






基于深度置信网络-支持向量机(DBN-SVM)的数据分类预测
matlab代码
ID:69100643497580100
誩宝


基于深度置信网络-支持向量机(DBN-SVM)的数据分类预测是一个重要的技术领域,它在数据挖掘和机器学习中具有广泛的应用前景。深度置信网络是一种多层神经网络模型,能够通过学习数据的特征表示来进行数据分类。支持向量机是一种常用的分类算法,能够通过构建超平面来对数据进行分类。DBN-SVM结合了深度置信网络和支持向量机的优势,能够更好地处理复杂的数据分类问题。
在使用DBN-SVM进行数据分类预测时,首先需要对数据进行预处理。预处理包括数据清洗、特征选择和数据标准化等步骤。数据清洗是通过处理噪声和缺失值来提高数据的质量。特征选择是选择对分类预测有重要影响的特征。数据标准化是将数据转换为具有相同量纲的形式,以便更好地进行数据比较和分析。
在进行DBN-SVM模型训练之前,需要进行数据集的划分。通常将数据集划分为训练集和测试集两部分。训练集用于模型的训练,测试集用于评估模型的性能。划分数据集的比例根据具体问题来确定,一般可以采用70%的数据作为训练集,30%的数据作为测试集。
模型训练过程包括DBN网络的训练和支持向量机的训练两个步骤。首先,利用DBN网络对数据进行特征学习。DBN网络是一种逐层贪婪的无监督预训练方法,通过逐层训练网络来学习数据的特征表示。具体而言,DBN网络包括多个隐藏层和一个可见层,每个隐藏层都是一个RBM(受限玻尔兹曼机)。通过训练RBM来逐层学习特征表示。训练完成后,将DBN网络的隐藏层作为特征输入到支持向量机进行分类。
支持向量机的训练是通过找到一个最优的超平面来将数据进行分割。超平面的选择是通过最大化间隔来实现的,即将样本点与超平面的距离最大化。支持向量机可以处理线性可分和非线性可分问题。对于非线性可分问题,可以引入核函数将数据映射到高维特征空间中进行分类。
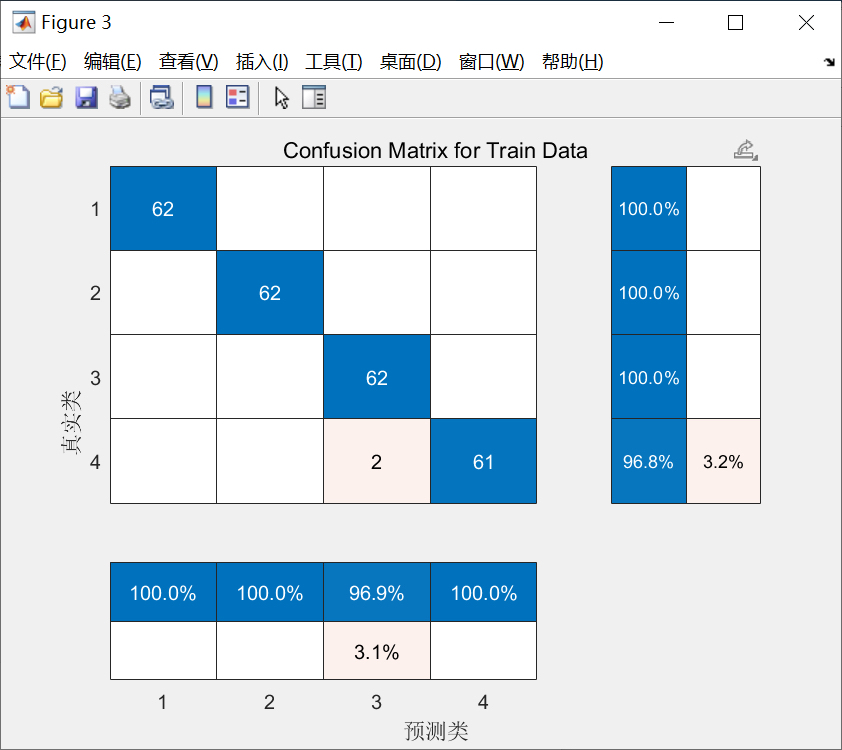
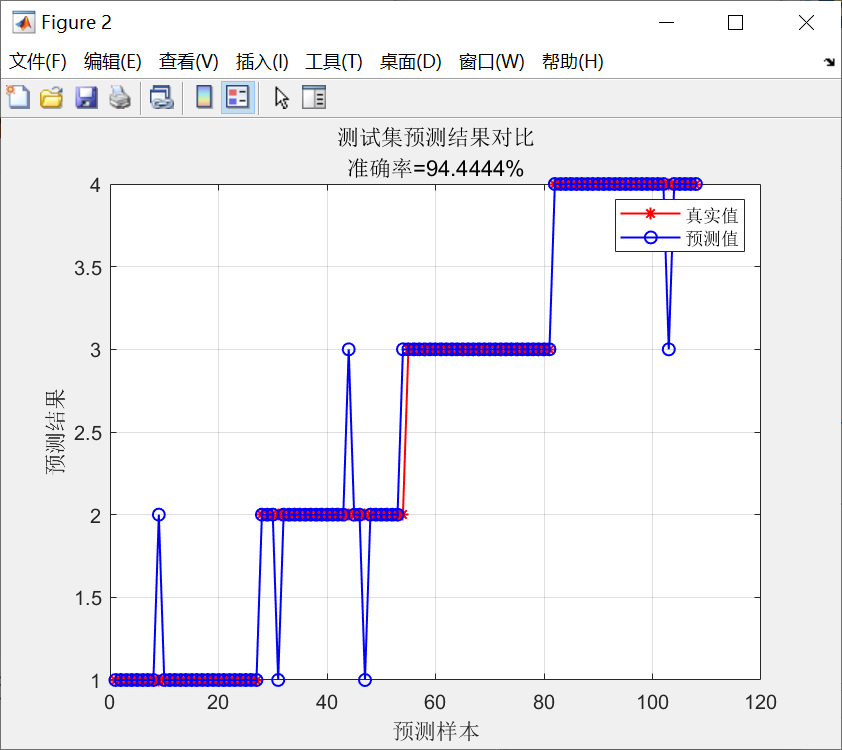
在模型训练完成后,可以使用测试集对模型进行评估。评估指标包括准确率、召回率、精确率和F1值等。准确率是指模型预测正确的样本数量占总样本数量的比例。召回率是指模型对正类样本的预测能力。精确率是指模型预测为正类的样本中真正为正类的样本比例。F1值综合考虑了精确率和召回率。
总之,基于深度置信网络-支持向量机的数据分类预测是一种有效的技术方法,能够帮助我们处理复杂的数据分类问题。通过对数据进行预处理、模型训练和模型评估,我们可以得到高准确率和高召回率的分类结果。在实际应用中,我们可以根据具体问题的需要选择合适的数据集和模型参数,以达到最佳的分类效果。
以上相关代码,程序地址:http://matup.cn/643497580100.html















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









