_exec_sql_text | 查执行时间、次数、资源消耗 |
| 缺失索引分析 | sys.dm_db_missing_index_details / groups / columns | 判断是否存在未命中的索引建议 |
| 活动会话与资源消耗 | sys.dm_exec_requests + sys.dm_exec_sessions | 看当前正在执行什么 SQL,资源情况 |
| 阻塞链分析 | sys.dm_os_waiting_tasks + blocking_session_id | 识别是否因锁/事务冲突引发等待或死锁 |
| 执行计划(性能瓶颈) | sys.dm_exec_query_plan(plan_handle) | 查看是否有扫描、并行等低效执行方式 |
🧩 示例:找出当前阻塞链
SELECT
r.session_id,
r.status,
r.blocking_session_id,
r.wait_type,
t.text AS query_text
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) t
WHERE r.blocking_session_id != 0;
✅ 建议优化点:
- 慢查询集中区域:是否缺乏合适索引?
- 索引是否覆盖 SELECT 字段?能否改写为 INNER JOIN?
- 阻塞频繁 SQL 是否需要加事务隔离级别调整或拆分逻辑?
✅ 第 5 步:分析连接管理与线程池配置限制
🎯 目标:
判断是否是连接未释放、线程数不足、资源配额导致性能下降或实例异常。
📊 关键视图与配置项
| 场景 | 视图/配置项 | 用途说明 |
|---|---|---|
| 当前连接数/线程数 | sys.dm_exec_connections, dm_os_threads | 监控活跃连接与线程资源消耗 |
| 最大连接数设置 | sp_configure 'user connections' | 默认无限,需监控是否撑爆线程池 |
| 最大并发工作线程限制 | sp_configure 'max worker threads' | 默认适合大多数场景,但 CPU 数量不足时需关注 |
| 连接等待类型(资源枯竭) | wait_type = THREADPOOL, RESOURCE_SEMAPHORE | 出现频繁代表线程/内存资源不足 |
✅ 建议优化点:
- 合理设置连接池参数(JDBC/JMeter 等)
- 事务是否未及时提交导致连接堆积?
- 是否存在会话泄露:长事务+未关闭连接
✅ 第 6 步:优化容器配置参数(SQL Server + Docker)
🎯 目标:
检查并优化 Docker 容器 + SQL Server 配置项是否合理,避免资源瓶颈。
🐳 Docker / 容器建议
| 设置项 | 推荐说明 |
|---|---|
| CPU 限制 | 使用 --cpus=4 或 --cpuset-cpus 精确绑定 |
| 内存限制 | 使用 --memory=4g 限制防止 OOM |
ulimit nofile | 提升文件句柄数(默认过低会影响连接) |
⚙️ SQL Server 配置项建议
| 配置项 | 推荐说明 |
|---|---|
max degree of parallelism (MAXDOP) | 对于 OLTP 系统设置为 1~2 防止并行开销过大 |
max server memory | 限制内存使用,防止挤占系统内存(例如:设置为容器内存的 75%) |
lightweight pooling | 不建议启用,除非线程池耗尽严重 |
optimize for ad hoc workloads | 启用后避免过多计划缓存浪费资源 |
🔧 启用示例(MAXDOP)
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'max degree of parallelism', 2;
RECONFIGURE;
✅ 第 7 步:调整压测策略并重新测试
🎯 目标:
结合问题分析结果调整压测逻辑、参数与节奏,减少误报,提高可重复性。
🔁 JMeter / 其他压测优化点
| 参数项 | 建议值 | 说明 |
|---|---|---|
| 并发线程数 | 从小到大逐步放大(如 20/50/100) | 避免直接冲顶造成假故障 |
| 保持连接(KeepAlive) | 启用 + 设定连接池上限 | 防止 TCP/SQL 层连接爆炸 |
| Ramp-up 时间 | 如 30秒内启动100线程 | 缓启动观察趋势 |
| 查询/事务分批执行 | 分页+延迟控制 | 防止一次性事务量过大 |
📈 建议收集的压测结果指标
- 每分钟执行事务数 (TPS)
- 平均响应时间 / P95 响应时间
- 错误率(SQL timeout、连接中断等)
- MSSQL 相关指标:CPU, waits, disk queue, batch requests/sec
✅ 测试报告建议包含
- 测试目标(如:并发100下响应稳定<1s)
- 环境描述(CPU、内存、容器参数、SQL配置)
- 问题点(连接泄露、慢查询、阻塞、资源瓶颈)
- 优化措施列表及调整后数据对比

















 4975
4975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









